

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文是北京大学彭宇新教授团队在多轮交互式商品检索的最新研究成果,已被 ICLR 2025 接收并开源。
图像检索是计算机视觉的经典任务,近年来在电商等场景中广泛应用。然而,单一图像难以满足用户需求,用户常需要修改图像以适配特定场景。为此,组合图像检索(CIR)应运而生,旨在通过结合参考图像和修改文本来定位目标图像。随着多轮交互需求的增加,多轮组合图像检索(MTCIR)逐渐成为研究热点,能够利用用户迭代反馈不断优化检索结果。然而,现有MTCIR方法通常通过串联单轮CIR数据集构建多轮数据集,存在两点不足:(1)历史上下文缺失:修改文本缺乏对历史图像的关联,导致检索偏离实际场景;(2)数据规模受限:单轮数据集规模有限,串联方式进一步压缩了多轮数据集的规模,难以满足研究和应用需求。
为解决上述问题,本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。
本文进一步提出了多轮聚合-迭代模型MAI,重点应对MTCIR中的两大挑战:(1)多模态语义聚合,(2)多轮信息优化。具体而言,MAI引入了一种新的两阶段语义聚合(TSA)范式,并结合循环组合损失(CCL)计算。TSA通过引入描述文本作为过渡,逐步将图像与其描述文本聚合,再与修改文本聚合。CCL的循环结构进一步增强了语义一致性和模态对齐。此外,本文设计了一种无参数的多轮迭代优化(MIO)机制,动态选择具有高语义多样性的代表性标记,有效压缩了历史数据表征的存储空间。实验结果表明,本方法在所提出的新基准FashionMT的召回指标上平均提升了8%,优于现有方法。

-
论文标题:MAI: A Multi-turn Aggregation-Iteration Model for Composed Image Retrieval -
论文链接:https://openreview.net/pdf?id=gXyWbl71n1 -
开源代码:https://github.com/PKU-ICST-MIPL/MAI_ICLR2025 -
实验室网址:https://www.wict.pku.edu.cn/mipl
背景与动机
