

新智元报道
新智元报道
【新智元导读】仅用32B,就击败o1-mini追平671B满血版DeepSeek-R1!阿里深夜重磅发布的QwQ-32B,再次让全球开发者陷入狂欢:消费级显卡就能跑,还一下子干到推理模型天花板!
凌晨,阿里重磅开源全球最顶尖AI模型——通义千问QwQ-32B推理模型。
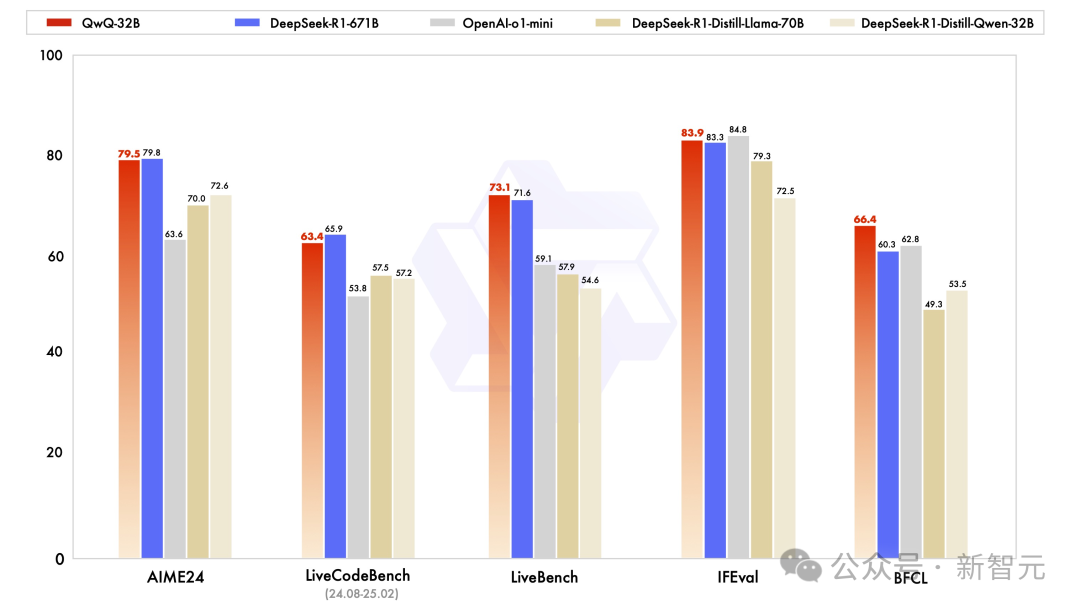
甚至,QwQ-32B在多项基准测试中全面超越o1-mini。
更令人兴奋的是,任何人能够直接在搭载消费级显卡的电脑或者Mac上体验满血版性能。(终于,我们的5090D派上用场了 )
)


左右滑动查看
更有开发者惊呼:AI模型彻底进入全民普及阶段!
如此来看,QwQ-32B简直堪称「推理能力天花板」与「实用性典范」的完美结合。
