复旦 NLP 实验室博士后纪焘是这篇文章的第一作者,研究方向为大模型高效推理、多模态大模型,近期代表工作为首个NoPE外推HeadScale、注意力分块外推LongHeads、多视觉专家大模型MouSi,发表ACL、ICLR、EMNLP等顶会顶刊论文 20 余篇。
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。
然而,现有主流大模型仍然基于标准注意力架构及其变种(e.g., MHA, GQA, MQA),推理成本相比 MLA 呈现显著劣势。使预训练的任意 LLMs 快速迁移至 MLA 架构而无需从头预训练,这既有重大意义又具有挑战性。
复旦 NLP 实验室、华东师大、上海 AI Lab、海康威视联合提出 MHA2MLA 框架,通过部分 RoPE 保留(Partial-RoPE)和键值联合表示低秩近似(Low-rank Approximation)两个关键步骤,成功将任意 MHA/GQA 架构迁移到 MLA。
目前,MHA2MLA 已位列🚀alphaXiv 热度榜🔥
复旦 NLP 实验室博士后纪焘为第一作者,副研究员桂韬为通讯作者。
-
论文标题:Towards Economical Inference: Enabling DeepSeek’s Multi-Head Latent Attention in Any Transformer-based LLMs
-
论文链接:https://arxiv.org/abs/2502.14837
-
开源代码:https://github.com/JT-Ushio/MHA2MLA
本文聚焦如何将预训练的基于 MHA/GQA 的大语言模型高效迁移到 DeepSeek 提出的经济推理架构 —— 多头潜在注意力(MLA)。
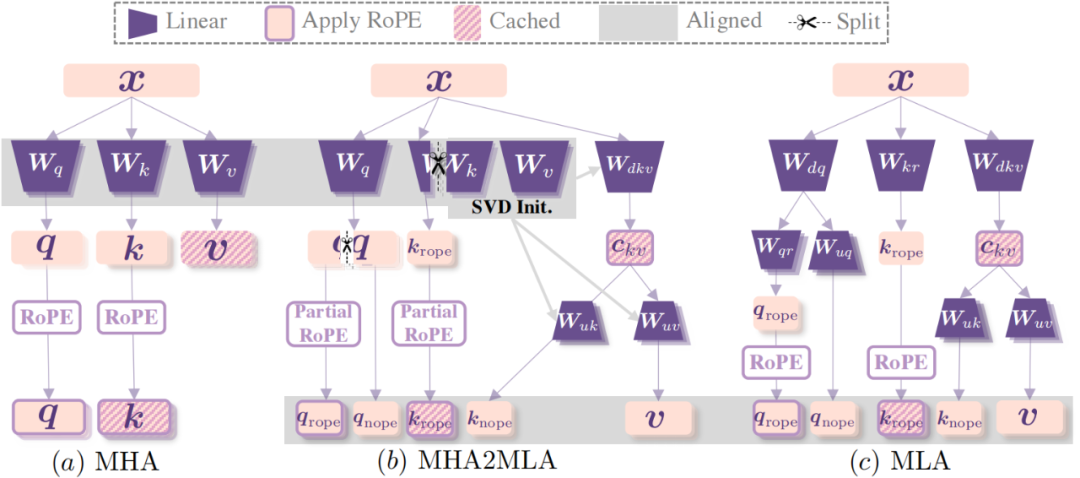
MHA 与 MLA 在多处存在差异,使得 MHA2MLA 极具挑战:
-
位置编码不同:MHA 采用全维度位置编码(PE),MLA 仅少量维度采用 PE,剩余维度则 PE 无关
-
缓存对象不同:MHA 缓存分离的键向量及值向量,MLA 缓存带 PE 的键向量及 PE 无关的键值联合低维表示向量
-
参数矩阵不同:MHA 包含查询、键、值三个线性变换矩阵,MLA 则更加复杂、多达七个目的不同的线性变换矩阵
-
运算形式不同:MHA 的运算受限于访存瓶颈,MLA 则能通过矩阵吸收等优化实现更高的访存效率
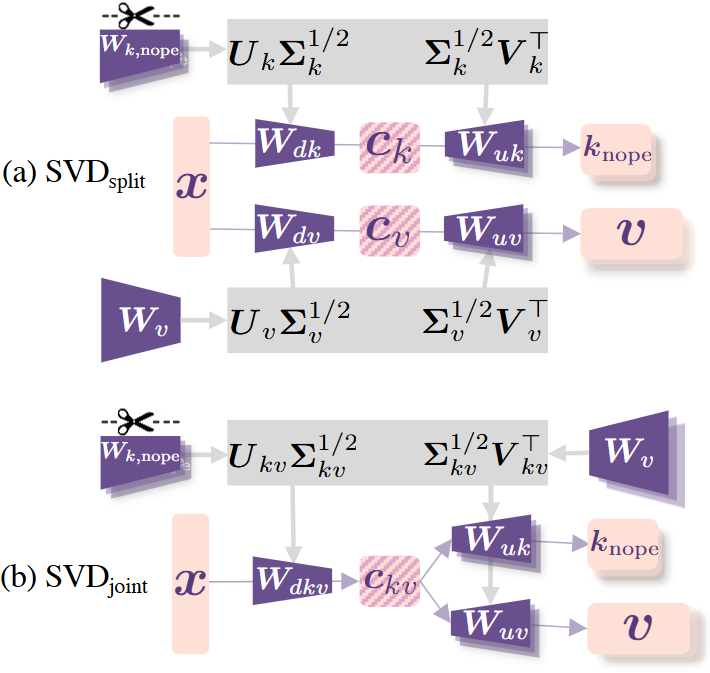