多轮组合图像检索(MTCIR)作为电商场景的关键技术,旨在通过持续对话理解用户动态调整的需求。现有方法采用”多轮串联单轮”范式时,模型陷入仅依赖当前轮次图像的路径依赖,导致历史语义链路断裂——当用户修改需求涉及历史属性时(如”保留前两轮的袖口设计”),检索系统因无法回溯上下文而失效。这一现象暴露两大关键不足:首先,现有数据集构建方式割裂了跨轮次的语义关联,使模型陷入局部最优陷阱;其次,传统单轮优化范式难以适应多轮场景的语义累积特性,在长程信息传递与动态记忆压缩方面存在设计局限。
针对上述不足,本文提出了系统性解决方案:(1) 跨轮次语义建模框架:通过显式标注多轮修改需求与历史图像的语义关联,构建首个具备历史回溯特性的数据集和评测基准FashionMT;(2) 两阶段跨模态语义聚合:设计基于TSA模块与CCL损失的渐进式对齐架构,通过图像-文本-指令的层级交互解决模态鸿沟问题;(3) 动态记忆压缩机制:设计MIO模块,利用基于聚类算法的token选择策略实现长程依赖建模中的信息优化,在保持检索精度的同时减少历史信息冗余存储。本文方法实现了多轮检索中语义连续性与计算效率的协同优化。

图1. 多轮组合图像检索样例展示
数据集和评测基准
本文的数据主要来源于两个渠道:1. 从现有的单轮组合图像检索数据集收集图像及相关文本;2. 从多个电商平台爬取图像及相关文本。在数据预处理过程中,本文对爬取的图像进行了清洗,去除损坏、模糊以及非商品类图像。
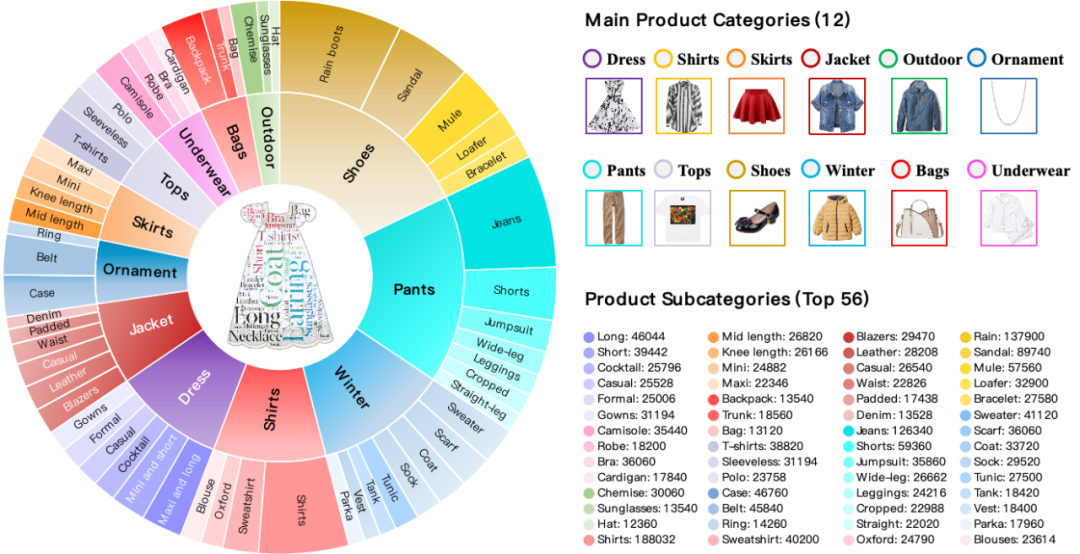
图2. 数据集和评测基准FashionMT数据分布图
受现有修改文本手工标注过程的启发,本文提出了一个自动化的数据集构建框架-修改生成框架(MGF),旨在通过捕捉参考图像和目标图像对之间的差异,自动构建数据集。该框架包括以下步骤:
1. 图像选择:从某一产品子类中选择N+1张图像用于N轮交易;2. 标题生成:利用图像描述模型为这些图像生成标题;3. 基础修改生成:采用大型语言模型(LLM)描述相邻轮次图像标题之间的差异;4. 回溯性修改生成:确定需要回溯分析的特定轮次,并根据最新图像与历史图像之间的属性交集生成相应的修改文本。
为了更好地适应现实场景中的回溯性需求,本文设定了两种回溯性修改文本生成情境:回滚和组合。在回滚设置中,通过回滚的方式在指定的参考图像与目标图像之间生成修改文本。该情境下的示例为:“Compared to the most recent turn, I still prefer the item from the second turn. Building on that, I like…”。在组合设置中,用户结合多个历史轮次中的图像属性来构建修改请求。该情境下的示例为:“I like … from the first turn, and … from the second turn” 。在此设置中,修改文本由两部分组成:第一部分是描述需要保留的公共属性,并以提示 “Keep the {Attr} in the {ID} turn” 开头,其中 {Attr}表示如颜色、logo、图案等属性,{ID}表示与目标图像共享属性的轮次;第二部分描述附加的修改需求。
