

随着多模态大模型(Large Multimodal Models, LMMs)的快速发展,其在语言、视觉等多领域展现出强大的理解能力。然而,近期 o1, R1, o3-mini 等推理模型的出现不禁使人好奇:最先进的 LMMs 是否也和 R1 一样具备类似人类的推理能力?
为了回答这一问题,腾讯 Hunyuan 团队提出了一个新的多模态推理基准测试框架——MM-IQ,旨在系统地评估多模态模型的抽象推理和逻辑思维能力。

论文地址:
代码仓库:
项目主页:
数据集地址:
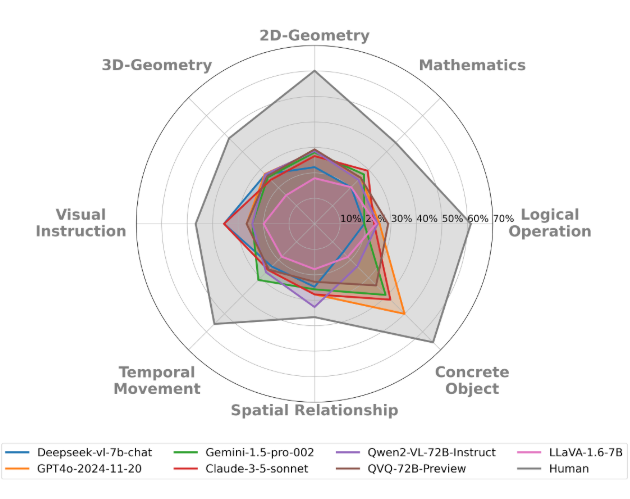
▲ 图1.1:多模态模型以及人类在 MM-IQ 基准测试中的表现
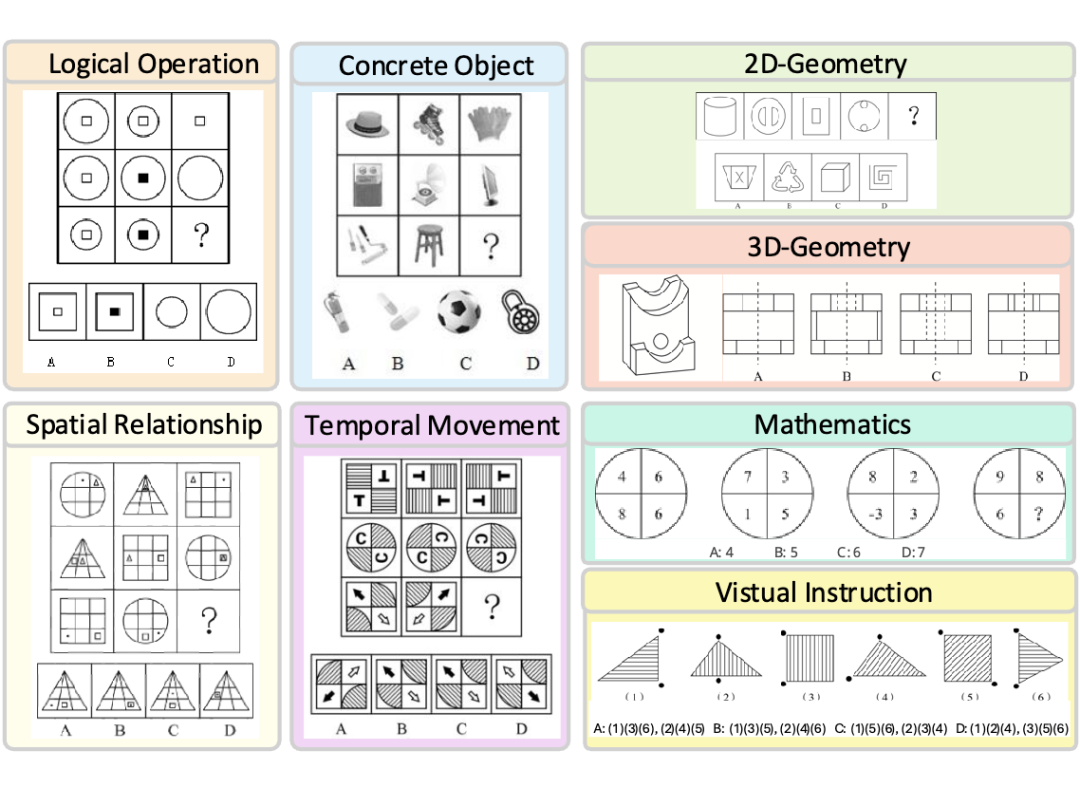
▲ 图1.2: MM-IQ 的 8 类推理问题示例

