

翻译自:https://huggingface.co/spaces/nanotron/ultrascale-playbook
作者:nanotron
校正:pprp
GPU 深度挖掘——融合、线程化、混合
截至目前,我们的讨论主要集中在模型操作的high-level组织结构上。我们已经在不同加速器上关注了计算,同时考虑到一般内存限制和计算单元的高级调度。
但这忽略了我们可以在更低层次上通过仔细理解我们的模型操作如何在每个GPU上调度和执行来做的所有优化。
本节将深入介绍GPU架构的更多细节,特别是NVIDIA的GPU架构,但通常的想法可以在类似的加速器单元上重复使用。
在覆盖Flash-Attention革命如何有效调度GPU工作负载之前,我们将简要解释GPU的组织方式,并最终解释如何在GPU上有效使用各种精度。
GPU入门
通常,GPU 具有非常层次化的组织结构。在本指南中,我们将保持讨论在支撑我们后续展示所需的概念层面。
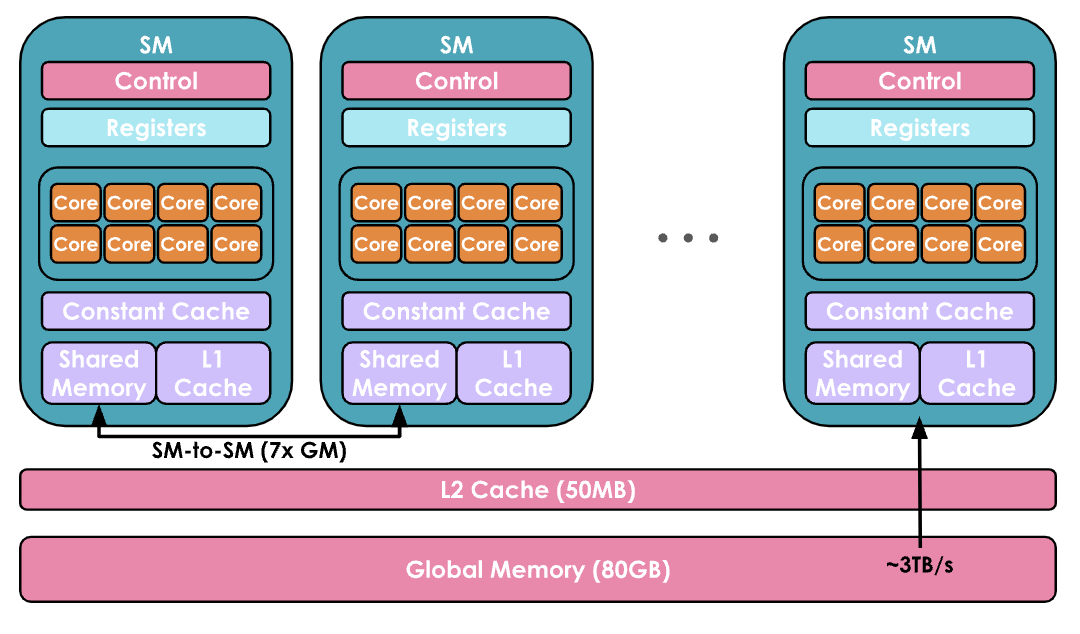
(1)在计算方面,GPU由一组称为流多处理器 Streaming Multiprocessors(SM)的计算单元组成并控制。每个SM包含并控制一组流处理器,也称为核心 Cores。例如,Nvidia H100 GPU具有132个SM,每个SM有128个核心,总共有16,896个核心(有关张量核心的详细信息,请参见张量核心文档[1]),每个核心可以同时处理多个线程 Thread。
编者注:计算分层概念: SM → Core → Thread 实际编程概念:SM → Grid → Block → Thread Warps(线程束)→ Thread
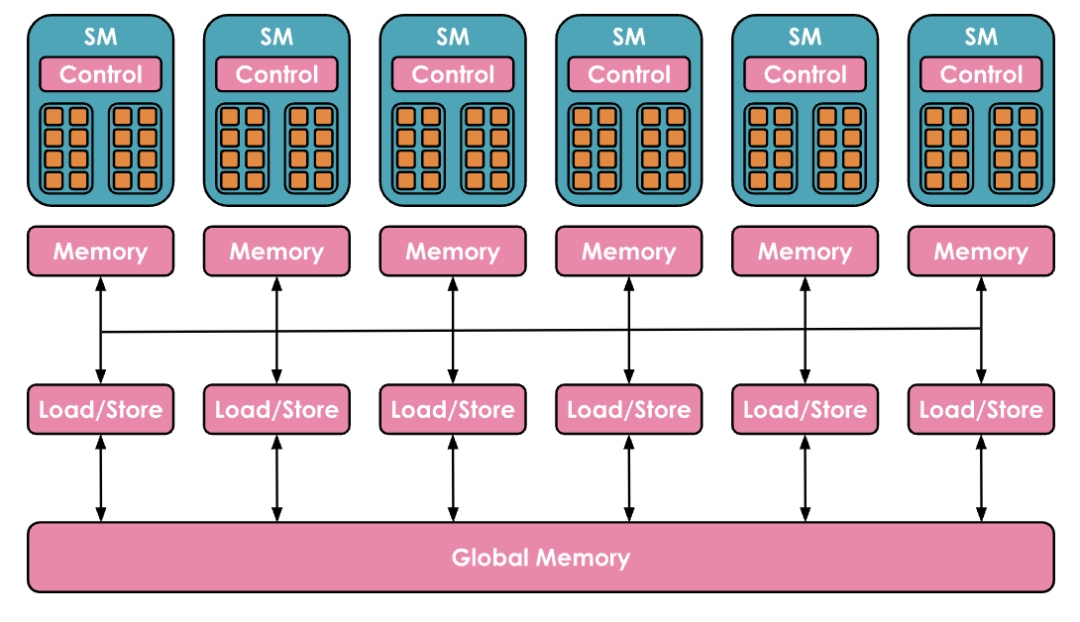
(2)内存方面也高度分层,具有多层缓存和内存:寄存器 Registers 是最小的单位,在执行过程中是私有的,共享内存 Shared Memory 和 L1 Cache在单个SM上运行的线程之间共享,更高层次是所有SM共享的L2缓存 Cache,最后是全局内存 Global Memory,这是GPU上最大的内存(例如H100的80GB),但访问和查询速度也是最慢的。
编者注:内存分层:Global Mem → L2 Cache → L1 Cache → Shared Mem
GPU的目标是通过利用计算/内存的这种分层组织,尽可能并行地在GPU核心上运行尽可能多的工作负载。
在GPU核心上运行的代码片段称为内核 Kernel。它可以在高级别上用 CUDA或Triton等语言编写,然后编译为NVIDIA GPU使用的低级汇编 Parallel Thread Execution(PTX)。
要运行内核,你还需要一个特定的代码部分,称为主机代码 Host Code,它在CPU/主机上执行,并负责准备数据分配和加载数据和代码。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line// Host codevoid vecAdd(float* h_A, float *h_B, float *h_c, int n) {// Allocate vectors in device memoryint size = n * sizeof(float);float *d_A, *d_B, *d_C;cudaMalloc(&d_A, size);cudaMalloc(&d_B, size);cudaMalloc(&d_C, size);// Copy vectors from host memory to device memorycudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);// Invoke kernelint threadsPerBlock = 256;int blocksPerGrid =(N + threadsPerBlock - 1) / threadsPerBlock;VecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);// Copy result from device memory to host memory// h_C contains the result in host memorycudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);// Free device memorycudaFree(d_A);cudaFree(d_B);cudaFree(d_C);}
内核通常按如下方式调度:
-
线程被分组成大小为32的线程束(warps)。线程束中的所有线程被同步以同时执行指令,但在数据的不同部分上。 -
线程束被分组成更大的块(blocks),大小更灵活(例如大小为256),每个块仍然分配给单个SM。一个SM可以并行运行多个块,但是根据资源情况,并非所有块都会立即分配执行,有些可能会等待资源。
从这些细节中最重要的是记住,有各种大小和分配约束(各种内存的大小,每个线程束和块中的线程数),需要考虑使用GPU架构的最有效方式。
大多数情况下,你不需要这么精确,幸运的是,你可以重用社区其他成员准备的内核和代码。但无论如何,我们希望为你提供有关如何开始使用内核的入门指南!
