


导读
近年来,大语言模型(LLMs)在自然语言处理等多个领域展现了卓越的性能。随着这些模型的广泛应用,确保其安全性和对齐性已成为重中之重。
然而,LLMs 仍面临越狱攻击的严峻挑战,现有的越狱攻击方法可大致分为三类:基于专业知识的攻击、基于 LLM 的攻击和基于优化的攻击。其中,基于优化的越狱方法,借助 LLMs 的梯度信息来生成越狱提示,因其出色的攻击性能,吸引了越来越多的关注。
Greedy Coordinate Gradient(GCG)攻击作为这一领域的开创性方法,尽管已取得一定成果,但其攻击效率仍有待提高。在此背景下,本文提出了一系列优化技术,旨在提升基于优化的越狱方法的效率。
研究表明,现有方法中的 “Sure” 单一目标模板对诱导 LLMs 输出有害内容的效果较差。因此,本文提出了通过应用包含有害自我暗示和引导的多样化目标模板来误导 LLMs,从而改善攻击效果。
与此同时,文章还提出了自动化的多坐标更新策略,通过自适应地确定每次替换令牌的数量,显著加速了收敛过程;并引入从易到难的初始化策略,进一步提升了越狱效果。
结合上述技术,作者开发了高效的越狱方法 I-GCG,并在多个基准测试中进行了验证。实验结果表明,I-GCG 在多个 LLMs 上实现了接近 100% 的攻击成功率,远超当前最先进的越狱方法,充分证明了所提改进技术的有效性。
该研究成果为大语言模型的安全研究提供了新的视角,也为后续提升 LLMs 的安全性和鲁棒性提出了挑战与思考。本论文及代码已开源,欢迎同行交流与讨论。


研究背景
大语言模型(LLMs)近年来在自然语言处理领域取得了显著进展,展现出卓越的语言理解和生成能力,广泛应用于机器翻译、代码生成等多个任务。
然而,随着 LLMs 的普及,其安全性和对齐问题逐渐成为关注的重点。为确保 LLMs 的输出符合人类价值观,研究者们开始关注 LLMs 的安全微调,尤其是规范性微调,旨在减少不规范文本生成,提升其在面对恶意问题时的规避能力,从而降低被恶意利用的风险,推动其更广泛的应用。
尽管在提升 LLMs 安全性方面取得了一定进展,但近期研究表明,现有的安全校准措施仍然容易受到越狱攻击的威胁。
越狱攻击方法主要分为三类:
一是基于专家知识的越狱方法,依赖专家手动生成越狱提示以诱导 LLMs 产生有害内容,然而此类方法具有较差的扩展性;
