


DeepSeek 开源周第四天放大招,推出并行计算优化三剑客,直接放出了DeepSeek-V3和R1 模型背后的并行计算优化技术,一口气带来了三个宝藏项目!
三个项目,简单来说分别对应:
✅ DualPipe – 双向流水线并行算法,让计算和通信高效协同
✅ EPLB – 专家并行负载均衡器,让每个 GPU 都“雨露均沾”
✅ profile-data – 性能分析数据,深入剖析 V3/R1 的并行奥秘
这三个项目个个都是硬核技术,每一个都直击大模型训练和推理的效率痛点!下面带大家逐个解读
DualPipe:双向流水线并行算法
项目地址:https://github.com/deepseek-ai/DualPipe

DualPipe 是 DeepSeek-AI 在DeepSeek-V3 技术报告中提出的创新双向流水线并行算法。它厉害在哪呢?
-
• 计算-通信全重叠: 传统流水线并行难免会有 “pipeline bubbles”(流水线气泡),导致 GPU 等待。 DualPipe 的绝妙之处在于,它能让前向计算和后向计算的通信阶段完美重叠! -
• 减少 Pipeline Bubbles: 通过精巧的设计,DualPipe 显著减少了流水线气泡,让 GPU 资源得到最大化利用
看看官方提供的 Schedules 图,简直是艺术! 🎨 清晰展示了 8 个 PP ranks 和 20 个 micro-batches 的调度策略,前向和后向计算对称进行,重叠区域一目了然!
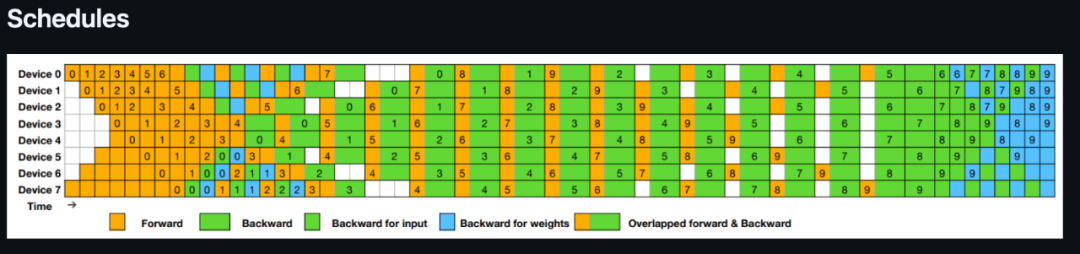
再看看 Pipeline Bubbles and Memory Usage Comparison 表格,DualPipe 对比 1F1B 和 ZB1P,在减少 bubbles 的同时,内存效率也杠杠的!
如果你想在自己的项目中用上 DualPipe,DeepSeek-AI 也贴心地提供了 Quick Start 指南和 example.py 示例代码。 基于 PyTorch 2.0+ 版本就能轻松上手!
EPLB:专家并行负载均衡,让 GPU 各司其职!
项目地址:https://github.com/deepseek-ai/eplb