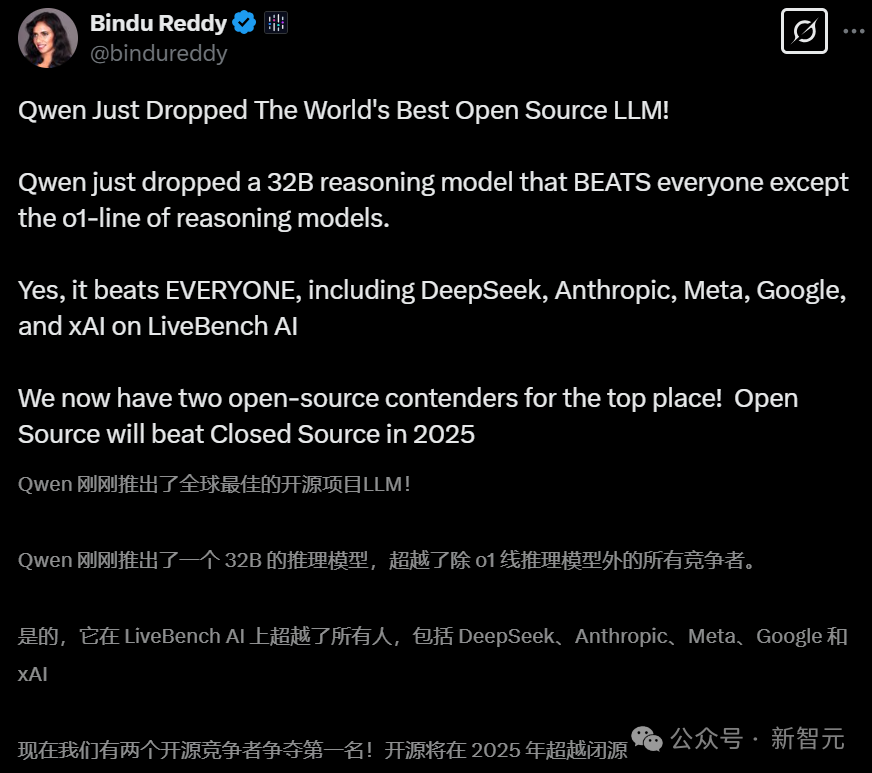
苹果机器学习研究员Awni Hannun用搭载MLX架构的M4 Max笔记本去跑QwQ-32B,结果发现运行非常流畅。

已经是上上代旗舰的3090 Ti,跑起模型来也非常之快——输出速度可达30+token/s。
目前,阿里以宽松的Apache2.0协议将QwQ-32B全面开源,全球开发者与企业均可免费下载、商用。


https://chat.qwen.ai/?models=Qwen2.5-Plus
开源新王诞生,32B媲美DeepSeek-R1
而且,其性能远超o1-mini,甚至是相同尺寸基于Qwen系列蒸馏出的R1模型。
在LeCun领衔的「最难LLMs评测榜」LiveBench、谷歌等提出的指令遵循能力IFEval评测集、由UC伯克利等提出的评估准确调用函数或工具方面的BFCL测试中,QwQ-32B得分均超越了DeepSeek- R1。