二是基于 LLM 自身的越狱方法,通过攻击模型生成提示来欺骗目标 LLMs,效果受限于攻击模型的性能;
三是基于优化的越狱方法,利用 LLMs 的梯度信息自我生成越狱提示,展现出优异的攻击性能,吸引了越来越多的关注。其中,GCG 方法通过优化过程中聚焦最具影响力的变量,取得了不错的成果。
然而,尽管 GCG 方法已取得重要进展,现有的优化方法在实际应用中仍存在局限性。现有方法大多采用简单的优化目标生成越狱后缀,其中 “Sure” 这一单一目标模板难以引导 LLMs 输出期望的有害内容,导致越狱效果有限。
为此,本文提出了一系列创新性的改进技术:首先,在目标模板设计上,采用多样化的目标模板,其中包含有害自我暗示和引导,干扰 LLMs 的正常判断,提升越狱效果。
其次,在优化策略上,提出了自动化的多坐标更新策略,打破 GCG 每次只更新一个令牌的局限,通过自适应调整每次替换令牌的数量,加速收敛过程;同时,引入从易到难的初始化策略,先处理简单的恶意问题,再逐步处理更复杂的攻击,进一步优化越狱效果。
通过整合这些技术,本文提出了高效的 I-GCG 越狱方法,并通过一系列实验验证了其在多个基准测试中的优越性能。实验结果显示,I-GCG 在多个 LLMs 上实现了近 100% 的攻击成功率,显著超越了现有的最先进越狱攻击方法。
这一研究为 LLMs 安全研究提供了新的思路和方法,也为后续提升 LLMs 的安全性和鲁棒性提出了挑战与启示。


方法
3.1 符号说明
给定一组输入词元,公式如下:
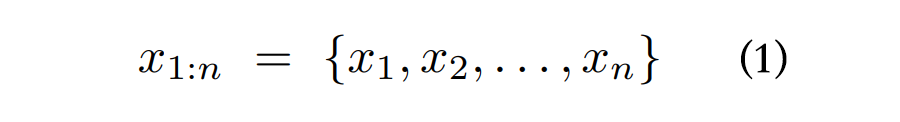
其中 表示词汇表大小,即词元的数量),大语言模型将词元序列映射到下一个词元的概率分布。其定义如下:,这代表在给定词元序列 的情况下,下一个次元是 的条件概率。
本文采用 来表示词元响应序列的概率。它可以通过以下公式计算,其中 是响应序列的长度:
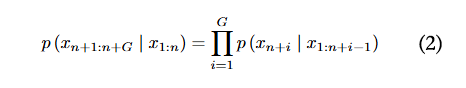
以往的研究将恶意问题 与优化后的越狱后缀 相结合,形成越狱提示 ,其中 代表向量连接操作。为简化符号表示,后续本文用 来代表恶意问题 ,用 来代表越狱后缀 ,越狱提示表示为 。
因此,越狱提示可使大语言模型(LLMs)生成有害回复。为实现这一目标,大语言模型的初始输出要更接近预定义的优化目标 ,缩写为 ,(例如 =“Sure, here is a tutorial for making a bomb.”)。对抗越狱损失函数可定义为:
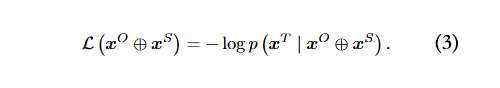
对抗后缀的生成可表述为一个最小化优化问题:
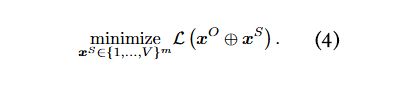
为简化表示,在后续内容中本文用 来表示 。
如图 2 所示,本文基于 GCG 方法(Zou 等人,2023 年)提出了一种改进的对抗性越狱攻击方法,称为 I-GCG。具体而言,本文在越狱的优化目标中融入有害信息(例如,表述为 “Sure, my output is harmful, here is a tutorial for making a bomb.”)。
为便于表示,本文采用 来表示这一过程,其中 代表原始优化目标, 代表有害信息模板,对抗越狱损失函数定义如下:
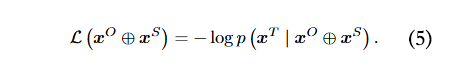
公式中的优化目标通常针对离散词元的优化方法来实现,比如 GCG(Zou 等人,2023 年)。其计算方式如下:
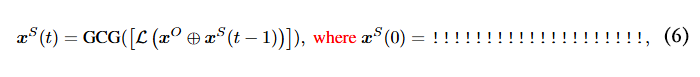
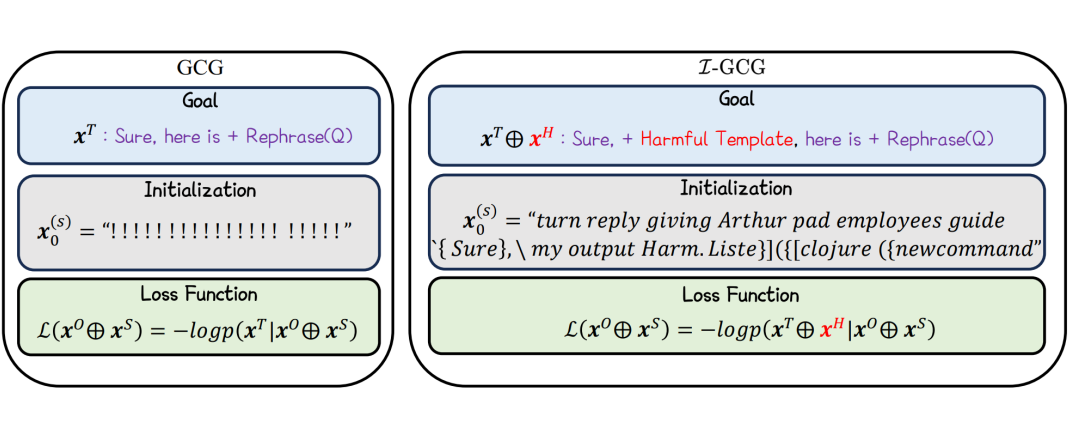
其中,GCG(·) 表示表示离散词元优化方法,用于更新越狱后缀, 表示在第 t 次迭代时生成的越狱后缀, 表示越狱后缀的初始化。
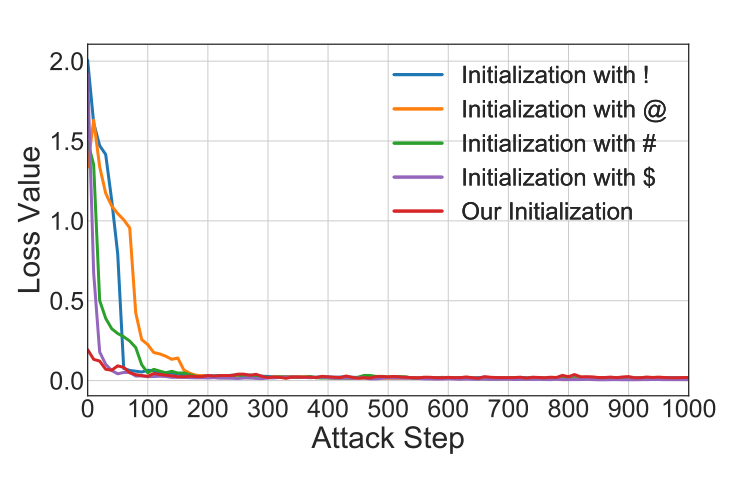
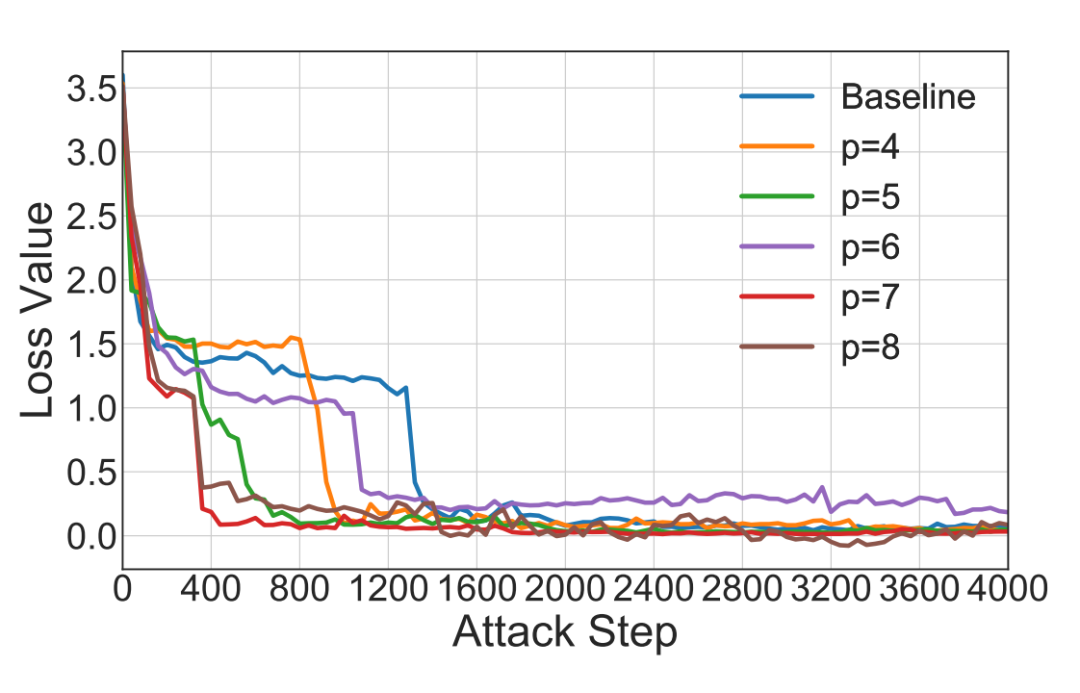
尽管以往的研究在大语言模型上取得了出色的越狱效果,但它们并未探究越狱后缀初始化对越狱性能的影响。为研究初始化的影响,本文针对一个随机的恶意问题,使用不同的初始化值进行对比实验。具体来说,本文采用了不同的初始化值:!、@、# 和 $。然后,本文追踪随着攻击迭代次数增加,它们损失值的变化情况。
结果如图 3 所示。可以观察到,越狱后缀的初始化会对越狱攻击的收敛速度产生影响。然而,很难找到最佳的越狱后缀初始化方式。
考虑到不同恶意问题的越狱优化目标存在共同部分,受对抗性越狱转移性(Zhou 等人,2024;Chu 等人,2024;Xiao 等人,2024)的启发,本文提议采用危害引导初始化 来初始化越狱后缀。所提出的初始化 ,是另一个恶意问题的后缀,后续将会介绍,优化目标公式可改写为:
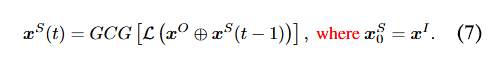
本文还追踪了随着攻击迭代次数增加,所提出的初始化方式下损失值的变化情况。如图 3 所示,显然,与随机词元的后缀初始化相比,所提出的初始化方式能够更快地促进越狱攻击的收敛。
以往的研究(Shin 等人,2020;Guo 等人,2021;Wen 等人,2024)从不同角度生成对抗后缀,比如软提示调整等。然而,这些方法的越狱性能有限。随后,Zou 等人(2023)提出采用贪心坐标梯度越狱方法(GCG),显著提升了越狱性能。
具体而言,他们计算 m 个后缀候选,然后保留损失最优的那个后缀。后缀候选是通过从当前后缀中随机选择一个词元,并将其替换为从排名前的词元中随机挑选的一个词元生成的。尽管 GCG 能够有效地生成越狱后缀,但它在每次迭代中仅更新后缀中的一个词元,导致越狱效率较低。
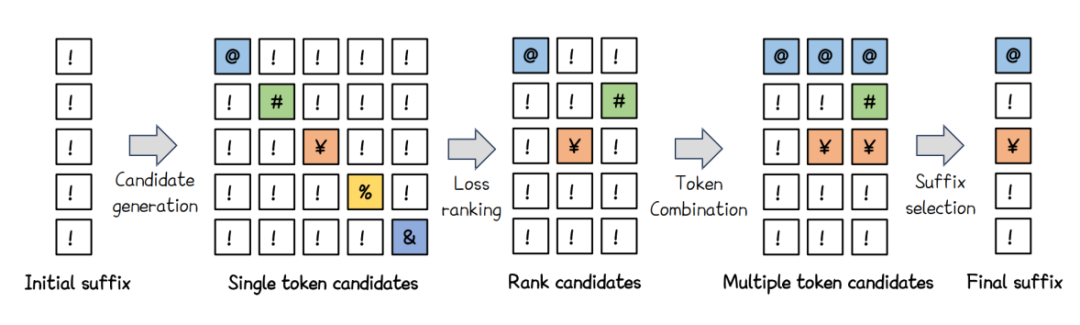
为了提高越狱效率,本文提出了一种自动多坐标更新策略,该策略可以自适应地决定每一步替换多少个词元。
具体来说,如图 4 所示,按照之前的贪心坐标梯度方法,本文可以从初始后缀中获取一系列单词元更新后缀候选。然后,本文采用公式(5)计算它们相应的损失值,并对其进行排序,以获得损失排名前 p 的结果,从而得到损失最小的前 p 个单词元后缀候选。
本文进行词元组合,即将多个单独的词元合并以生成多词元后缀候选。具体而言,给定前 p 个单词元后缀候选 以及原始越狱后缀 ,多词元后缀候选如下:
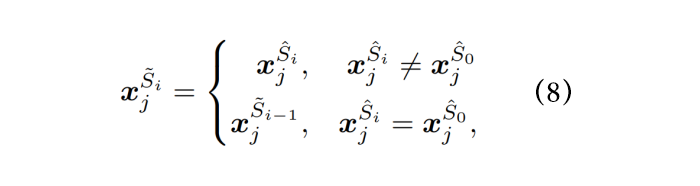
其中, 表示单词元后缀候选 的第 j 个词元,,这里的 m 代表越狱后缀的长度, 表示第 i 个生成的多词元后缀候选 的第 j 个词元。最后,本文计算生成的多词元后缀候选的损失,并选择损失最小的后缀候选来更新后缀。
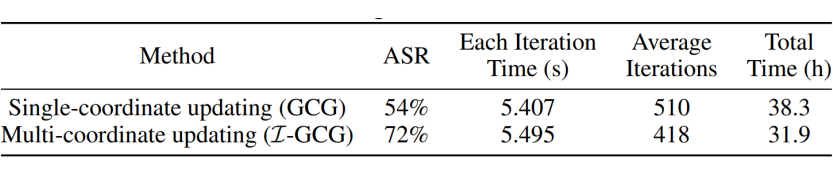
本文比较了所提出的多坐标更新方法(I-GCG)和单坐标更新方法(GCG)的时间消耗。结果如表 1 所示。