FashionMT在规模和丰富性上显著超越现有数据集,图像数量是MT FashionIQ的14倍,类别数量是MT Shoes的近10倍。通过利用修改生成框架,FashionMT实现了高效的交易构建,数据集规模为MT FashionIQ的27倍。此外,FashionMT的修改文本更加详尽,平均长度是MT FashionIQ的两倍。作为专为MTCIR任务设计的数据集,FashionMT为多模态图像检索任务提供了更加全面和真实的数据支持。
技术方案
为应对MTCIR中的两大挑战——多模态语义聚合和多轮信息优化,本文提出了多轮聚合-迭代模型(MAI)。如图3所示,MAI包含4个主要模块:
1.多模态语义聚合(BSA):通过聚合图像描述和修改文本的语义信息,增强图像与文本之间的语义对齐。
2.多轮迭代优化(MIO):通过优化多轮交互中的关键语义 tokens,减少冗余信息,提升检索性能。
3.修改语义聚合(MSA):将修改文本与参考图像的语义信息进行融合,以强化修改内容对图像的语义影响。
4.循环组合损失(CCL):通过多轮训练中的循环优化机制,强化目标图像与修改文本之间的匹配度。
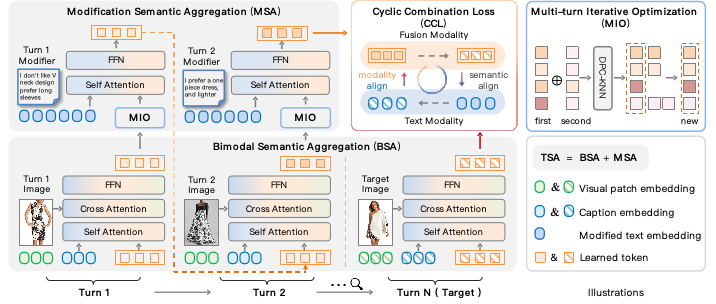
图3. 多轮聚合-迭代模型方法框架图
模块1:多模态语义聚合(BSA)
在第 n 轮,首先对修改文本进行语法分析,判断是否存在回滚操作,判断标准是基于预设模板生成的修改文本。如果修改文本匹配回滚模板,则将参考图像指定为回滚轮次中的图像;如果不匹配,则默认选择第 n 轮的参考图像。通过冻结视觉编码器提取图像的视觉补丁嵌入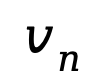 。BSA 框架通过可学习的 tokens,首先学习图像及其描述之间的模态语义,然后与修改文本进行交互,从而在与修改文本交互时增强模态之间的相关性。经过 BSA 后,tokens 聚合了参考图像和图像描述的多模态语义,记为
。BSA 框架通过可学习的 tokens,首先学习图像及其描述之间的模态语义,然后与修改文本进行交互,从而在与修改文本交互时增强模态之间的相关性。经过 BSA 后,tokens 聚合了参考图像和图像描述的多模态语义,记为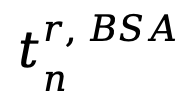 。