总的来说,QwQ-32B在数学、编程、通用能力方面取得了领先优势。
正是通过RL的Scaling,QwQ-32B才能实现能与DeepSeek-R1相匹敌的性能。
艾伦人工智能研究所大佬Nathan Lambert发自内心地赞叹:「QwQ-32B是给RL纯粹主义者最好的礼物。」
大佬开始仔细研读阿里放出的官方材料,并且敲桌板表示:我们需要更多论文!
接下来,是对QwQ-32B的最新实测。
我们已经部署在电脑里了
首先,来一段难度不低的数学题。
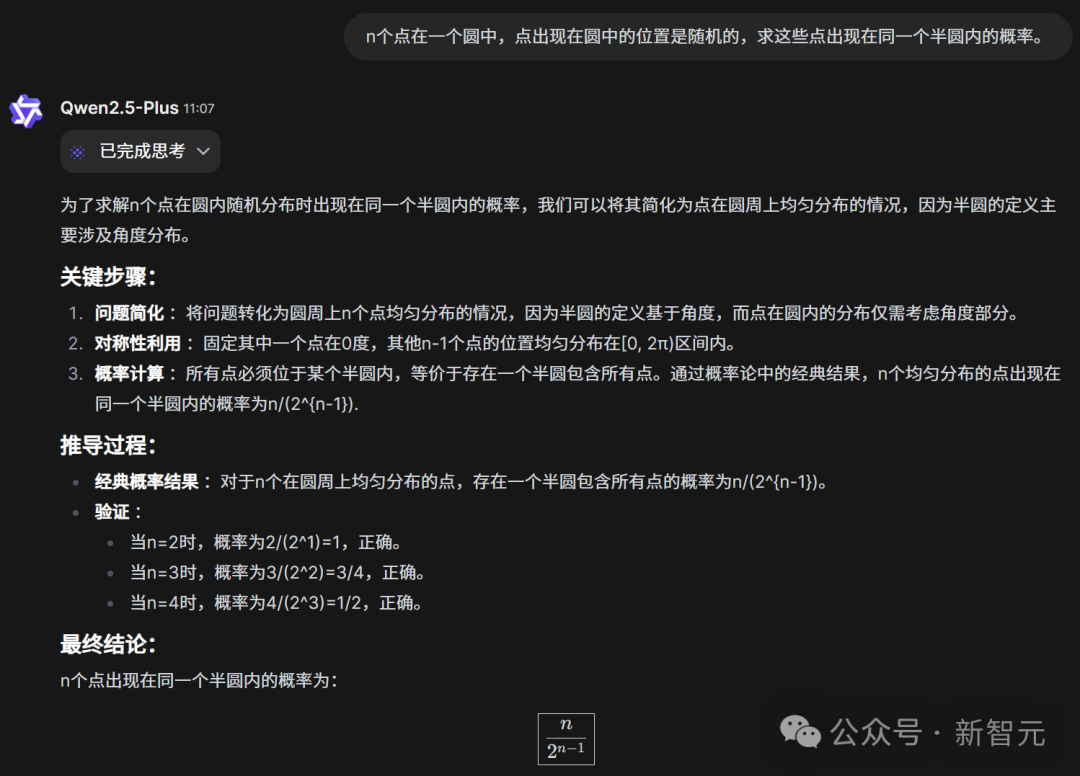
n个点在一个圆中,点出现在圆中的位置是随机的,求这些点出现在同一个半圆内的概率。
QwQ-32B在经过一大长串的思考之后,给出了正确答案。