How to improve performance with Kernels ?
如果你想添加一个缺少优化过的内核的新操作或加快现有的 PyTorch 函数,从头编写内核可能看起来是最直接的方法。然而,从头创建高性能的 CUDA 内核需要丰富的经验和陡峭的学习曲线。通常,更好的入门方法是利用 torch.compile ,它通过捕获你的操作并在 triton 中生成低级、高性能内核来动态优化 PyTorch 代码。
假设你想编写一个名为指数线性单元 ELU 的激活函数的内核:
你可以从一个简单的 PyTorch 实现开始,然后只需在顶部添加 @torch.compile 装饰器即可:
ounter(lineounter(lineounter(line@torch.compiledef elu(x, alpha=1.0):return torch.where(x < 0, alpha * (torch.exp(x) - 1), x)
编译版和非编译版之间的区别非常明显,尤其是在只添加了一个装饰器的情况下。这种显著的不同在下图中得到了体现(N 表示列数):
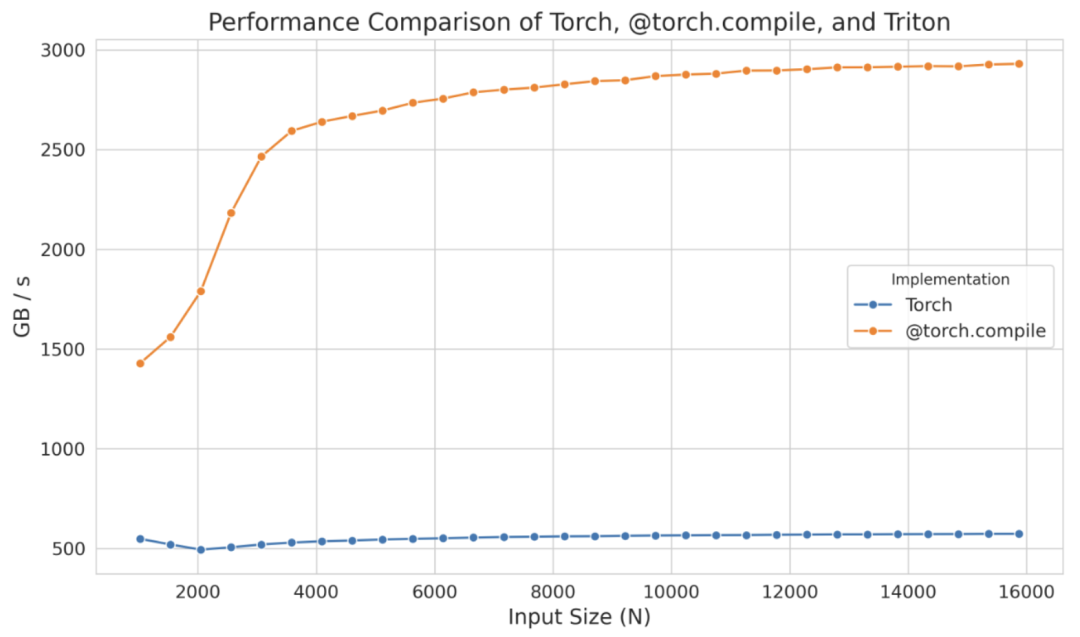
然而,如果这种性能提升不足,你可以考虑实现 Triton 内核。作为一个起点,你可以查看由@torch.compile 生成的 triton 内核。为此,你只需设置环境变量 TORCH_LOGS 为 "output_code" :
ounter(lineexport TORCH_LOGS="output_code"
一旦运行带有 @torch.compile 装饰器的 Python 脚本,它将生成并输出相应的 Triton 内核,在这种情况下,是:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line@triton.jitdef triton_(in_ptr0, out_ptr0, xnumel, XBLOCK : tl.constexpr):xnumel = 100000000xoffset = tl.program_id(0) * XBLOCKxindex = xoffset + tl.arange(0, XBLOCK)[:]xmask = xindex < xnumelx0 = xindextmp0 = tl.load(in_ptr0 + (x0), xmask)tmp1 = 0.0tmp2 = tmp0 < tmp1tmp3 = tl_math.exp(tmp0)tmp4 = 1.0tmp5 = tmp3 - tmp4tmp6 = tl.where(tmp2, tmp5, tmp0)tl.store(out_ptr0 + (x0), tmp6, xmask)
为了提高可读性,我们可以修改变量名,添加注释,并进行轻微调整(或者请求LLM为我们完成),如下所示:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line@triton.jitdef elu_kernel(input_ptr, output_ptr, num_elements, BLOCK_SIZE: tl.constexpr):# Calculate the starting index for this blockblock_start = tl.program_id(0) * BLOCK_SIZE# Create an array of indices for this blockblock_indices = block_start + tl.arange(0, BLOCK_SIZE)[:]# Create a mask to ensure only valid indices are processedvalid_mask = block_indices < num_elements# Load input values from the input pointer based on valid indicesinput_values = tl.load(input_ptr + block_indices, valid_mask)# Define the ELU parameterszero_value = 0.0 # Threshold for ELU activationnegative_mask = input_values < zero_valueexp_values = tl.math.exp(input_values)# Define the ELU output shiftone_value = 1.0shifted_exp_values = exp_values - one_valueoutput_values = tl.where(negative_mask, shifted_exp_values, input_values)# Store the computed output values back to the output pointertl.store(output_ptr + block_indices, output_values, valid_mask)
