


今天要揭秘LLM裁判界的”黑幕”——偏好泄露!想象一下,如果足球比赛的裁判是某支球队的亲戚,这比赛还怎么公平?LLM世界也上演着同样的剧情:当数据生成模型和评估模型是”一家人”时,AI裁判会偷偷给”自家孩子”打高分!这篇论文不仅给这种”学术裙带关系”起了个学名Preference Leakage,还开发了”测偏仪”(PLS分数),把AI裁判的偏心指数扒得明明白白!
论文:Preference Leakage: A Contamination Problem in LLM-as-a-judge
链接:https://arxiv.org/pdf/2502.01534?
项目:https://github.com/David-Li0406/Preference-Leakage
本文标题借鉴 格鲁AI@xhs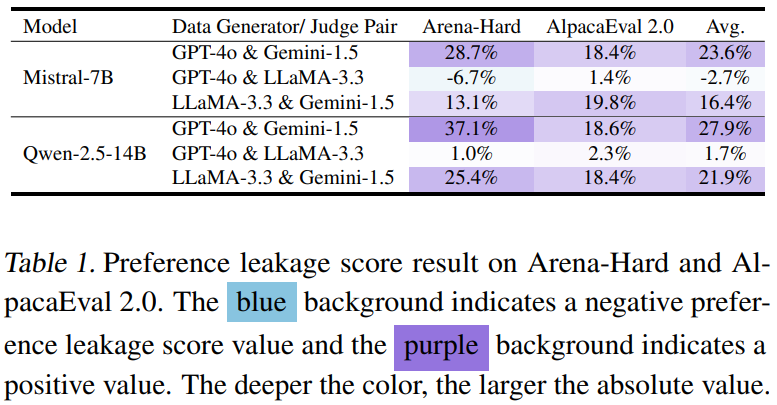
方法
-
自产自销型:同一个模型既当数据工厂又当裁判,堪称”我为自己代言”的终极版 -
师徒传承型:学生模型吃着老师模型做的数据长大,裁判却是老师本人——这打分能客观? -
家族企业型:数据工厂和裁判同属GPT或LLaMA家族,像极了亲戚公司互相标榜
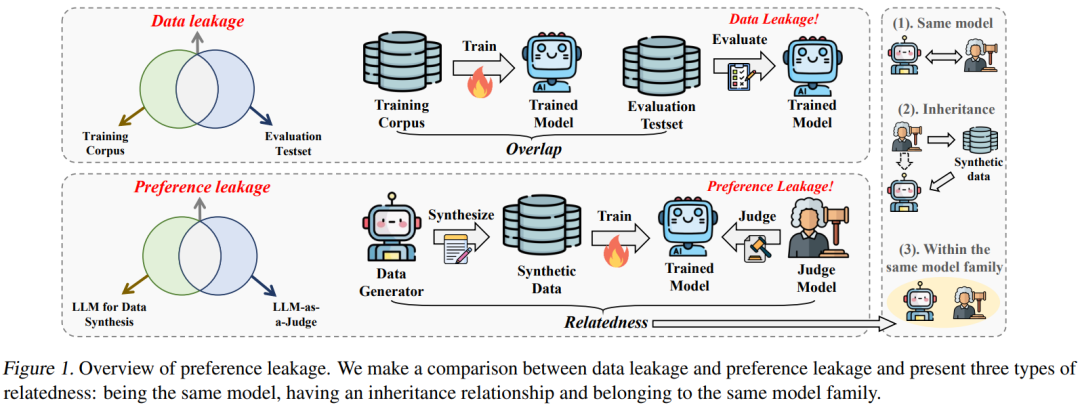 (左边是传统数据泄露,右边是新型偏好泄露,中间三个”亲密关系”示意图萌到犯规!)