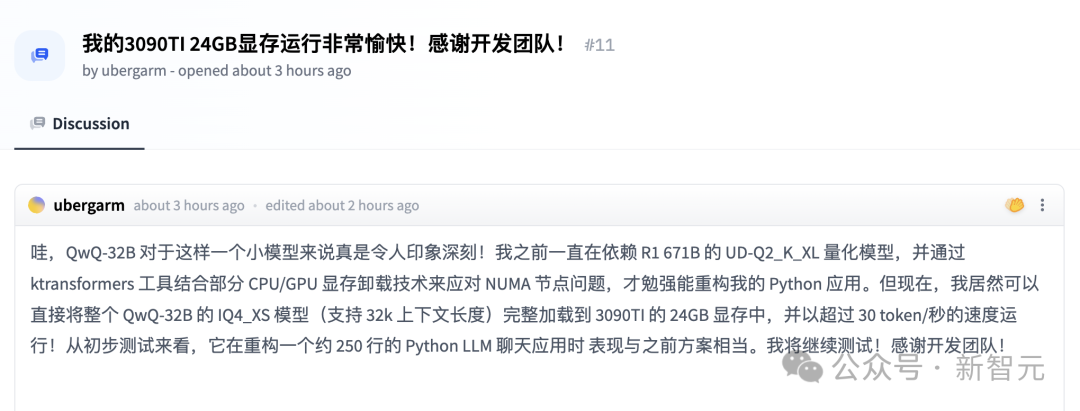
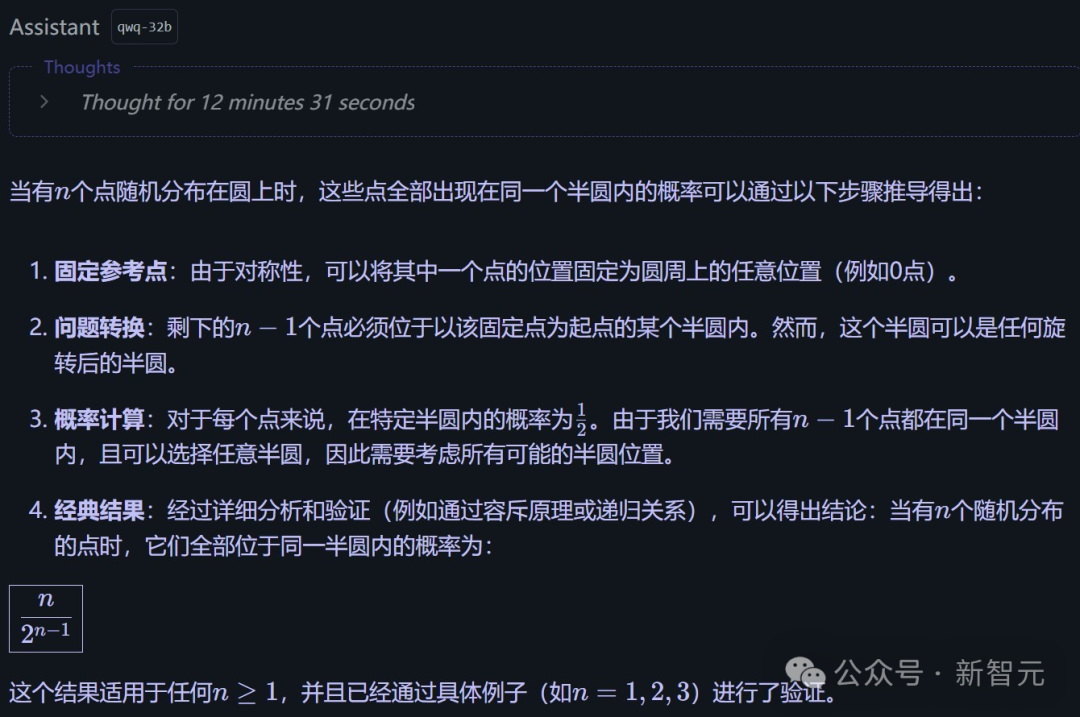
同一道题,我们也在本地部署的Q4量化模型上进行了验证。
虽然因为没优化本地环境导致输出较慢,但QwQ-32B依然一次就做对了。
而OpenAI o3-mini-high可能觉得这道题非常简单,只思考了几秒,就开始作答。
最后,果不其然答错了。

上下滑动查看
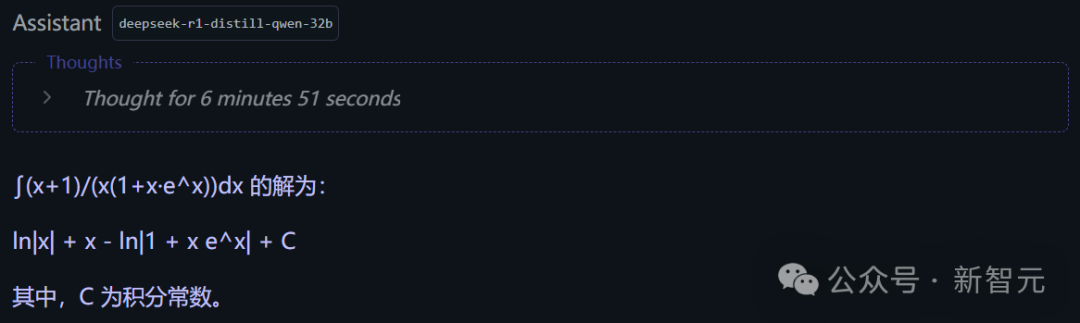
接下来是一道微积分,看它能不能解决高等数学问题。
可以看出,不管是本地部署的还是线上的QwQ-32B,都有着逻辑严谨、步骤清晰的解题过程。
从明确目标到巧妙变量代换u = xe^x,再到逐步推导和结果验证,成功将复杂积分转化为简单的对数形式,结果完全正确!