此处, tl.program_id(0) 提供一个唯一的 Block ID,我们用它来确定该块将处理哪个数据部分。使用此 Block ID, block_start 计算每个块的起始索引,而 block_indices 指定该部分内的索引范围。 valid_mask 确保仅处理 num_elements 内的索引,安全地使用 tl.load 加载数据。然后应用 ELU 函数,根据数值是否为负修改值,并将结果使用 tl.store 写回内存。
当使用 triton.testing.Benchmark 对生成的内核进行基准测试时,其性能如下:
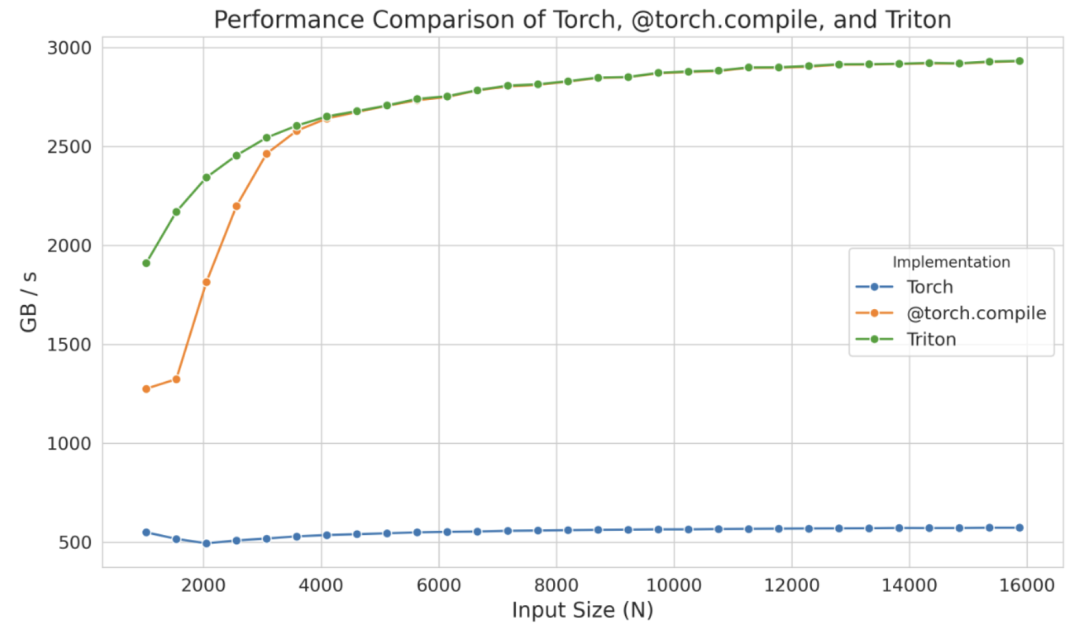
这个独立的内核在较小规模下甚至表现出比 @torch.compile 更优的性能,但这可能仅仅是 torch.compile 的编译时间影响所致。无论如何,与其从零开始,不如从这些生成的内核出发,并将精力集中在优化其性能上,从而节省大量时间。
即使在 Triton 中,有时也无法完全达到设备的峰值性能,因为该语言在处理共享内存和流多处理器(SMs)内的调度等低级细节方面存在限制。Triton 的能力仅限于块及其在 SMs 之间的调度。为了获得更深入的控制,你需要直接在 CUDA 中实现内核,在那里你将能够访问所有底层低级细节。
CUDA 方面,可以采用各种技术来提高内核的效率。这里仅介绍其中几个:优化内存访问模式以降低延迟、使用共享内存存储频繁访问的数据以及管理线程工作负载以最小化空闲时间。
在深入 CUDA 示例之前,总结一下看到的工具,这些工具使我们能够编写内核代码以在 GPU 上执行指令:
-
PyTorch:简单但速度较慢 -
torch.compile:简单且速度快,但灵活性不足 -
Triton:更难,但更快、更灵活 -
CUDA:最难,但最快、最灵活(如果掌握得当)
下面讨论 CUDA 中最常见的优化技术之一:优化内存访问。GPU 的全局内存(在前面的图表中是最大的内存)相比缓存来说,延迟较高,带宽较低,这通常是大多数应用程序的主要瓶颈。高效地访问全局内存的数据可以极大地提高性能。
内存合并
为了有效利用全局内存的带宽,理解其架构至关重要。在CUDA设备中,全局内存是使用DRAM实现的。
内存归约(Memory coalescing)利用 DRAM 在访问内存地址时以突发或连续内存位置范围的形式提供数据的特点。每次访问 DRAM 位置时,包括请求的位置在内的连续位置序列由 DRAM 芯片中的多个传感器并行读取。一旦读取,这些数据可以快速传输到处理器。在 CUDA 中,归约 coalescing 利用这种突发行为,通过确保 warp 中的线程(32 个执行相同指令的线程,SIMD)访问连续的内存位置,以最大化内存访问效率。
例如,如果线程 0 访问位置 M,线程 1 访问 M + 1,线程 2 访问 M + 2,依此类推,GPU 硬件将这些请求归约或合并为一个大型、高效的 DRAM 突发访问请求,而不是单独处理每个访问。
以矩阵乘法为例。一个简单直接的实现方式是,每个线程计算输出矩阵的一个元素,如下:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line__global__ void matmul_naive(int M, int N, int K, const float *A, const float *B, float *C) {const uint x = blockIdx.x * blockDim.x + threadIdx.x;const uint y = blockIdx.y * blockDim.y + threadIdx.y;if (x < M && y < N) {float tmp = 0.0;for (int i = 0; i < K; ++i) {tmp += A[x * K + i] * B[i * N + y];}C[x * N + y] = tmp;}}
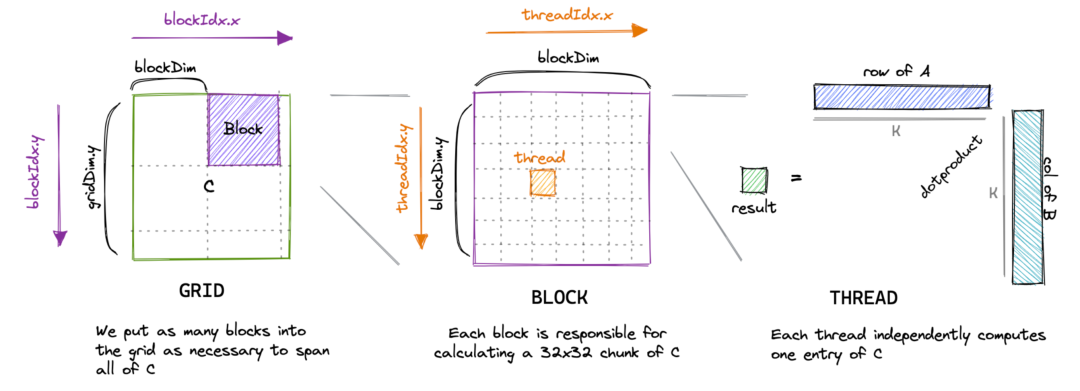
这是一篇精彩博客文章[2]中内核的优秀可视化:
然而,当使用类似 ncu 的工具对内核进行性能分析时,可以看到问题,包括低内存吞吐量和未归约的内存访问。

原因在于,在此内核中,同一块中的两个线程(线程 ID 为 (0, 0) 和 (1, 0),最终将位于同一 warp 中)将同时从矩阵 B 的同一列加载,但矩阵 A 的不同行。由于矩阵元素按行主序存储(意味着行元素位于连续的内存地址中,如图所示),线程 (0, 0) 将在第一次迭代 中加载 ,而线程 (1, 0) 将加载 。这些元素在内存中并不相邻,这种错位将在每次迭代中存在,从而防止内存访问归约。
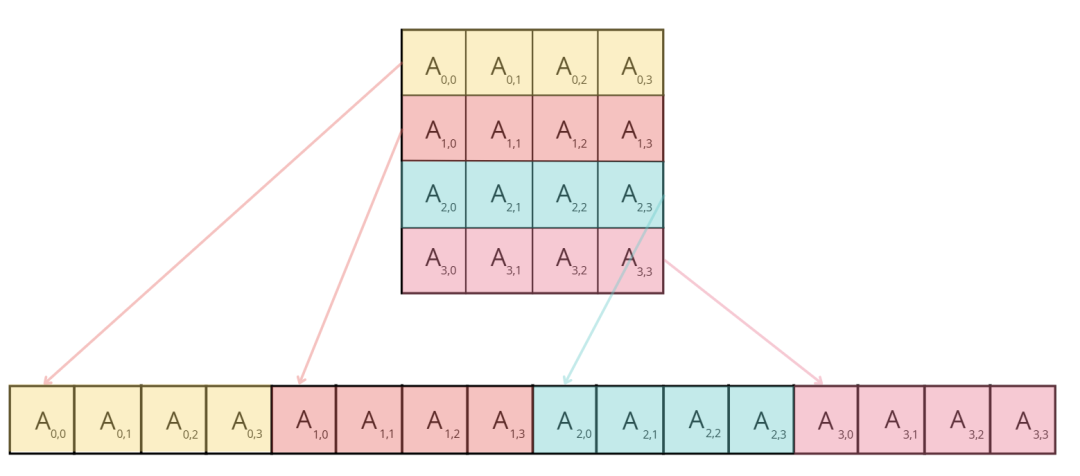
为了提高我们内核的性能,我们可以改变坐标 x 和 y 的计算方式,如下所示:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineconst int x = blockIdx.x * BLOCKSIZE + (threadIdx.x / BLOCKSIZE);const int y = blockIdx.y * BLOCKSIZE + (threadIdx.x % BLOCKSIZE);if (x < M && y < N) {float tmp = 0.0;for (int i = 0; i < K; ++i) {tmp += A[x * K + i] * B[i * N + y];}C[x * N + y] = tmp;}
而不是使用二维块,我们切换到一维块,并重新定义确定 x 和 y 值的方法。在这种新方法中,同一 warp(具有接近的 threadIdx.x 值)内的线程将共享相同的 x 值,但具有不同的 y 值。这意味着它们将加载矩阵 A 的同一行,但矩阵 B 的不同列。因此,可以合并行主序矩阵的内存访问。
当我们对新的内核进行性能分析时,注意到关于未归约内存访问的警告已经消失,GPU 的内存吞吐量大约提高了 10 倍。

内核的执行时间降低了 10 倍!惊人。
现在让我们介绍另一种在文献中经常提到的技术:分块Tiling。
分块处理(Tiling)
分块处理是一种利用 共享内存 Shared Memory 优化内存访问模式的技术。正如我们前面提到的,共享内存是一种小而快速的存储,块内的所有线程都可以访问它。这使得数据可以被多个线程重复使用,从而减少了从较慢的全局内存中重复加载数据的需求。
以矩阵乘法为例,块中的每个线程可能需要从两个矩阵(如 A 和 B)中获取元素。如果每个线程独立地从全局内存加载所需的行和列,就会出现大量冗余加载,因为块中的多个线程会访问重叠的数据。相反,我们可以使用分块处理 Tiling,将 A 和 B 的一个块(或 Tile)一次性加载到共享内存中,让该块中的所有线程重复使用相同的共享数据。
在分块处理的方法中,每次迭代时,块内的所有线程协同工作,将两个 Tile(一个来自矩阵 A,另一个来自矩阵 B)加载到共享内存中。具体来说,线程加载矩阵 A 的一个Tile(大小为 BLOCK_SIZE_M × BLOCK_SIZE_K)以及矩阵 B 的一个Tile(大小为 BLOCK_SIZE_K × BLOCK_SIZE_N)。一旦这些Tile存入共享内存,线程就可以在这些Tile上执行矩阵乘法,从而实现高效计算,因为所有必要的数据都可以被快速访问。Tile乘法的结果存储在一个累积矩阵中,该矩阵保存中间结果。在每次迭代后,当前Tile乘法的结果都会累加到该矩阵中,直到两个矩阵的所有Tile都被处理完毕。

让我们来看看实现中的关键部分:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line// Set pointers to the starting elementsA += blockRow * TILE_SIZE * K; // Start at row = blockRow, column = 0B += blockCol * TILE_SIZE; // Start at row = 0, column = blockColC += blockRow * TILE_SIZE * N + blockCol * TILE_SIZE; // Start at row = blockRow, column = blockColfloat sum = 0.0;// The outer loop moves through tiles of A (across columns) and B (down rows)for (int tileIdx = 0; tileIdx < K; tileIdx += TILE_SIZE) {sharedA[localRow * TILE_SIZE + localCol] = A[localRow * K + localCol];sharedB[localRow * TILE_SIZE + localCol] = B[localRow * N + localCol];// Ensure all threads in the block have completed data loading__syncthreads();// Shift pointers to the next tileA += TILE_SIZE;B += TILE_SIZE * N;// Compute the partial dot product for this tilefor (int i = 0; i < TILE_SIZE; ++i) {sum += sharedA[localRow * TILE_SIZE + i] * sharedB[i * TILE_SIZE + localCol];}// Synchronize again to prevent any thread from loading new data// into shared memory before others have completed their calculations__syncthreads();}C[localRow * N + localCol] = sum;
每个线程首先从矩阵 A和矩阵 B中加载一个元素到共享内存。在这种情况下,实现合并内存访问(coalesced memory access)非常直观:通过将 threadIdx.x 作为局部列索引(localCol),同一个 warp 中的线程可以访问相邻的矩阵元素。块内所有线程完成数据加载后(通过调用 __syncthreads() 确保同步),它们就会计算这两个Tile的点积。当所有Tile遍历完成——矩阵 A 在水平方向移动,矩阵 B 在垂直方向移动——最终计算出的结果存入矩阵 C的对应位置。
当我们使用 ncu 对这个内核进行基准测试时,我们发现内存吞吐量增加到了 410 Gb/s,内核执行时间减少了约 43%,实现了约 6.6 TFLOPs 的性能。
线程粗化(Thread Coarsening)
分块处理技术显著提高了我们内核的性能。但是,当分析量化每个状态中花费的周期的warp状态时,我们观察到以下情况:
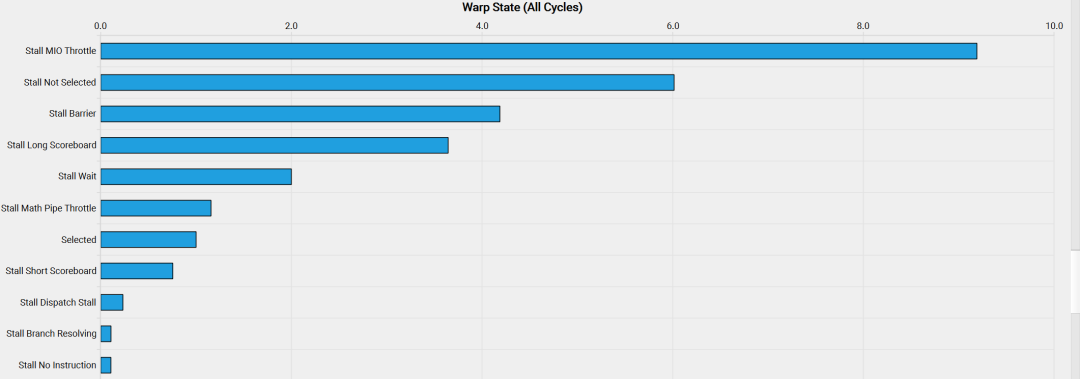
这些神秘状态名称的含义可以在NVidia的性能指南[3]中找到,在Warp Stall Reasons部分可以阅读到:
*"smsp__pcsamp_warps_issue_stalled_mio_throttle: 等待MIO(内存输入/输出)指令队列不再满的Warp被停顿。在MIO管道(包括特殊数学指令、动态分支以及共享内存指令)极端利用的情况下,此停顿原因较高。当由共享内存访问引起时,尝试使用更少但更宽的加载可以减少管道压力。*
所以看起来Warp正在等待共享内存访问返回!为了解决这个问题,我们可以应用一种称为 线程粗化 Thread Coarsening 的技术,该技术涉及将多个线程合并为一个粗化线程。这将显著减少共享内存访问,因为每个粗化线程可以处理多个输出元素。
在写入或改进自定义内核时,一个最重要的考虑因素:最小化控制分歧 Minimizing Control Divergence。
最小化控制分歧
流多处理器(SM)被设计为使用单指令多数据(SIMD)模型执行 warp 中的所有线程。这意味着在任何给定时刻,一个指令同时为warp中的所有线程获取和执行。当执行warp时,其中的线程在数据的不同段上操作,但遵循相同的指令,因此得名单指令多数据。SIMD的主要优势在于其效率;负责指令获取和调度的控制硬件在多个执行单元之间共享。这种设计最小化了与控制功能相关的硬件开销,使得更大比例的硬件专注于提高算术吞吐量。
当warp内的线程采取不同的执行路径时,就会发生控制分歧。例如,如果条件语句(如if语句)导致一些线程执行一个代码块,而其他线程执行另一个代码块,那么warp必须串行执行这些执行,导致空闲线程等待其他线程完成。为了最小化控制分歧,我们需要设计内核,**确保warp内的线程遵循相同的执行路径。这可以通过重构代码以减少分支、**使用确保所有线程遵循类似执行路径的数据结构,或使用预测等技术来实现。
编者注:简单理解为不要有if等判断语句
我们已经介绍了写入自定义内核和改进GPU操作性能和内存占用的一些主要考虑因素。但在转向实际示例之前,还有一个重要的概念需要讨论:“融合内核 Fused Kernel”。