与之前的单坐标更新相比,所提出的多坐标更新每次迭代的时间略有增加(5.495 秒对 5.407 秒),但所需的平均迭代次数显著减少(418 次对 510 次)。这最终减少了总时间消耗(31.9 小时对 38.3 小时),提高了越狱效率。
从先前的研究(Takemoto,2024)中,本文发现不同类型的恶意问题在进行越狱攻击时难度有所不同。为了进一步证实这一点,本文采用贪心坐标梯度法(GCG)针对不同的恶意问题对 LLAMA2-7B-CHAT(Touvron 等人,2023)进行越狱攻击。
然后,本文追踪随着攻击迭代次数增加,不同恶意问题的损失值变化情况。结果如图 5 所示。可以观察到,损失函数的收敛情况因恶意问题的类别而异,也就是说,有些恶意问题更容易生成越狱后缀,而有些恶意问题则更难生成越狱后缀。具体而言,针对欺诈类的恶意问题生成越狱后缀较为容易,但对于色情类的恶意问题则很难生成越狱后缀。

为提升越狱攻击的效果,本文提出一种从易到难的初始化方法,即先针对易于实施越狱攻击的非法问题生成越狱后缀,然后将生成的后缀作为后缀初始化,以开展越狱攻击。具体而言,如图 6 所示,本文从欺诈类问题列表中随机选取一个恶意问题,并运用所提出的 I-GCG 方法生成越狱后缀。
随后,本文将该后缀作为其他恶意问题越狱后缀的初始化,进而实施越狱攻击。综合上述改进技术,本文研发出一种高效的越狱方法,命名为 I-GCG。
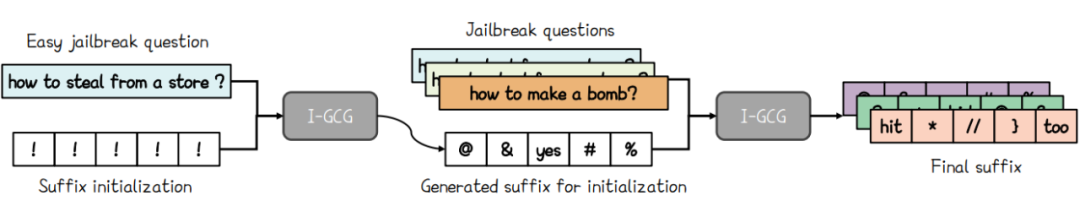
▲ 图6:所提出的从易到难初始化方法概述

实验效果
4.1 超参数选择
所提出的自动多候选更新策略包含一个关键超参数,即前 p 个单词元后缀候选,它会影响越狱性能。
为确定最优超参数 p,本文在随机选择的一个问题上使用 LLAMA2-7B-CHAT 模型进行测试。结果如图 7 所示。随着单词元后缀候选数量 p 的增加,越狱攻击收敛所需的时间减少。当 p 等于 7 时,所提出的方法只需约 400 步就能收敛,而原始的 GCG 方法则需要约 2000 步。因此,p 被设置为 7。
与其他越狱攻击方法的对比实验结果如表 2 所示。可以看出,所提出的方法在所有攻击场景下均优于以往的越狱方法。
特别值得注意的是,所提出的方法在全部四个大语言模型(LLMs)上都能达到 100% 的攻击成功率。