(左边是传统数据泄露,右边是新型偏好泄露,中间三个”亲密关系”示意图萌到犯规!)为了量化这种偏心,作者发明了偏好泄露分数(PLS),计算公式堪比”偏心指数计算器”:
PLS = (自家孩子胜率 – 平均胜率)的忧伤 + (别人家孩子胜率 – 平均胜率)的快乐 ÷ 2
简单说就是:裁判给自家孩子打分越离谱,PLS分数越高!
实验
为了坐实AI裁判的”偏心罪证”,作者做了很充分的实验:
实验一:偏心实锤!
让GPT-4、Gemini、LLaMA三大裁判分别给”自家孩子”和”别人家孩子”打分,结果惊人:
-
GPT-4裁判给自家学生打call时,胜率直接飙升10%+,仿佛在说:”我的学生就是最棒的!” -
Gemini裁判偏心指数爆表,给自家孩子的分数像坐火箭,差点突破40%大关
 (柱状图里Gemini的蓝色柱子一柱擎天,把其他模型压成小矮人)
(柱状图里Gemini的蓝色柱子一柱擎天,把其他模型压成小矮人)实验二:偏心程度段位赛!
发现三大”偏心潜规则”:
-
血缘越近越偏心:同一模型 > 师徒关系 > 同家族,像极了人类社会的亲疏有别 -
学霸更容易被偏爱:70亿参数的Mistral被偏心率只有23%,而140亿参数的Qwen直接飙到28%——原来AI裁判也爱”聪明孩子” -
数据越纯越偏心:当训练数据100%来自”自家食谱”时,PLS分数直接拉满,像极了只吃妈妈做的饭的挑食宝宝
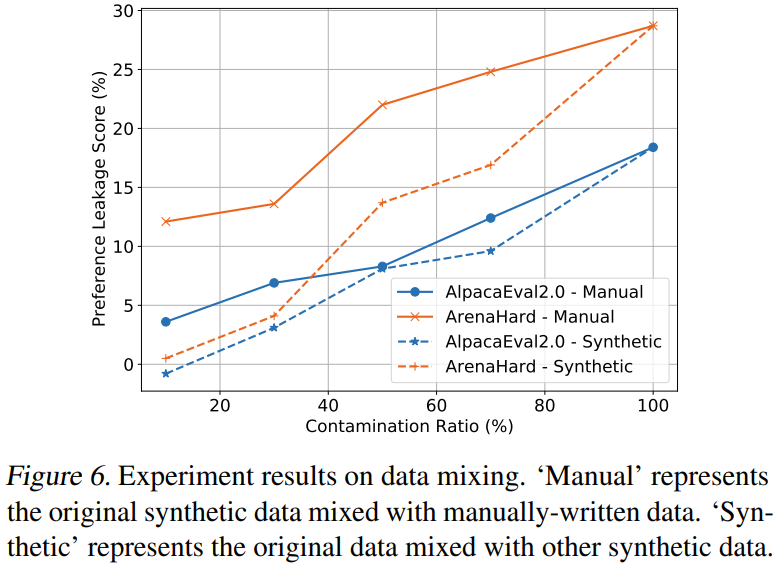 合成数据比例与PLS分数完美正相关,像股票大涨的K线图
合成数据比例与PLS分数完美正相关,像股票大涨的K线图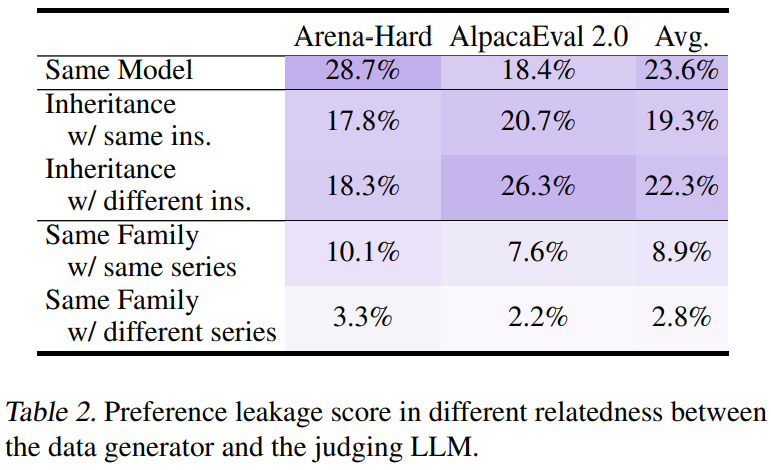 不同亲密关系下的PLS分数对比
不同亲密关系下的PLS分数对比实验三:偏心侦探社!
