
-
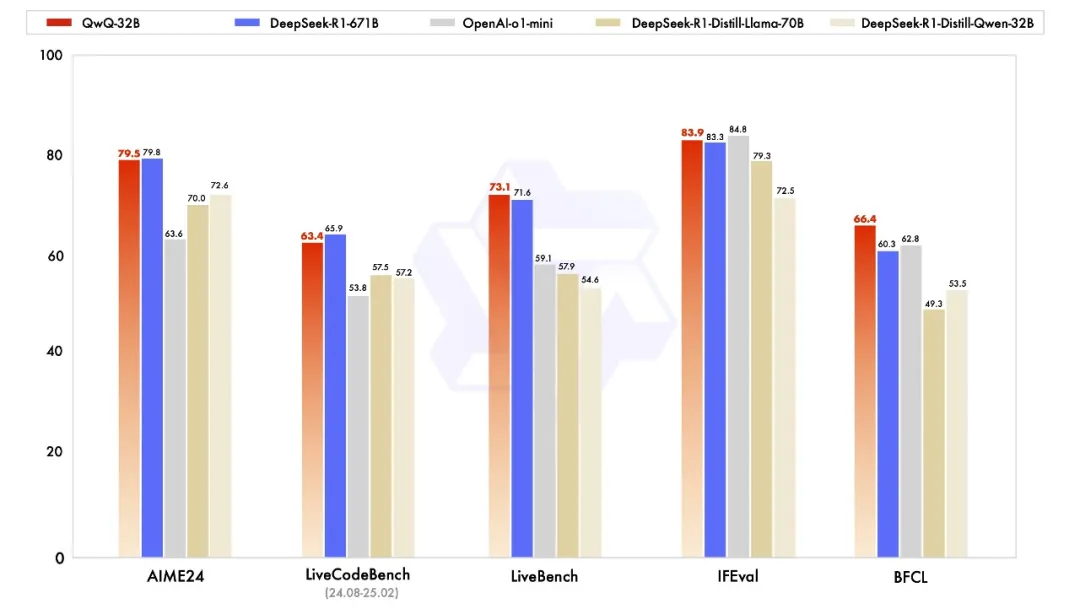
能够与当前最先进的推理模型DeepSeek-R1(满血哦,不是蒸馏) 和 o1-mini相媲美 -
推理模型中集成了与 Agent 相关的能力,使其能够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程。 -
小尺寸,不要671B,只要32B,推理门槛低

-
在初始阶段,特别针对数学和编程任务进行了 RL 训练。与依赖传统的奖励模型(reward model)不同,通过校验生成答案的正确性来为数学问题提供反馈,并通过代码执行服务器评估生成的代码是否成功通过测试用例来提供代码的反馈。 -
在第一阶段的 RL 过后,增加了另一个针对通用能力的 RL。此阶段使用通用奖励模型和一些基于规则的验证器进行训练。通过少量步骤的通用 RL,可以提升其他通用能力,同时在数学和编程任务上的性能没有显著下降。
模型类型:因果语言模型训练阶段:预训练与后训练(包括监督微调和强化学习)架构:采用 RoPE、SwiGLU、RMSNorm 和注意力 QKV 偏置的 Transformer 架构参数数量:32.5B非嵌入层参数数量:31.0B层数:64 层注意力头数量(GQA):Q 为 40 个,KV 为 8 个上下文长度:完整支持 131,072 个tokens
https://hf-mirror.com/Qwen/QwQ-32B
(文:PaperAgent)