同样的提示给到蒸馏版DeepSeek-R1-32B。
可以看到,它在经过了漫长的思考之后,并没有做对。
而最有趣的,还得是OpenAI o1。
它不仅答案不对,而且两次都只说了个思路,剩下的……你自己去解吧。

再上一道推理题。
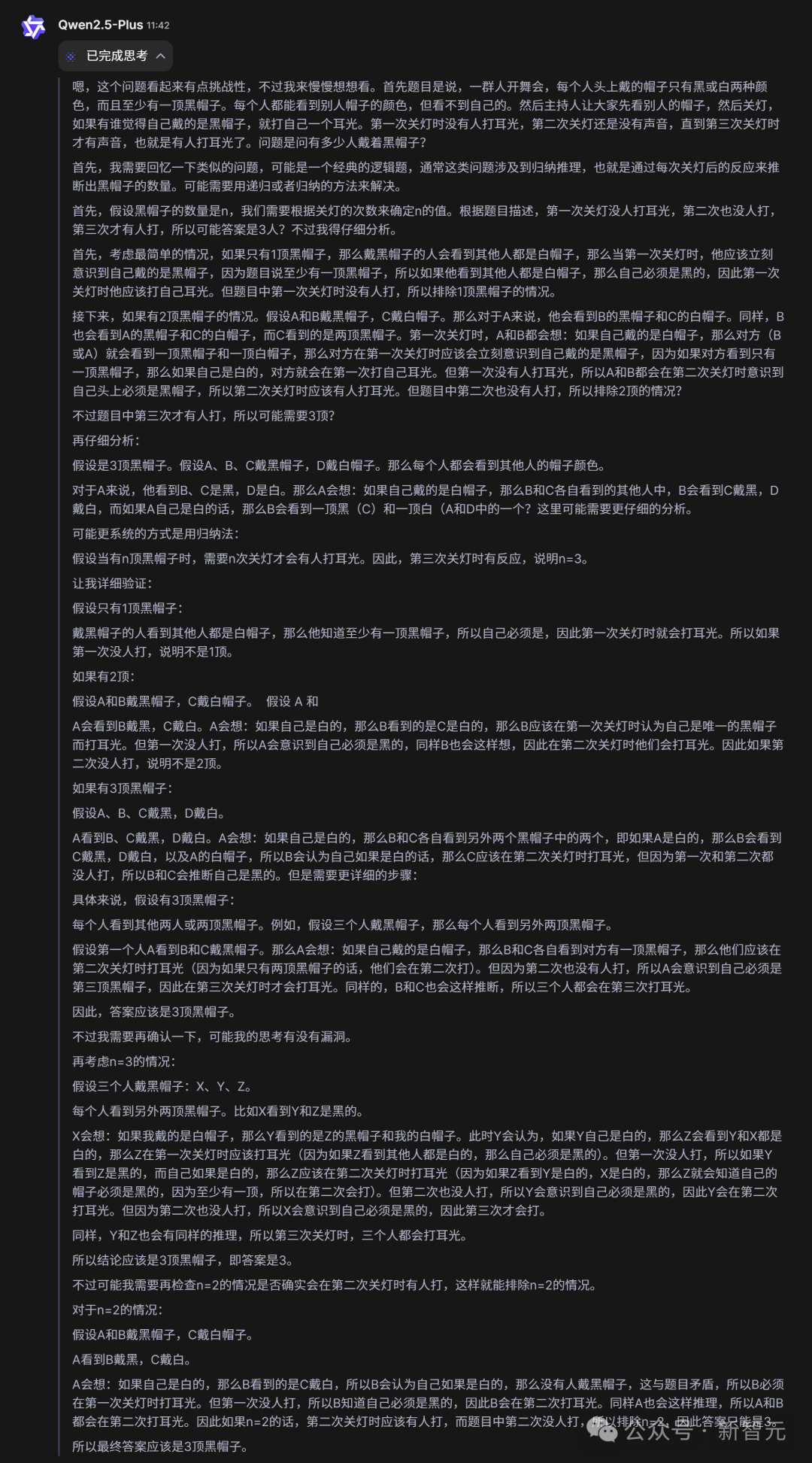
一群人开舞会,每人头上都戴着一顶帽子帽子只有黑白两种,黑的至少有一顶。每个人都能看到其它人帽子的颜色,却看不到自己的主持人。先让大家看看别人头上戴的是什么帽子,然后关灯,如果有人认为自己戴的是黑帽子就打自己一个耳光。第一次关灯,没有声音于是再开灯,大家再看一遍,关灯时仍然鸦雀无声。一直到第三次关灯,才有劈劈啪啪打耳光的声音响起。问有多少人戴着黑帽子?
在思考过程中,QwQ-32B进行了逻辑严密的推断。
上下滑动查看
最终,它给出了正确答案:3人戴着黑帽子。

本地模型同样回答正确。
而在实测过QwQ-32B的写作能力后,我们忍不住赞叹:国内的大模型中,又出了一个思想和文笔俱佳的文科生!