。
模块2:多轮迭代优化(MIO)
尽管tokens 比视觉嵌入更节省空间,但为每一轮存储这些 tokens 仍会消耗大量空间。电商图像通常具有不同的属性,如颜色、风格、尺寸等,而多轮检索往往涉及同一子类别的商品,导致多轮图像之间存在相似属性。因此,提出了一种无参数机制,用于优化并保留在多轮交互中关键的语义属性。本方法将上一轮的学习到的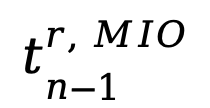 与当前轮的
与当前轮的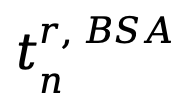 拼接得到
拼接得到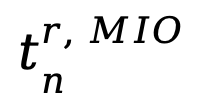 ,优化过程包括以下几个步骤:
,优化过程包括以下几个步骤:
(1)聚类:基于 k-最近邻的密度峰值聚类算法(DPC-kNN),对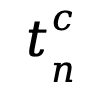 进行聚类,聚类操作可表示如下
进行聚类,聚类操作可表示如下
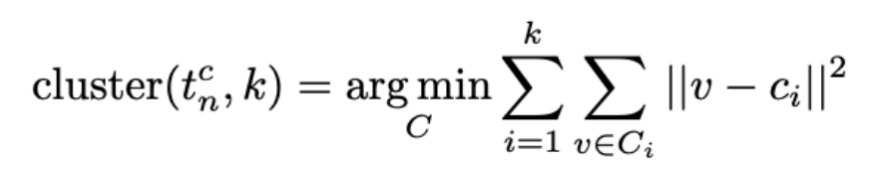
其中 表示第 i 个聚类,
表示第 i 个聚类,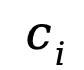 为第 i 个聚类的质心。
为第 i 个聚类的质心。
(2)密度估计:聚类后,根据簇内 tokens 与其他 tokens 的距离,估计每个簇的密度,低密度的 tokens 会被过滤掉。密度估计公式为:
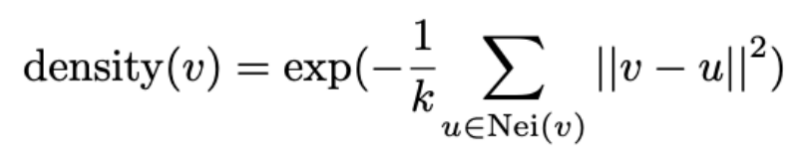
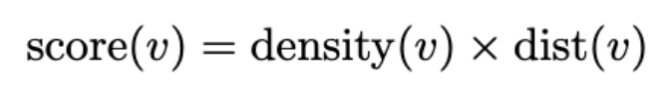
其中 Nei(v) 表示 v 的邻近 tokens。
(3)修剪:通过计算每个 token 的密度和与邻近点的距离,过滤得分较低的 tokens,保留得分高即语义显著的 tokens。最终表示为 ,有效保留了携带判别性语义的 tokens,减少了计算资源的消耗。
模块3:修改语义聚合(MSA)
在 MSA 阶段,本文将包含参考语义的tokens 与修改文本嵌入 m_n 进行交互。通过冻结文本编码器提取修改文本的嵌入,将其与拼接后输入自注意力层。随后,经过线性变换和归一化处理,最终得到参考端的嵌入 ,该嵌入同时包含来自参考图像、图像描述和修改文本的多模态语义。由于涉及多个历史图像,BSA 将通过拼接前几轮的tokens 与对应的图像描述,进行多模态嵌入的聚合。随后,这些嵌入将与修改文本在 MSA 中进行语义聚合。