EPLB (Expert Parallelism Load Balancer) 顾名思义,是为专家并行 (Expert Parallelism, EP)量身打造的负载均衡利器!
在 EP 中,不同的专家模型会被分配到不同的 GPU 上。 但是,专家模型的负载可能会随着输入数据变化而波动,导致 GPU 负载不均,影响整体效率。 EPLB 就是来解决这个问题的!
DeepSeek-V3 采用了冗余专家 (redundant experts)策略,复制重负载专家,并巧妙地将它们分配到不同的 GPU 上,实现负载均衡。 同时,结合 group-limited expert routing 技术,尽量将同一组的专家放在同一节点上,减少跨节点通信
EPLB 提供了两种负载均衡策略:
-
• Hierarchical Load Balancing (分层负载均衡): 当服务器节点数可以整除专家组数时使用。 先平衡节点间的负载,再平衡节点内 GPU 的负载。 适用于预填充 (prefilling) 阶段 -
• Global Load Balancing (全局负载均衡): 适用于其他情况。 全局复制专家,然后分配到各个 GPU。 适用于解码 (decoding) 阶段
项目提供了详细的 Interface and Example, 让你轻松理解如何使用 eplb.rebalance_experts 函数,根据专家权重、副本数、组数、节点数和 GPU 数,计算出最优的专家复制和放置方案。 还有生动的 placement plan 图示,一目了然!
📊 profile-data:性能分析数据,揭秘 V3/R1 并行策略!
项目地址:https://github.com/deepseek-ai/profile-data
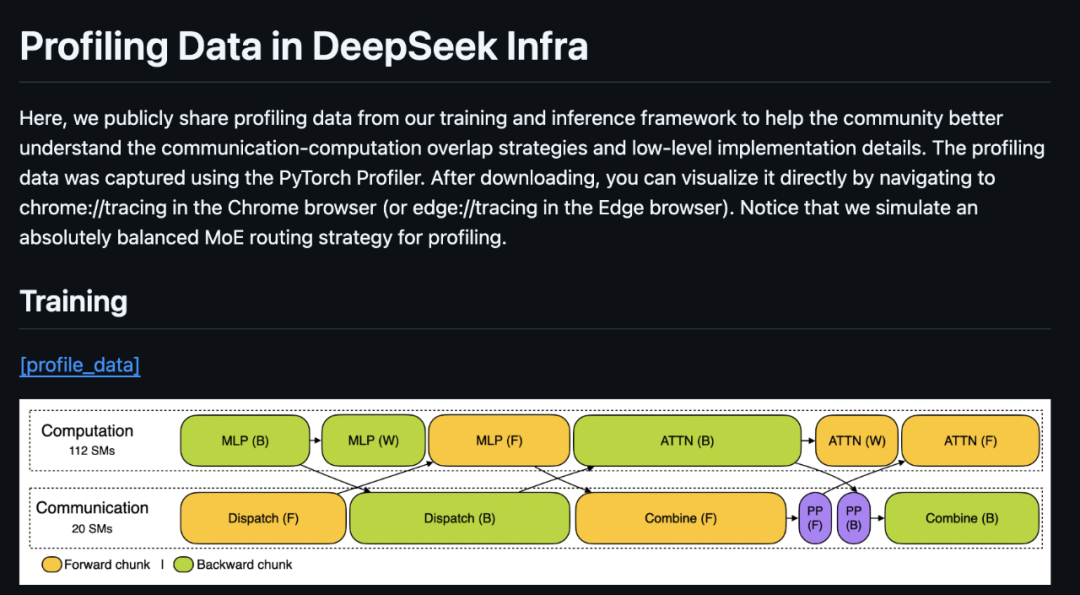
DeepSeek直接公开了他们的 训练 (Training) 和 推理 (Inference) 框架的性能分析数据! 简直是手把手教你学优化!
这些数据是用 PyTorch Profiler 采集的,下载后可以直接在 Chrome 或 Edge 浏览器中通过 chrome://tracing 或 edge://tracing 打开,可视化分析! DeepSeek-AI 还贴心地模拟了绝对平衡的 MoE 路由策略用于性能分析
项目提供了 Training, Prefilling 和 Decoding 三种场景的性能数据:
-
• Training (训练): 展示了 DualPipe 在一对 forward 和 backward chunks 中的重叠策略。 使用了 4 层 MoE,EP64, TP1, 4K 序列长度等 DeepSeek-V3 预训练设置。 注意,为了简化分析,PP 通信被排除在外 -
• Prefilling (预填充): 采用了 EP32, TP1,4K 提示长度,16K tokens/GPU 的 batch size。 展示了如何使用两个 micro-batches 来重叠计算和 all-to-all 通信,并确保 attention 计算负载在两个 micro-batches 间平衡 -
• Decoding (解码): 采用了 EP128, TP1, 4K 提示长度,128 requests/GPU 的 batch size。 同样使用了两个 micro-batches 来重叠计算和 all-to-all 通信。 但与 prefilling 不同的是,解码阶段的 all-to-all 通信 不占用 GPU SMs! RDMA 消息发出后,GPU SMs 就被释放,系统等待 all-to-all 通信完成后再继续计算。 效率更高!
通过这些性能数据,你可以清晰地看到 DeepSeek-AI 是如何精细地优化计算和通信的,学习他们是如何在 low-level 实现上提升效率的。 绝对是研究大模型并行计算的宝贵资料! 💎
写在最后:
这次 DeepSeek AI 开源的这三个项目,可以说是诚意满满,直接把大模型训练和推理的效率优化秘籍都拿出来了!利好AI研究人员
-
• DualPipe 让你掌握高效流水线并行的核心技术,提升模型训练速度。 -
• EPLB 让你学会如何为专家并行模型做负载均衡,提升 GPU 利用率。 -
• profile-data 让你深入了解 DeepSeek-V3 的并行策略,学习顶尖团队的优化经验
⭐
(文:AI寒武纪)