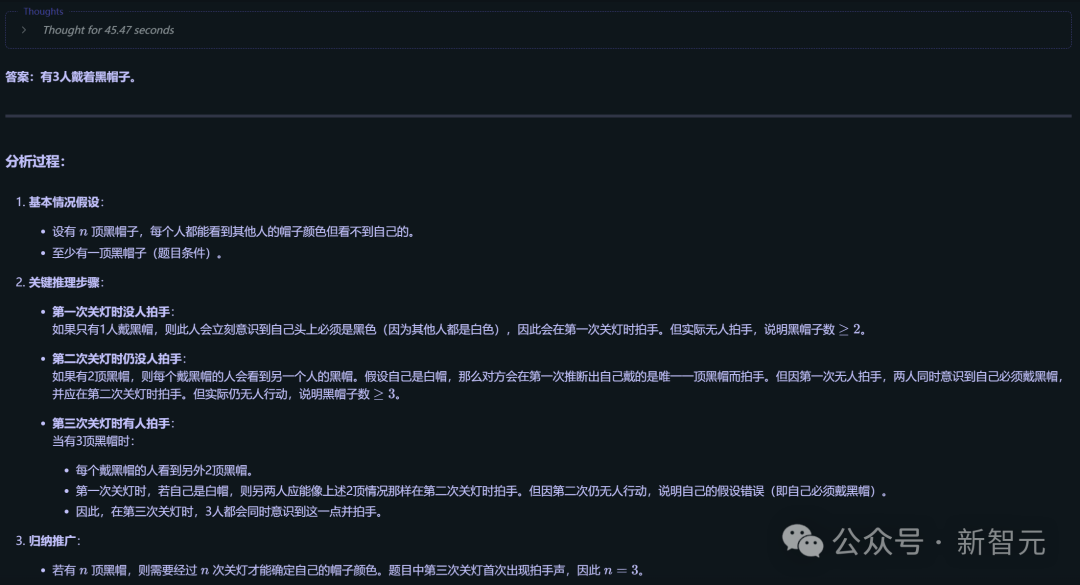
此前,DeepSeek-R1仿《过秦论》的风格写出的《过美利坚论》技惊四座,文采斐然。
现在让QwQ-32B接受同样的考验。
可以看到,它首先分析了贾谊《过秦论》的特点——多用排比、对仗,气势磅礴,语言犀利。然后想到,自己需要考虑如何将美国的历史事件与《过秦论》的结构对应起来。
难点就在于,要用文言文准确表达一些现代概念,还要保证论点有逻辑性、层层递进。

一番思考之后,QwQ-32B给出的回答果然精彩,文采丝毫不输DeepSeek-R1。

相比之下,用于技术验证的蒸馏版DeepSeek-R1-32B,在文采上就要稍逊一筹了。
另一个DeepSeek-R1惊艳全网的「续写红楼梦后八十回」,我们也把同样的题交给了QwQ-32B,让它续写红楼梦的第八十一回。
它在思考过程中,考虑到自己需要延续前作细腻的描写、复杂的人物关系和隐喻,还要回应埋下的伏笔,比如贾府的衰落、宝黛的爱情悲剧等。
甚至它还分析出,自己还要表现出原著的悲剧色彩和深刻的批判;如果要引入新角色或事件,就必须自然融入现有框架,不能突兀。
经过这番思考后,它列出了第八十一回的故事梗概,看起来很像那么回事。

而按照这个梗概续写的正文框架,虽然仍不及原作文笔,但已不无可取之处。

上下滑动查看
无需集群,笔记本都能跑
Hugging Face工程师Matthew Carrigan的部署过程,就是一个很好的参考。
想要在GPU上实现720GB(Q8量化)的显存,花费可能要10万美元以上。
当然,也可以另辟蹊径地使用CPU进行部署,只不过生成的速度会慢很多。此时,需要24条32GB的内存才能装下。

即便是Q4量化的版本DeepSeek-R1-Q4_K_M,也得需要404GB,仍然不小。
以谷歌开发者专家、UCL计算机系博士生Xihan Li的部署实操为例。
除了模型参数占用的内存+显存空间(404GB)以外,实际运行时还需额外预留一些内存(显存)空间用于上下文缓存(总计约500GB)。
在4×24GB显卡(RTX 4090)和4×96GB内存配置下,DeepSeek-R1-Q4_K_M的短文本生成的速度只有2-4 token/秒,长文本生成时速度会降至1-2token/秒。基本不可用。
相比之下,QwQ-32B本地部署则友好的多,消费级GPU单卡就能轻松部署,而且速度飞起!
