
“ 数据预处理是一项复杂且重要的过程,是神经网络的核心工作之一。”
在神经网络技术中,有几个比较重要的环节,其中就有神经网络模型的设计;但在此之前还有一个很重要的功能就是数据集的整理;一个高质量的数据集高性能神经网络模型的基础。
但怎么才能打造一个合格的数据集,以及怎么打造一个合格的数据集?而这就是神经网络模型的数据处理部分。
数据预处理
不论是在传统的数据分析领域,亦或者在神经网络模型领域;数据处理都是其中必不可少,且相当重要的一环;但怎么进行数据处理,以及数据处理需要哪些步骤,以及每个步骤的作用是什么?这个可能很多人就不是很清楚了。
数据预处理的意义
在神经网络模型训练过程中,数据集的质量直接影响到模型的性能表现;而我们在收集训练数据的过程中,难免会面临着以下几个问题:
-
原始数据存在异常值或缺失问题
-
模型无法直接处理原始数据格式
-
数据量或维度过大以及数据冗余问题
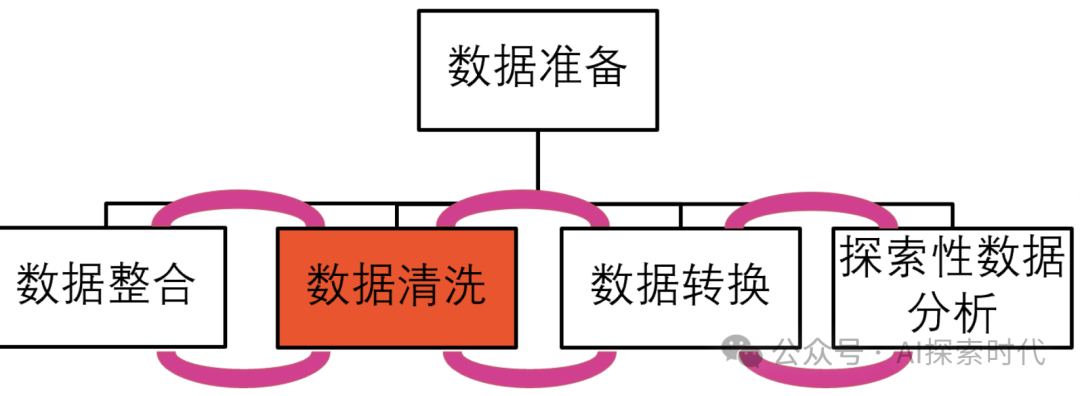
举例说明以上几个问题,首先最常见的异常值与缺失问题;比如在个人信息统计过程中,有人的年龄填了200岁;或者家庭地址没填等就属于异常值和缺失问题;因为目前来说,人不可能活到200岁,而如果是快递这种需要邮寄地址的情况,地址缺失就是不肯接受的问题。
而模型无法处理原始数据格式,比如说计算机无法直接处理文字,图片;只能把文字,图片转换成数字进行处理;亦或者时间格式可能需要转换成时间戳。
最后数据冗余问题,比如说对一个班级的学生信息进行统计;可能存在部分学生被重复统计的情况;还有一种数据冗余是可以通过其它值进行计算;如有了商品的总价和数量就可以计算均价;但在很多数据处理中,均价可能会直接计算处理,如交易报表;但在神经网络训练过程中,可能就不需要均价这个字段。
而这就是绝大部分数据所存在的问题,这也就直接导致原始数据无法直接拿来使用;必须经过一定的处理才能满足神经网络的训练需求。
因此,数据预处理需要经过哪些步骤呢?对数据预处理来说,主要需要经过以下几个步骤:
-
数据清洗
-
数据转换
-