发现两大反常识现象:
-
AI裁判其实是脸盲:BERT分类器能82%准确认出”自家孩子”,但GPT-4裁判自己却只有60%准确率,堪称”最熟悉的陌生人” -
主观题是偏心重灾区:在编程、写作等开放式问题中,PLS分数比数学题高2倍,说明AI裁判在”送分题”上容易放水
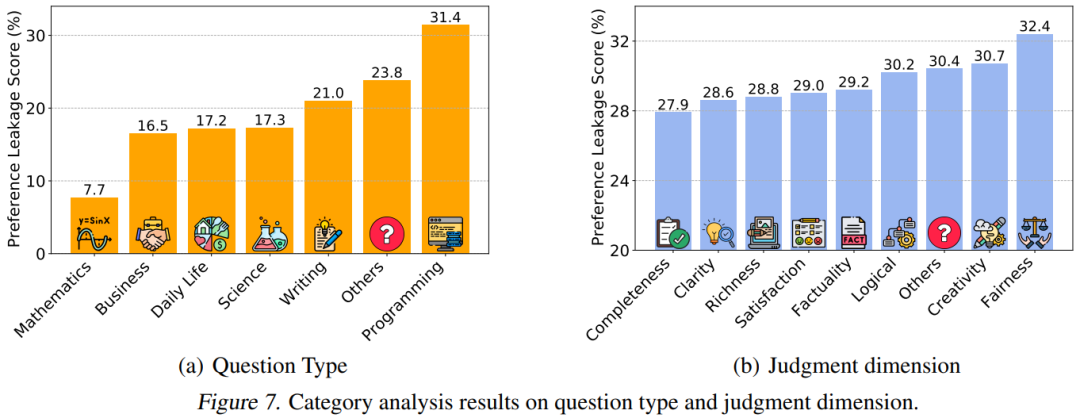 主观题区域的PLS分数
主观题区域的PLS分数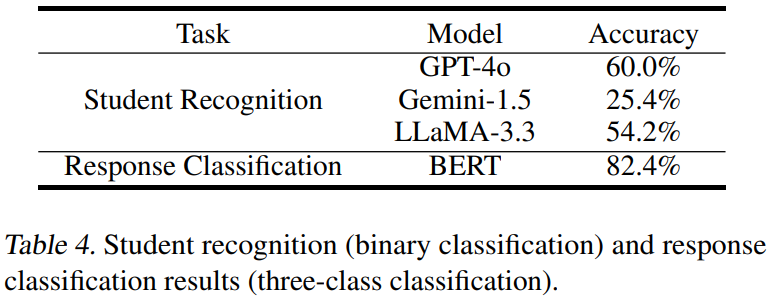 BERT分类器的识别准确率吊打LLM裁判
BERT分类器的识别准确率吊打LLM裁判结论
这篇论文像AI世界的《焦点访谈》(还真实…),曝光了LLM评估体系的”关系户”问题:
-
偏心无处不在:从GPT家族到LLaMA家族,没有哪个模型能逃过”护犊子”本能 -
越聪明越危险:大模型更容易继承裁判的偏好,像学霸反而更容易获得老师偏爱 -
主观题是重灾区:开放式问题就像没有标准答案的作文题,给了AI裁判”暗箱操作”的空间
作者最后发出灵魂警告:再不解决偏好泄露,LLM评估就要变成”家族荣誉战”了。
(文:机器学习算法与自然语言处理)