,该嵌入同时包含来自参考图像、图像描述和修改文本的多模态语义。由于涉及多个历史图像,BSA 将通过拼接前几轮的tokens 与对应的图像描述,进行多模态嵌入的聚合。随后,这些嵌入将与修改文本在 MSA 中进行语义聚合。
模块4:循环组合损失(CCL)
在多轮组合图像检索任务中,修改文本在检索过程中的引导作用至关重要。为此,本文提出了循环组合损失(CCL),旨在通过对多模态信息进行精确对齐,强化图像与文本之间的语义关联,特别是文本修改的语义。具体而言,本文设计的循环组合损失目标是通过多轮迭代中图像和文本的语义对齐,确保检索结果更加准确。该损失函数结合了4种嵌入的约束,包括参考图像的语义嵌入、目标图像的语义嵌入、修改文本的语义嵌入以及目标图像的文本特征。通过多轮训练,强化每轮之间语义的传递和优化,使得最终的目标图像能更好地与修改文本匹配。循环组合损失(CCL) 由以下4项损失组成:
(1)参考图像语义与目标图像语义之间的相似度损失
(2)目标图像语义与修改文本语义之间的相似度损失
(3)修改文本语义与目标图像文本特征之间的相似度损失
(4)目标图像文本特征与参考图像语义之间的相似度损失
每一项相似度损失通过批量分类损失计算,使用内积方法(余弦相似度)衡量嵌入之间的相似性。最终,循环组合损失为各轮损失的累积,确保在多轮交互中,所有语义信息得到充分融合和优化,其公式展示如下:
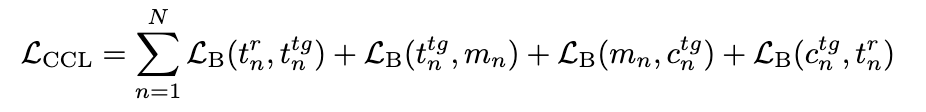
实验结果
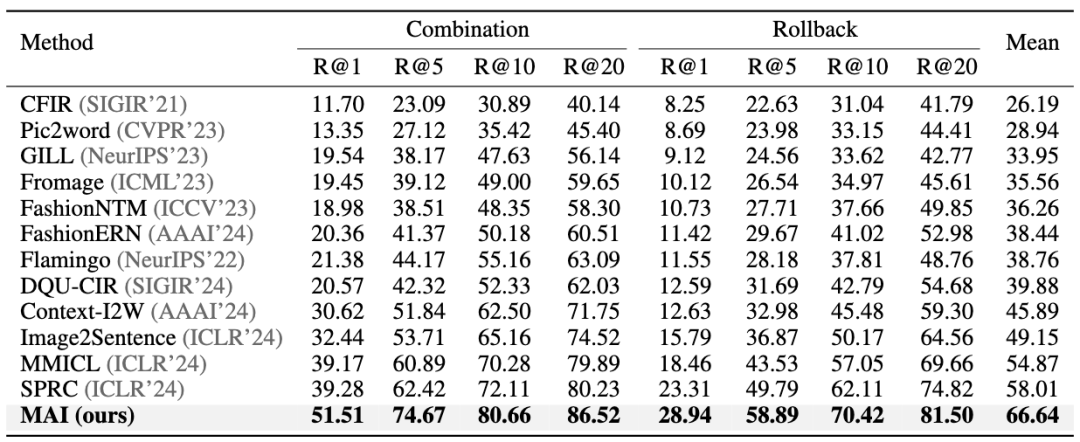
表1. 在FashionMT数据集上的实验结果
表1的实验结果表明,本文所提出的MAI方法显著优于现有方法,在检索的召回率平均指标上相比新加坡A*STAR研究院的SPRC方法提高了8.63%,相比北京大学发布的多模态混合输入大模型MMICL提高了11.77%。
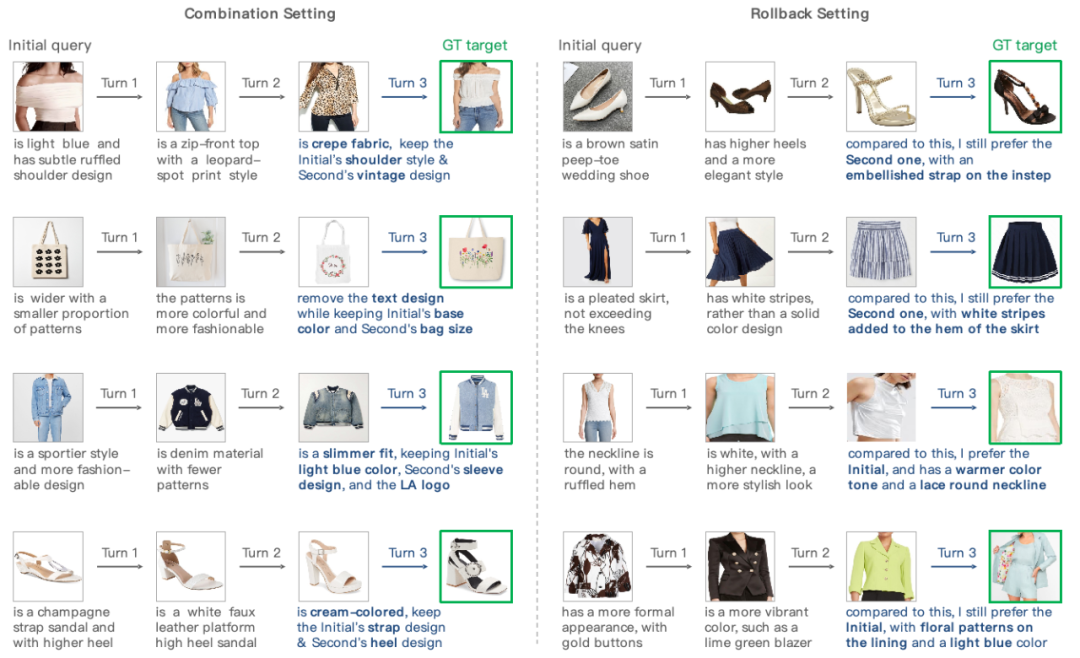
图4. 在FashionMT数据集上的检索结果可视化
图4表明, MAI通过利用TSA和CCL高效聚合图像-描述文本的语义,能够有效处理细粒度需求,使其对“绉布”和“复古设计”等领域特定术语具有识别能力。此外,MAI通过使用MIO组件保留多轮历史关键信息,能够精确解释诸如“肩带设计”等模糊表达,从而满足回溯性需求。
©
(文:机器之心)