数据压缩
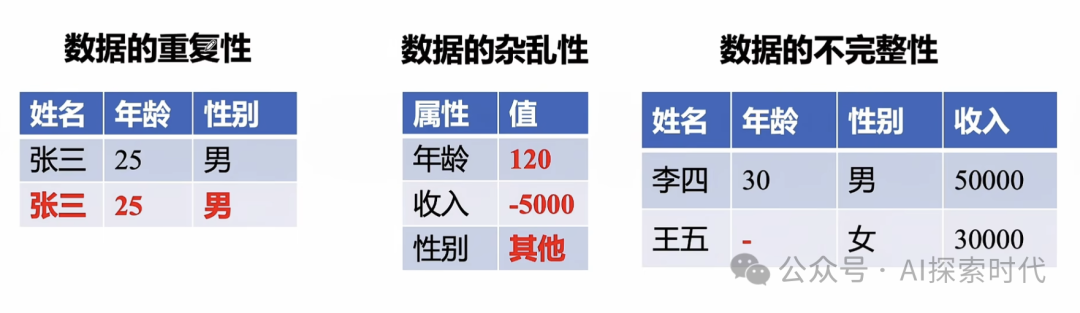
数据清洗就是需要清洗掉原始数据中存在的一些异常值,空值等;比较常见的清洗对象主要有以下几个特征:
-
数据重复
-
数据杂乱
-
数据不完整
-
数据格式不一致
-
数据偏斜
-
数据冗余
因此,数据处理的第一步一般都是数据清洗;把一些非法数据进行删除或整理。
数据清洗是数据处理的第一步,但其也有多种不同的方式;如,对非法数据直接删除;如删除数据中的重复,空值,不完整数据等;其次,也可以对数据进行填充处理,如对于不完整的数据可以使用平均值或者固定值进行填充。
举例来说,你统计一个学校的学生数据;而很多学生的信息填写并不完整,存在大量的缺失值。这时直接删除缺失数据就不太合适了,因为删除之后可能这次统计就没有意义了。因此,这时就可以对一些不重要的数据进行填充,比如你需要统计的是学生的年龄分布,这时学生的地址就可以使用固定值进行填充。
而不论是数据清洗,还是数据转换都要根据不同的需求场景,选择合适的处理方式,而不是全部进行统一处理。
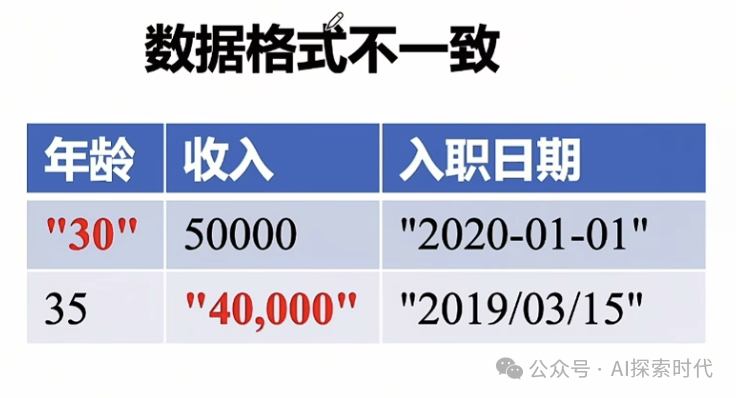
而数据转换可能涉及到数据的格式转换,以及形态的变换;如上图所示,年龄和收入应该都统一采用数值类型,而不应该出现字符串的形式;而入职日期的格式也不完全相同;这种就需要把数据格式转换成统一的类型。
而针对文本数据或图像数据,也需要特定的格式变换;如文本数据需要采用数据编码技术或者文本向量化的方式,把文本数据转换成模型能够识别的向量数据。
对于图像数据也是如此,由于图像的来源不同,因此图像数据一般需要调整大小和通道数,像素归一化处理等;比如MINST手写数字的数据集就是统一的28*28固定大小的手写数字图片。
在神经网络技术的学习过程中,很多人都只重视神经网络模型本身,而忽略了数据的预处理过程。数据预处理是一项复杂并且繁重的工作,数据的质量间接决定了模型的性能。
而且,很多模型厂商头疼的一件事就是,从哪里去找到足够且合适的训练数据。
(文:AI探索时代)