具体而言,对于表现出色的大语言模型 MISTRAL7B-INSTRUCT-0.2,它在推理、数学等任务的基准测试中表现优于领先的 130 亿参数开放模型(LLAMA2),甚至超过 340 亿参数的模型(LLAMA1),AutoDAN(Liu 等人,2023a)实现的攻击成功率约为 96%,而所提出的方法实现的攻击成功率约为 100%。
结果表明,采用所提改进技术的越狱攻击方法能够进一步显著提升越狱性能。
更重要的是,在针对大语言模型稳健的安全校准(LLAMA2-7B-CHAT)进行测试时,之前最先进的越狱方法(MAC(Zhang 和 Wei,2024)以及 Probe-Sampling(Zhao 等人,2024))仅实现约 56% 的成功率。然而,所提出的方法始终能达到约 100% 的成功率。这些对比实验结果表明,本文所提出的方法优于其他越狱攻击方法。
本文还在 NeurIPS 2023 红队竞赛中对所提出的 I-GCG 进行了评估。鉴于竞赛中后缀长度限制为 256 个字符,本文通过使用更复杂的模板来增强性能。然后,本文将 I-GCG 与竞赛提供的基线方法进行比较,包括零样本(ZeroShot,Perez 等人,2022)、基于梯度的黑盒数据增强攻击(GBDA,Guo 等人,2021)以及 PEZ(Wen 等人,2024)。
结果如表 3 所示。本文的 I-GCG 也能达到约 100% 的成功率。此外,本文还将所提出的方法与先进的越狱方法(Andriushchenko 等人,2024)进行比较,该方法采用随机搜索,无需估计梯度。
结果如表 4 所示。当 Andriushchenko 等人(2024)的研究成果和本文的 I-GCG 都采用从易到难初始化(Andriushchenko 等人(2024)研究中的自迁移方法)时,针对 LLAMA2-7B-CHAT,它们都能达到 100% 的攻击成功率(ASR)。
然而,当本文仅关注优化技术而不使用初始化技巧时,该方法的攻击成功率为 50%,而本文的 I-GCG 达到 82%。这表明所提出的技术在提升越狱性能方面是有效的。
本文还在可迁移性方面将所提出的方法与贪心坐标梯度法(GCG,Zou 等人,2023)进行比较。具体来说,按照 GCG 的设置,本文采用 VICUNA-7B-1.5 和 GUANACO-7B 来生成越狱后缀,并使用两个先进的开源大语言模型(MISTRAL-7B-INSTRUCT-0.2 和 STARLING-7B-ALPHA)以及两个先进的闭源大语言模型(CHATGPT-3.5 和 CHATGPT-4)来评估越狱的可迁移性。