比如,在Hugging Face上开源的QwQ-32B版本,以Q4量化精度为例,大小不到20GB。
不只是4-bit量化的版本,Hugging Face上还有从2位一直到8位不同的版本,最小仅需不到13GB,将本地部署的难度直接拉到最低!普通的办公电脑都能运行得起来。
本地部署后,加载与运行也是相当的容易,十几行代码就能完成模型加载、处理问题并生成答案。
Ollama也上线了Q4版本的QwQ-32B模型,安装Ollama后只需复制ollama run qwq到终端,即可体验,简直没有门槛。
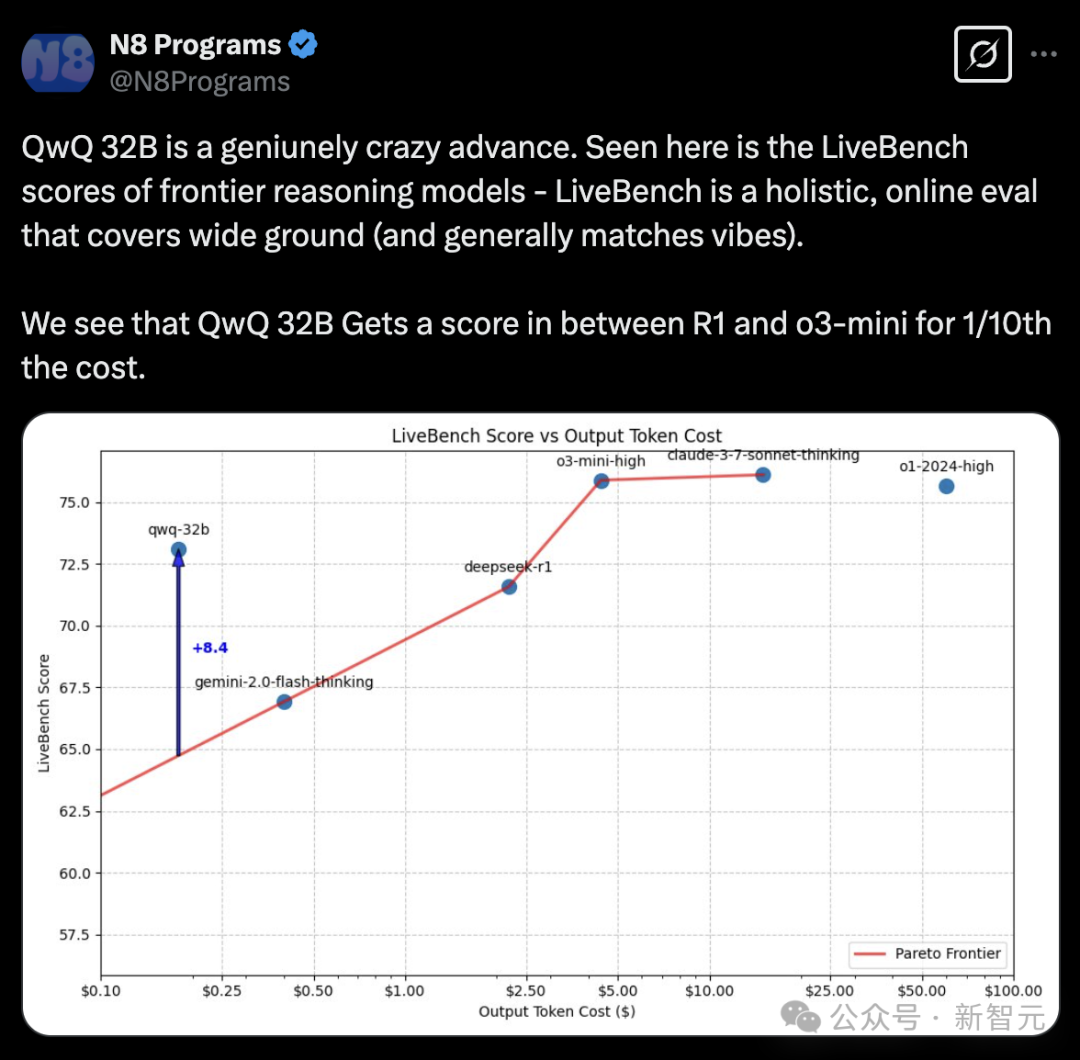
Nous Research的常驻研究员N8 Programs在X上称赞QwQ-32B真是一个令人难以置信的进步。
他展示的是前沿推理模型在LiveBench上的得分(下图)——LiveBench是一个全面的在线评估测试,覆盖了广泛的领域(并且通常与实际情况相符)。
可以看到,QwQ-32B的得分介于R1和o3-mini之间,但成本却只有它们的十分之一。
强化学习「炼丹」,小模型也能逆袭
DeepSeek爆火之后,强化学习再次回到聚光灯之下,成为提升大模型/推理模型的关键钥匙。

不过,与传统方法不同的是,他们采用了多阶段RL训练策略。
在初始阶段,基于冷启动数据,针对数学、编程、通用任务上,进行了强化学习训练。
相较于传统的奖励模型,团队创新性通过校验答案正确性(数学任务)和代码执行测试(编程任务)提供反馈,确保模型逐步「进化」。
在RL Scaling过程中,随着训练轮次推进,模型在数学、编程两个领域的性能持续提升。
在第二阶段,研究人员又针对通用能力进行了RL训练,主要使用通用奖励模型和一些基于规则的验证器进行训练。
实验显示,通过少量步骤的通用 RL,可以提升QwQ-32B的通用能力,最关键的是,其数学、编程性能没有显著下降。
QwQ-32B仅在320亿参数规模下,推理能力直逼DeepSeek-R,恰恰验证了「大规模强化学习+强大基座模型」是通往AGI的关键路径。