融合内核(Fused Kernels)
之前提到GPU和CPU操作可以异步进行。特别是,CPU上的 Host Code 主机代码可以以非阻塞方式调度GPU的工作负载。
非阻塞对于重叠通信和计算非常有用——可以扩展到更一般的想法,即尽量避免来回在主机和GPU内核命令之间切换。
这个想法在 Horace He [4] 的这些图中得到了很好的诠释:
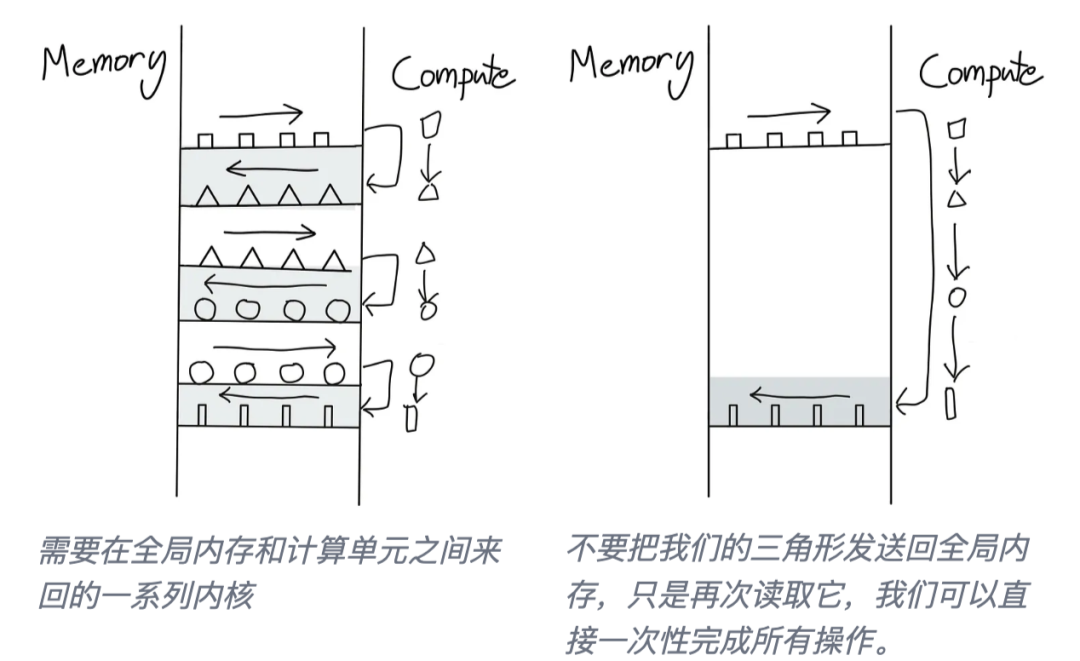
如何避免这种来回?最好的办法是尽可能让我们的 GPU 实现自主。这通过将尽可能多的连续计算操作打包在一个单独的内核中来实现,这个内核被称为“融合内核 Fused Kernel”。
融合内核对于独立于彼此在各个输入Tokens上执行的一系列点状操作特别高效且易于编写。在这种情况下,在将计算值移动到 SM 内存并启动新内核之前,没有必要将计算值返回到全局内存。在完成计算序列之前,将所有值保留在本地要高效得多。
Transformer 模型中有许多地方可以应用这种“融合”方法:每次我们遇到一系列逐点point-wise操作,例如在层归一化计算中。
现在我们已经掌握了欣赏内核工程的真正杰作所必需的所有理解:Flash Attention
Flash Attention 1-3
Flash attention是由Tri Dao [5] 引入,并提出通过编写自定义CUDA内核来优化注意力计算,使其更快且更内存高效。Flash Attention的核心思想是充分利用GPU的各种内存,避免过度依赖最慢的内存之一:GPU的全局内存。
编者注: 在Flash attention中,HBM – 高带宽内存 High band Memory 就是GPU全局内存。
注意机制的基本实现涉及在内存和worker之间进行大量传输。它要求在HBM中实现S和P矩阵,这意味着结果需要发送到HBM,然后再次发送到SRAM进行下一步计算:

由于HBM的带宽较低,这在注意力计算中引入了严重的瓶颈。关键元素是将S矩阵计算成可以适应SM较小共享内存的小块。但可以做得更好,不仅仅是分块计算S矩阵,而是完全避免存储庞大的S矩阵,仅保留计算Softmax归一化因子所需的统计信息。这样,可以直接在SRAM中一次性计算部分 O,而无需在中间结果之间来回传输数据。这不仅利用了共享内存,还消除了由于存储注意力矩阵(在长上下文长度下是模型中最大的激活矩阵之一)而导致的内存瓶颈。
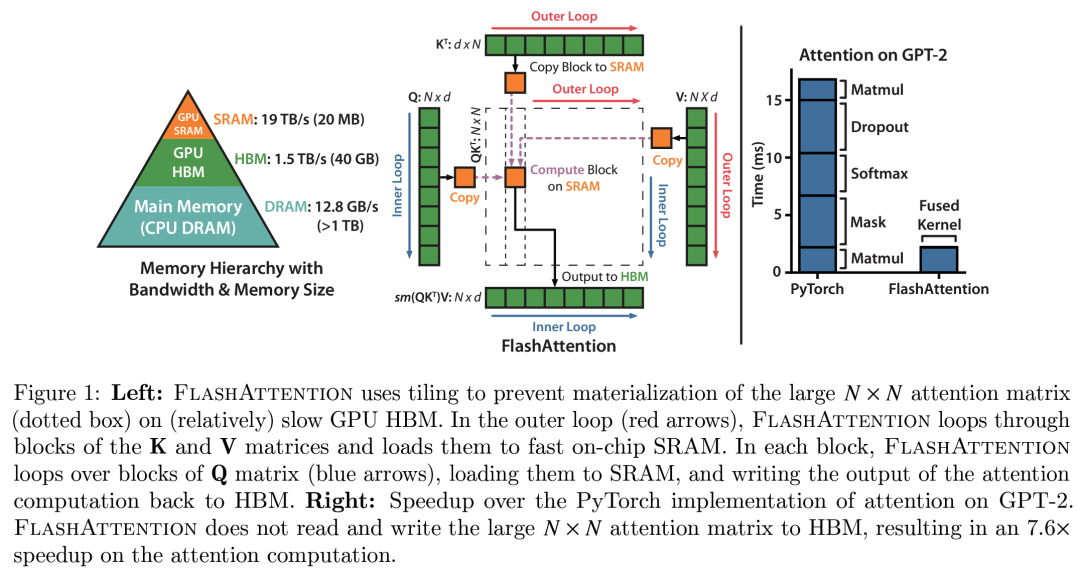
Flash Attention 的理念解决了模型训练中的众多瓶颈,因此迅速成为所有Transformer模型执行注意力计算的默认方法:
-
通过避免存储S矩阵,降低了注意力计算的内存负担 -
消除了大部分注意力计算的平方复杂度(S²)所带来的影响
因此,自Transformer架构发明后不久发展出的所有线性注意力变体和次二次近似注意力方法大多被搁置,取而代之的是这种精准且快速的Flash Attention实现和机制。
在Flash Attention 1发布之后,同一实验室相继推出了两个改进版本:Flash Attention 2 和 3。与Flash Attention 1相比,Flash Attention 2 和 3 的改进更多体现在对GPU的底层优化,而不是对注意力机制本身的改动。具体来说:
-
减少非矩阵乘法(matmul)操作的数量 -
精细划分计算任务至warp和线程块(适用于Flash Attention 2) -
在最新的Hopper架构(H100)上优化FP8和Tensor Core的支持(适用于Flash Attention 3)
Flash Attention 是一个典型案例,展示了当深入考虑当前GPU加速器的内存/计算设计时,所能带来的突破性改进。
到目前为止,我们讨论的算子融合技术要求对模型代码进行改动,并为特定操作编写自定义内核,以加速训练。
在计算操作的底层优化的最后部分,我们将探索一系列与模型代码无关的方法,这些方法适用于任何模型,并且已经成为业界标准:混合精度训练(Mixed Precision Training)!
混合精度训练(Mixed Precision Training)
在本书的多个章节中,我们讨论了低精度数值格式及其对存储激活值、参数和优化器状态的内存需求的影响。现在,我们将深入了解这些格式的细节,并更好地理解它们的权衡、优势和局限性。
顾名思义,混合精度训练涉及在训练过程中混合使用不同的数值精度。PyTorch张量的默认数值精度是单精度浮点格式,即FP32(float32),这意味着每个存储的数值占用32位(4字节)。这些位被分为三个部分:
-