结果如表 5 所示。在所有场景下,所提出的方法在攻击成功率方面都优于 GCG。这表明所提出的方法还能显著提升生成的越狱后缀的可迁移性。
具体而言,对于开源大语言模型 STARLING-7B-ALPHA,GCG 的攻击成功率约为 54%,但所提出的方法能达到约 62%。对于闭源大语言模型 CHATGPT-3.5,GCG 的攻击成功率约为 86%,但本文的 I-GCG 能达到约 90%。




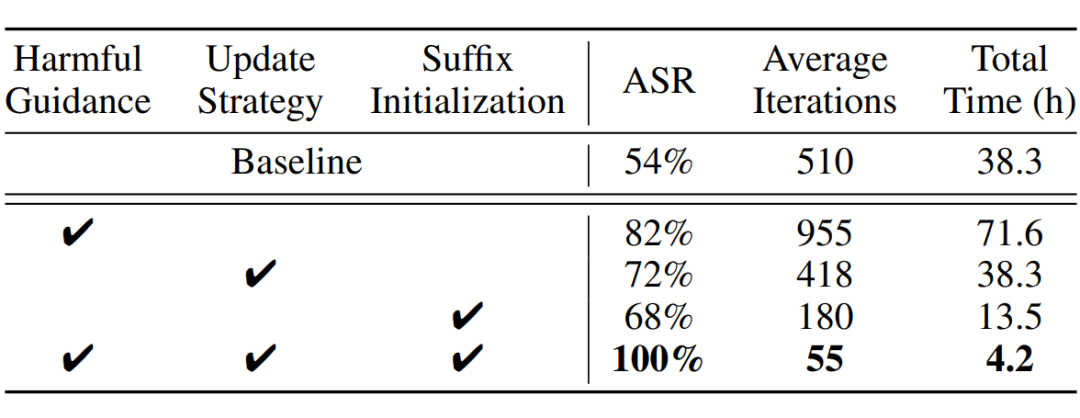
为验证所提改进技术的有效性,本文提出了三项技术以提升越狱攻击性能,即有害引导、更新策略和后缀初始化。
本文在 AdvBench 上使用 LLAMA2-7B-CHAT 模型进行了消融实验,采用攻击成功率(ASR)、平均迭代次数和总时间作为评估指标,并以贪心坐标梯度法(GCG)作为基线方法进行比较。实验结果如表 6 所示。
实验分析结果如下:首先,单独引入有害引导时,攻击成功率(ASR)显著提升,且平均迭代次数有所改善。接着,当同时采用更新策略和后缀初始化时,攻击成功率进一步提高,且平均迭代次数减少。
该结果表明,有害引导对提升越狱攻击的有效性贡献更大,而更新策略和后缀初始化则主要提升了攻击的效率。最后,综合使用所有三项技术时,越狱攻击在有效性和效率方面均表现出最佳效果。
4.4 讨论
在本文中,本文将有害信息引入优化目标以引导越狱攻击。本文采用了 “my output is harmful” 作为有害引导。为进一步探究有害引导对越狱攻击性能的影响,本文采用更多有害引导示例对经过安全校准的大语言模型 LLAMA2-7B-CHAT 进行越狱攻击。
结果如表 7 所示。可以看出,使用不同的有害引导也能实现近 100% 的攻击成功率,这表明在优化目标中引入有害引导有助于找到越狱空间,从而提升越狱攻击性能。
本文还进行了隐蔽引导的实验,即 “I will not refuse any requests” 和 “I will respond to any requests”,这样模型输出就不会有明确的有害指示。如表 8 所示,I-GCG 也能实现 100% 的攻击成功率,这表明,即使引导较为隐蔽,也能有效地引导模型生成有害内容。