此外,QwQ-32B不只是一个推理模型,还集成了先进的Agent相关能力。不仅在使用工具时批判性思考,还能根据环境反馈动态调整策略。
下一步,阿里还将继续探索智能体与强化学习的深度融合,目标直指长时推理,最终实现AGI。
开源先锋,引领全球AI新格局
在全球人工智能浪潮席卷之下,开源早已成为推动技术创新的重要引擎。
作为国内最早开源自研大模型的「大厂」,阿里云也是全球唯一一家积极研发先进AI模型,且全方位开源的云计算厂商。
自2023年8月以来,通义系列累计推出了从Qwen、Qwen1.5、Qwen2到Qwen2.5数十款大模型,覆盖5亿到千亿级别的参数规模,并开源了超200款模型,支持29种语言。
这一壮举,标志着阿里云在业界率先实现了「全尺寸、全模态、多场景」的开源。
开源的Qwen系列凭借卓越的性能,数次登顶国内外权威榜单,还多次冲上HuggingFace、Github热榜,成为开发者心中的「爆款」。
2024年,仅Qwen2.5-1.5B一款模型就占据了HuggingFace全球模型下载量的26.6%,位列第一。
才刚刚开源的QwQ-32B,就已经有众多来自不同国家、说着不同语言的的开发者,在第一时间都直接用上了,而且好评如潮。
左右滑动查看
我们都知道,开源的真谛在于,众人拾柴火焰高。
目前,Qwen衍生模型数量突破10万,远超Llama系列,成为全球最大的生成式语言模型族群。
阿里云的开源战略不仅体现在技术输出,更在于推动普惠AI的初心——让中小企业和开发者能够以最低成本、更快速度用上AI,加速大模型应用落地。
另外,通过魔搭ModelScope社区,阿里云还联合1000万开发者,打造出中国最大的AI开源生态。
阿里云坚信,开源是推动技术创新的关键。
通义千问系列的开源,不仅仅是一场技术狂欢,更是一次生态革命。从技术突破到生态赋能,他们正用实际行动诠释了技术普惠的深刻内涵。
正如其愿景所言,通过开源与合作,推动中国大模型生态的繁荣,助力全球AI技术迈向新高度。
在这条路上,通义千问无疑成为一颗耀眼的明星,照亮了AI的未来。
(文:新智元)