研究背景
在人类认知能力的评估中,智商测试(IQ Test)一直被视为衡量抽象推理能力的重要工具。它通过剥离语言背景、语言能力和特定领域知识,专注于评估人类的核心认知能力。然而,目前在人工智能领域,尤其是在多模态系统中,缺乏一个能够系统量化这些关键认知维度的基准。
现有的多模态模型虽然在 OCR、目标定位和医学图像分析等特定任务上表现出色,但这些任务的评估指标无法全面衡量多模态系统的核心推理能力。为了解决这一问题,腾讯 Hunyuan 团队从人类 IQ 测试中汲取灵感,提出了 MM-IQ 基准,旨在通过语言和知识无关的评估,系统地衡量多模态模型的抽象推理能力。

MM-IQ 基准介绍
MM-IQ 基准包含 2,710 个精心策划的测试项目,涵盖了 8 种不同的推理范式,包括逻辑运算、数学推理、二维几何、三维几何、空间关系、时间运动、视觉指令和具体对象。这些范式不仅涵盖了多模态模型需要掌握的核心推理能力,还通过多样化的题目配置,全面考察多模态系统的认知水平。
2.1 数据集构建
MM-IQ 的数据收集过程分为三个阶段。首先,团队从中国国家公务员考试的公开题目中筛选出适合的题目,这些题目原本用于评估考生的抽象和推理能力,因此非常适合用于多模态模型的推理能力测试。其次,团队对这些题目进行了分类,并对题目较少的推理范式进行针对性补充,以确保每个推理范式都有足够的样本。最后,通过去重和答案提取等步骤,确保数据集的准确性和有效性。
2.2 推理范式
-
逻辑运算:涉及逻辑运算符(如 AND、OR、XOR)的应用,需要模型识别图形中的逻辑规则。
-
数学推理:评估模型对数量、数字和算术运算的推理能力。
-
二维几何:涵盖对二维几何图形属性的理解和图形拼接能力。
-
三维几何:评估模型对三维几何图形的理解,包括多面体的视图识别和立体图形的截面识别。
-
空间关系:考察物体之间的静态相对位置关系。
-
时间运动:关注物体的位置变化,包括平移、旋转和翻转。
-
视觉指令:通过视觉提示(如箭头)引导模型解决问题。
-
具体对象:涉及对现实世界物体(如花瓶、叶子、动物)的分类。

实验结果
腾讯 Hunyuan 团队对多种开源和闭源的多模态大模型进行了评估,包括 Deepseek-vl-7b-chat、Qwen2-VL-72B-Instruct、QVQ-72B-Preview和 GPT-4o 等。结果显示,即使是性能最好的模型,其准确率也仅为 27.49%,仅略高于随机猜测的基线水平(25%),而人类的平均准确率则高达 51.27%。
3.1 模型表现
-
开源模型:LLaVA-1.6-7B 的准确率为 19.45%,Deepseek-vl-7b-chat 为 22.17%,Qwen2-VL-72B-Instruct 为 26.38%,QVQ-72B-Preview为 26.94%。
-
闭源模型:GPT-4o 的准确率为 26.87%,Gemini-1.5-Pro-002 为 26.86%,Claude-3.5-Sonnet 为 27.49%。
3.2 推理范式分析
在不同推理范式中,人类和闭源模型(GPT-4o)在具体对象推理中表现更好,准确率分别为 65.79% 和 50%。这可能是因为具体对象推理需要额外的知识。而逻辑运算范式则是多模态模型的弱项,平均准确率仅为 23.69%,因为这一范式需要模型识别更复杂的抽象规则。

失败原因分析
-
推理范式出错:模型倾向于依赖简单的规则进行推理,而不是提取更复杂的抽象规则。
-
视觉理解错误:模型在复杂视觉范式(如逻辑运算和空间关系)上的表现较差,这表明需要提升模型对复杂视觉细节的感知能力。
-
直接给出最终答案:一些模型直接给出答案时表现更差,而生成详细推理链的模型表现更好。

研究意义
MM-IQ 基准的提出填补了多模态领域缺乏系统推理评估基准的空白。它不仅揭示了当前多模态模型在抽象推理能力上的巨大不足,还为未来的研究方向提供了明确的指引。通过提升模型的结构化推理能力、抽象模式识别能力和视觉理解能力,有望推动 AGI 的发展。

总结
MM-IQ 基准为多模态模型的推理能力评估提供了一个全新的视角。它通过多样化的抽象推理范式和高质量的数据集,系统地衡量了多模态模型的抽象推理能力。
实验结果表明,当前的多模态模型在这一任务上表现不佳,与人类水平相去甚远。未来的研究需要在模型架构、训练方法和数据多样性等方面进行更多探索,以缩小这一差距。
(文:PaperWeekly)