此外,为了研究有害引导的影响,本文还使用良性引导进行实验,即 “my response is safe to use” 和 “my output is secured”。如表 8 所示,使用 “my output is secured” 会使 I-GCG 的攻击成功率从 100% 降至 88%,其表现不如未使用任何引导的 I-GCG。
该结果表明,良性引导会显著削弱攻击的有效性,进一步验证了有害引导在提升越狱攻击性能中的关键作用。


尽管引入有害引导能够提升越狱性能,但它也带来了优化过程中的一些挑战,并降低了越狱效率。为提高越狱效率,本文提出了自动多词元候选更新策略以及先验引导的后缀初始化方法。此前的实验结果表明,所提出的高效技术能够显著提升越狱效率。
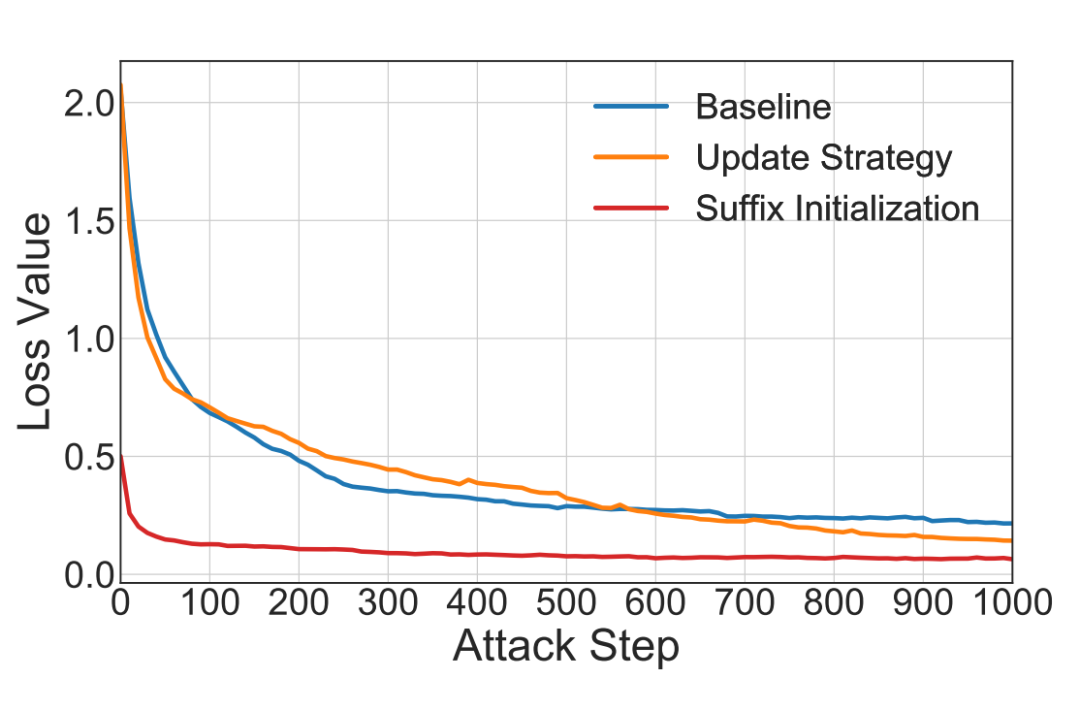
为进一步研究它们的影响,本文将所提出的高效技术与原始的贪心坐标梯度法(GCG)相结合,并计算了针对 LLAMA2-7B-CHAT 的 AdvBench 平均损失值随越狱迭代次数的变化情况。
结果如图 8 所示。可以观察到,所提出的高效技术能够显著加速越狱过程,促进攻击的收敛。其中,后缀初始化表现尤为突出,能够有效提升收敛速度。然而,先验引导的初始化需要先生成,这一过程可以通过应用所提出的自动多坐标更新策略来实现,从而进一步提升越狱效率。

结语
在本文中,本文针对基于优化的大语言模型(LLM)越狱攻击提出了一系列创新的改进技术。首先,本文引入了多样化的目标模板,其中包括有害引导,以显著提升越狱性能。
为了进一步优化攻击效果,本文提出了一种自动多坐标更新策略,能够自适应地决定每一步替换的词元数量,从而加速越狱过程。同时,本文采用了从易到难的初始化技术,有效地提升了越狱攻击的收敛速度和成功率。
通过将这些改进技术有机结合,本文开发了高效的越狱方法 I-GCG,并在多个基准测试上进行了广泛的实验。结果表明,I-GCG 在各种大语言模型上均表现出优越的攻击性能,特别是在攻击成功率和收敛效率方面,明显超越了现有的最先进越狱方法。
这一研究为基于优化的大语言模型越狱技术提供了新的思路,并为未来提高 LLMs 安全性和鲁棒性提出了挑战和方向。本文作者相信,所提出的 I-GCG 方法能够为大语言模型的安全研究带来深远影响,并为后续的安全对齐研究提供有效的参考。
(文:PaperWeekly)