符号位(Sign):第一个比特决定数值是正数还是负数 -
尾数(Mantissa):决定数值的有效数字 -
指数(Exponent):控制数值的数量级
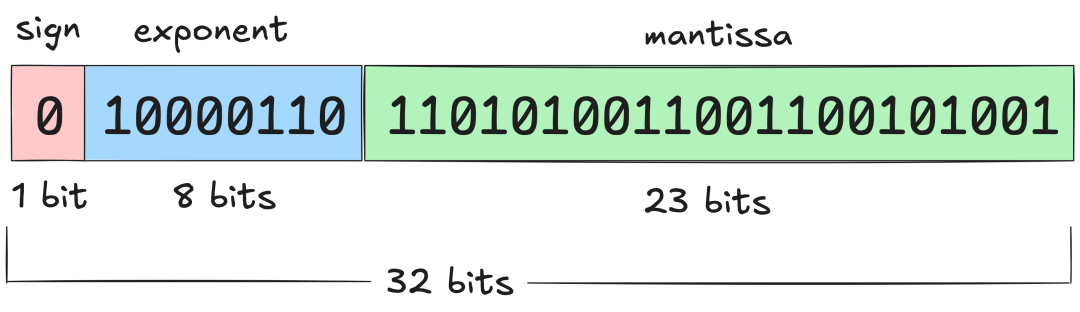
浮点数的基本原理可以通过科学计数法轻松理解,例如−5.734× ,其中首先是符号位,然后是尾数和指数。这样可以在广泛的数值范围内以自适应精度表示数值。虽然float32是默认格式,但PyTorch还支持多种浮点格式:
| 格式 | 总位数 | 符号位 | 指数位 | 尾数位 |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
减少总位数并非没有代价(这里也没有免费午餐),但可以控制如何付出代价。我们可以在尾数或指数上牺牲更多位数。因此,也存在两种float8格式,根据指数和尾数命名,灵活选择最合适的格式。我们可以查看每种格式的可能数值范围:
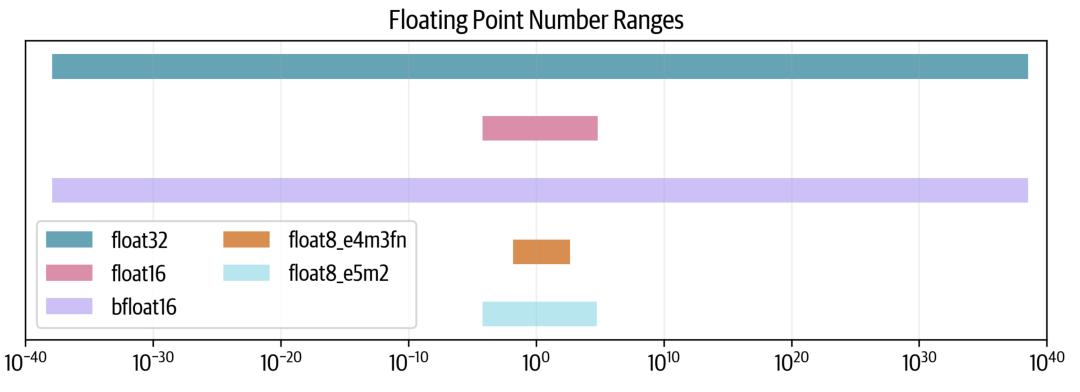
我们可以看到,float32跨越80个数量级,而float16牺牲了很多范围,而bfloat16保持了完整的范围。两种float8格式进一步减少了范围,其中e5e2可以维持float16的范围,而e4m3的范围更小。
为什么有些格式能够保持范围,而其他格式则不能?让我们通过在 1 和 2 之间绘制 10,000 个点来查看分辨率 resolution。每个点将根据每种格式四舍五入到最接近的可表示数字。
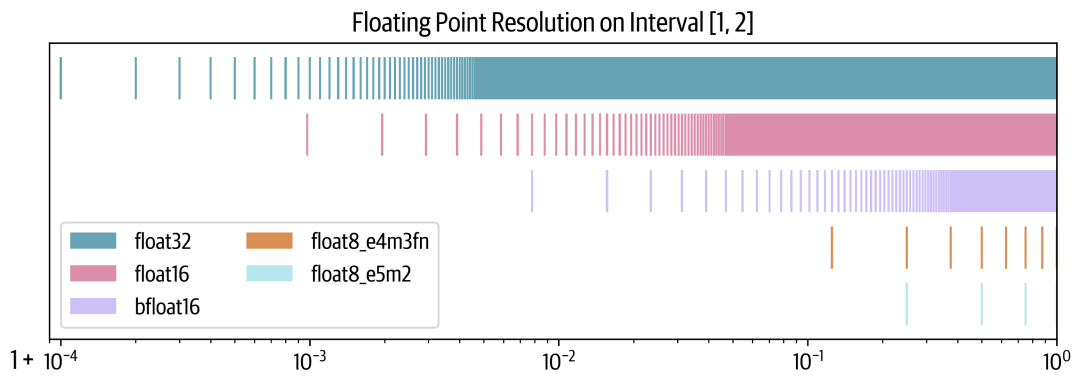
我们可以看到,bfloat16通过牺牲更多精度来维持float32的范围,但这是有代价的。在float8的情况下,情况更为严峻,因为e4m3在区间1-2内只能表示7个数字,而e5m2只能表示3个数字。
衡量格式分辨率的常见指标是epsilon:即1.00后的第一个可表示的数字。可以看到,对于float32格式, 是一个上界(实际上是 )。对于float16,它是 ,而对于bfloat16,则是其10倍。
混合精度训练的理念是使用其中一些较低精度格式,同时保持全精度训练的性能。
事实证明,我们不能完全放弃float32,并且通常需要保持一些部分以全精度进行训练。这就是为什么较低精度训练通常被称为***混合精度***训练。
现在来看看使用16位进行模型训练,然后看看能否进一步降至8位。
FP16和BF16训练
简单地将所有张量和操作切换到float16通常不起作用,结果通常是发散的损失。然而,原始的混合精度训练论文 [6] 提出了三种技巧来匹配float32训练:
-
FP32权重复制:float16权重可能会出现两个问题。在训练期间,某些权重可能变得非常小,并且会被舍入为0。但即使权重本身不接近零,如果更新非常小,其数量级的差异可能会导致在加法过程中权重下溢。一旦权重为零,它们将在训练的其余过程中保持为零,因为再也没有梯度信号传递过来了。 -
损失缩放:梯度也存在类似的问题,因为梯度往往远小于1,因此有可能下溢。一个简单而有效的策略是在反向传播之前对损失进行缩放,在反向传播之后取消缩放梯度。这确保在反向传播过程中没有下溢,并且在进一步处理梯度(例如剪裁)和优化步骤之前取消缩放,不影响训练。 -
累积:最后,在16位精度下执行某些算术运算(如平均值或求和)时,也可能面临下溢或上溢的问题。一种解决方案是在操作过程中累积中间结果到float32,并仅在最后将最终结果转换回16位精度。
通过这些技术,可以实现稳定的训练,同时由于更快的低精度算术运算,获得更高的吞吐量。当然,你可能会问:我们是否可以比16位精度更进一步、更快?也许可以!
FP8预训练
即使完全重叠了通信与计算,我们总会遇到硬件本身的底层理论FLOPS限制,即硬件上每个操作的效率。这就是数值精度变得至关重要的地方。例如,在NVIDIA的H100 GPU上,FP8矩阵乘法(GEMM操作)的效率达到bfloat16的两倍,使得低精度训练进一步有吸引力。最近的研究,包括FP8-LM [7], torchao [8],以及DeepSeek-V3 [9],展示了FP8训练在大规模模型中的潜力。然而,FP8预训练引入了一个重大挑战:稳定性。在低精度下,数值不稳定往往导致损失发散,难以达到高精度训练的准确性。
我们知道,对于固定模型大小,随着学习率的提高,不稳定性会增加[10],使得FP8预训练尤为棘手。以下是FP8训练通常发散损失曲线的示例:
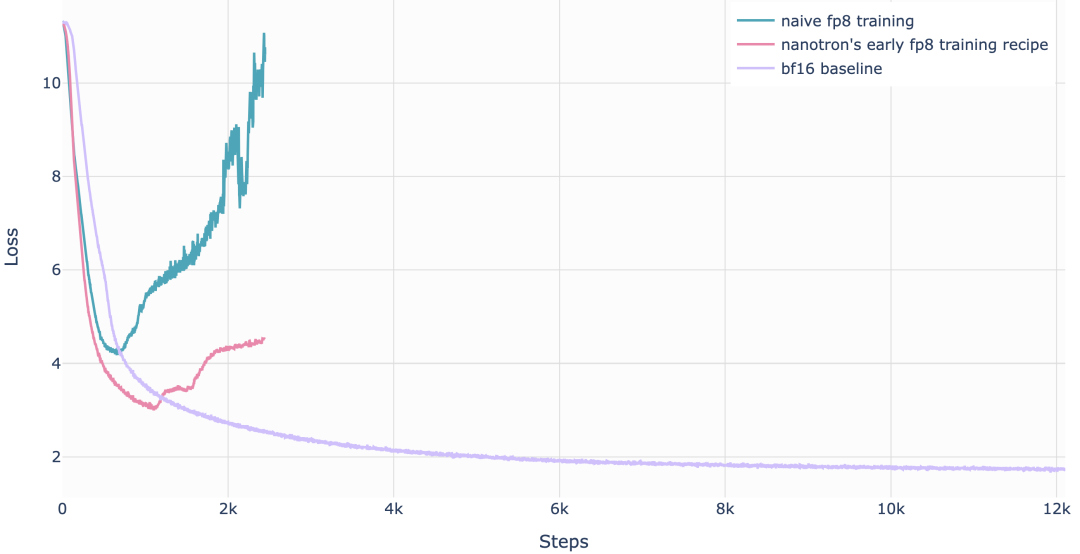
首次成功的大规模FP8混合精度训练在DeepSeek-V3上被公开报道。研究人员仔细分析了前向传播(Fprop)以及激活(Dgrad)和权重(Wgrad)反向传播的每个操作。类似于BF16混合精度训练,一些聚合计算和主权重仍然保持高精度,而实际的运算则在FP8中执行。
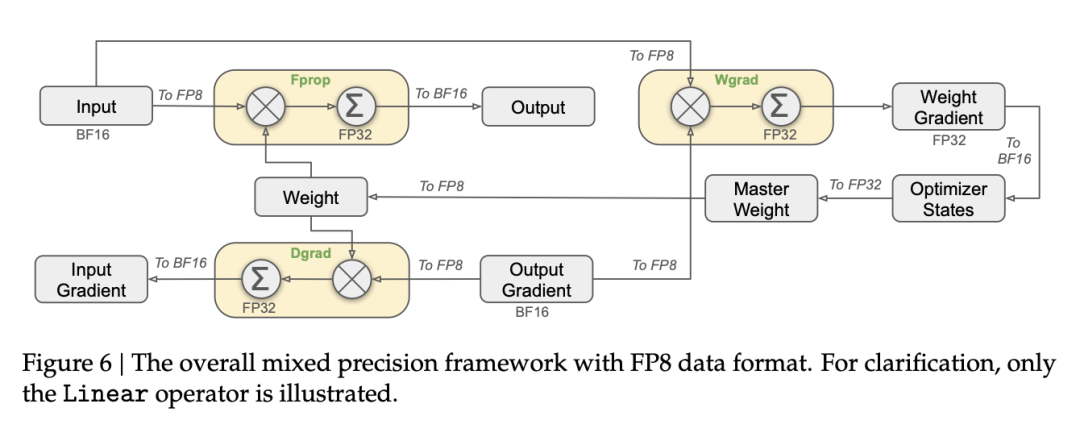
为了从高精度(如FP32或BF16)切换到更低精度(如FP16或FP8)并适应更小的数值范围,需要对激活值的范围进行归一化,例如计算其绝对最大值。DeepSeek-V3进一步引入了一种特定的量化方案,其中范围按块(tile)归一化:输入/激活使用1×128,权重和缩放因子使用128×128。这种方法使归一化过程不易受到激活值中异常值的影响。此外,他们还提出了一些额外的技巧,以进一步减少内存和通信开销,具体内容可以在DeepSeek-V3技术报告的第3.3节中找到。以下是一些已知的FP8训练方法的总结:
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
总体而言,在2025年初,FP8仍然是一种实验性技术,相关方法仍在不断发展。鉴于其明显的优势,它很可能很快成为标准,并取代bf16混合精度训练。想要了解FP8训练技术的开源实现,可以查看nanotron的实现[11]。
展望未来,下一代NVIDIA Blackwell芯片也宣布将支持FP4训练,这将进一步加速训练,但无疑也会带来新的训练稳定性挑战。
结论
恭喜你,亲爱的读者,你坚持到了最后!我们完成了一次精彩的旅程:从理解如何在单个GPU上训练简单模型,到掌握在数千个GPU上高效训练Llama-405B和DeepSeek-V3等大规模语言模型的复杂技术。现在,你应该能够相对轻松地理解Llama-3的4D并行架构图:
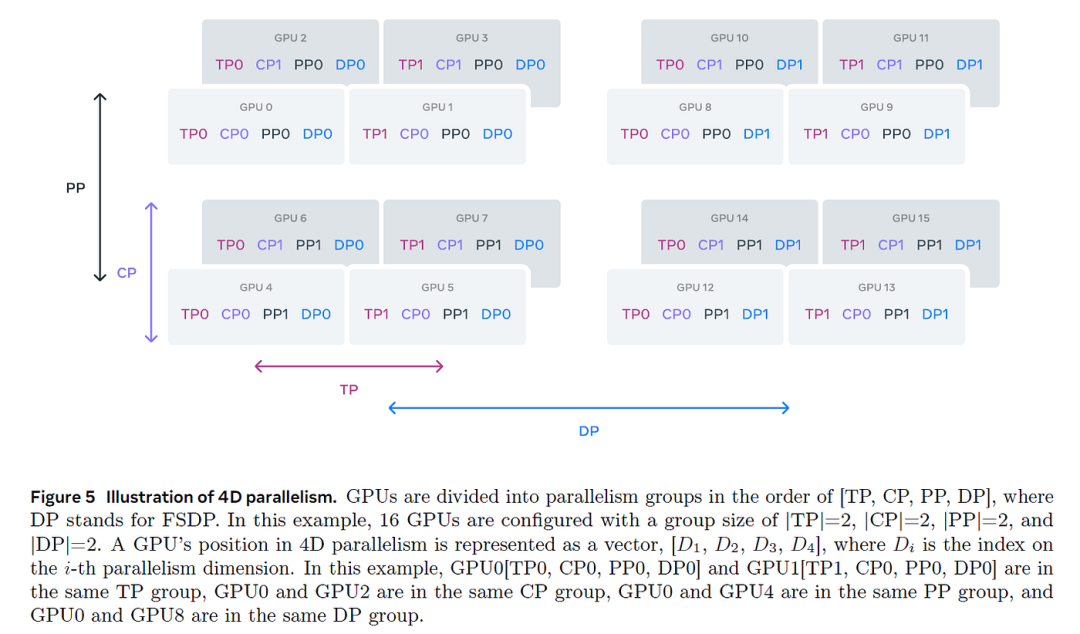
在GPU集群上高效训练大型LLM并非易事。我们学习了如何优化计算和GPU间通信,以确保它们始终处于最大化利用率。这涉及为特定模型和集群规模选择合适的并行策略,在可能的情况下重叠通信和计算,并编写自定义核函数,以充分利用硬件架构,使运算尽可能快地执行。
你可能会认为这些知识相对小众,仅适用于少数从事LLM预训练的研究人员。历史上确实如此,但随着AI开发者社区和模型规模的迅速增长,越来越多的人在推理、微调和训练中使用分布式技术,使分布式训练变得越来越普遍。因此,深入学习分布式计算正当其时。
这不仅是你的学习旅程,也是我们的学习之旅!在GPU集群上运行数千次基准测试比我们预想的更具挑战性,我们也希望与你分享我们的学习经验。
那么,接下来呢?
你现在对主要的分布式训练概念有了很好的理解,但同时,我们也只是触及了许多工具和技术的表面。以下是我们推荐的深入学习步骤:
-
仔细阅读一些重要的或最新的论文。在参考文献部分,你可以找到许多影响深远的论文、博客文章和书籍。 -
从零开始实现一个算法。通常,只有自己动手实现,方法才能真正“豁然开朗”。 -
深入研究一个广泛使用的框架,并开始贡献:修复bug、回答问题或实现新功能。这是进入任何机器学习领域的最佳途径!
我们希望这本书能帮助你入门分布式训练,并希望你能训练出下一代优秀的模型!
Reference
[1] https://resources.nvidia.com/en-us-tensor-core
[2] https://siboehm.com/articles/22/CUDA-MMM
[3] https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html#metrics-reference
[4] https://horace.io/brrr_intro.html
[5] https://tridao.me/
[6] Mixed Precision Training
[7] FP8-LM: Training FP8 Large Language Models http://arxiv.org/pdf/2310.18313.pdf
[8] torchao: PyTorch native quantization and sparsity for training and inference https://github.com/pytorch/torchao
[9] DeepSeek-V3 Technical Report
[10] Small-scale proxies for large-scale Transformer training instabilities
[11] https://github.com/huggingface/nanotron/pull/70
(文:GiantPandaCV)