本文提出的 MHA2MLA 为了最大化利用 MHA 预训练参数矩阵并对齐 MLA 的缓存对象和运算形式,首先通过部分 RoPE 保留(Partial-RoPE)分离出 PE 相关表示(少量维度,如 1/8)和 PE 无关表示(大量维度),其中 PE 相关的键向量对齐 MLA。其次拼接值的变换矩阵(W_v)和 PE 无关的键的变换矩阵(W_{k, nope}),并进行 SVD 分解得到降维变换矩阵和升维变化矩阵,中间的键值联合低秩表示对齐 MLA,完成了缓存对象的对齐以及运算形式的对齐。
在 135M~7B 上的实验表明,仅需使用预训练数据的 0.3% 到 0.6% 进行高效微调,即可基本还原架构迁移带来的性能损失。并且 MHA2MLA 还能结合其他高效推理技术,例如结合 4-bit KV 缓存量化,Llama2-7B 减少了 92.19% KV 缓存,而 LongBench 上的性能仅下降 0.5%。
为了实现从标准的 MHA(多头注意力机制)到 MLA(多头潜在注意力机制)的迁移,作者提出了部分 RoPE 微调(partial-RoPE finetuning)策略,该策略通过从大量维度中移除 RoPE(旋转位置编码)并将其转换为 NoPE(无位置编码)来解决 MLA 和 RoPE 冲突的问题。
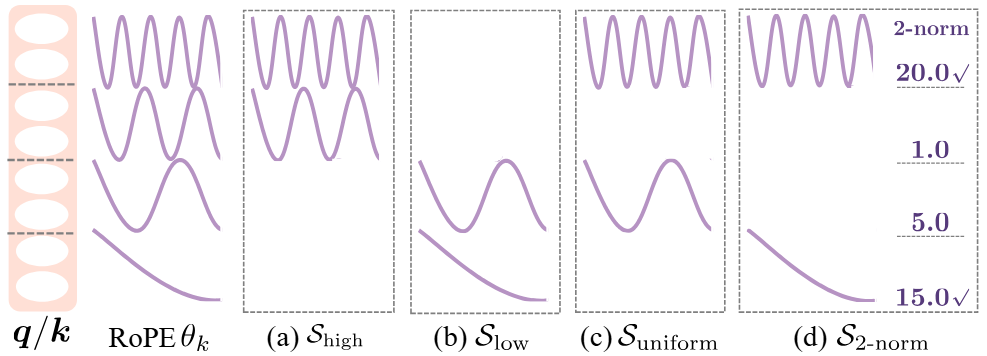
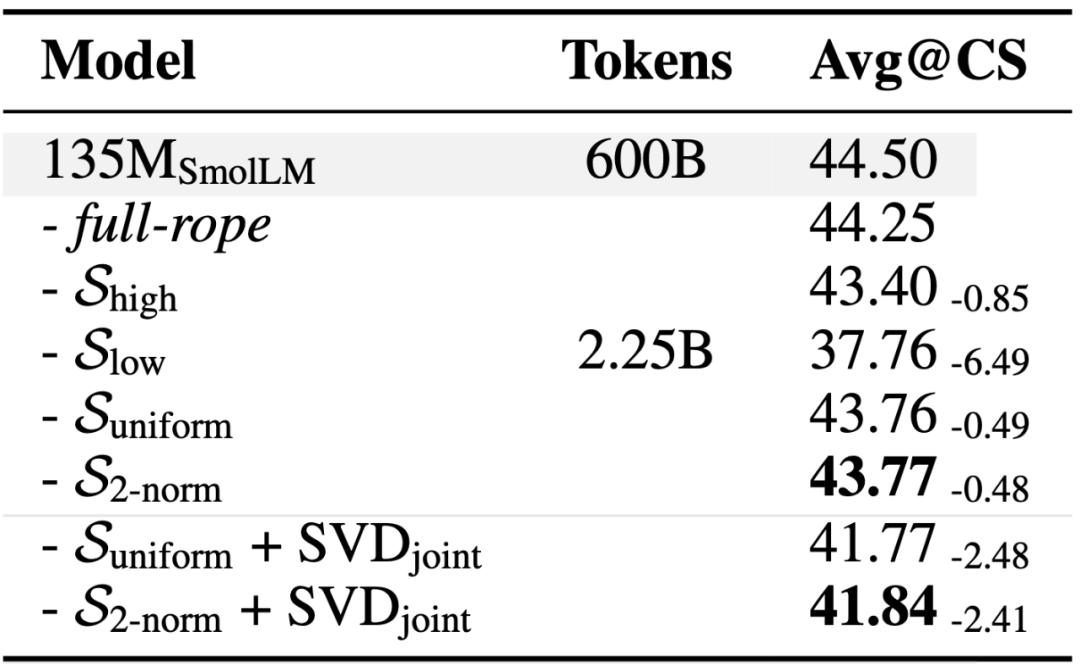
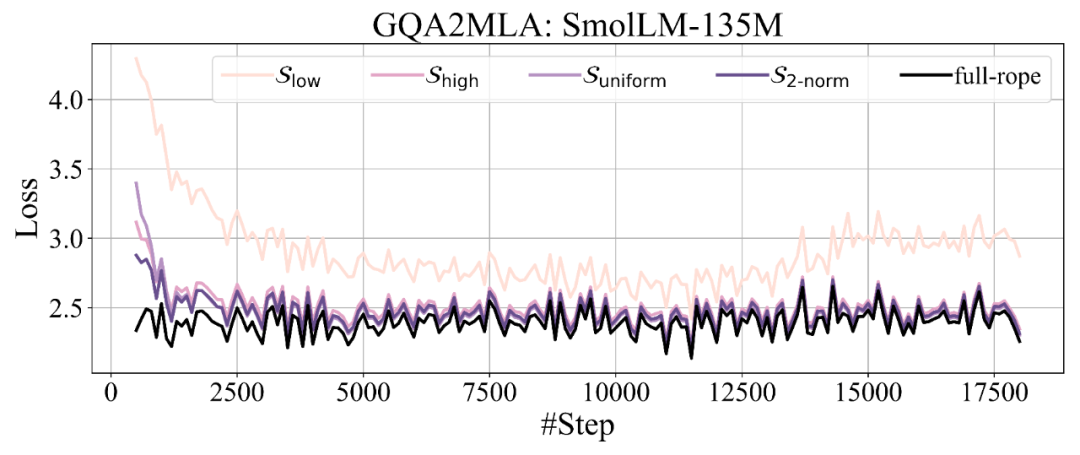
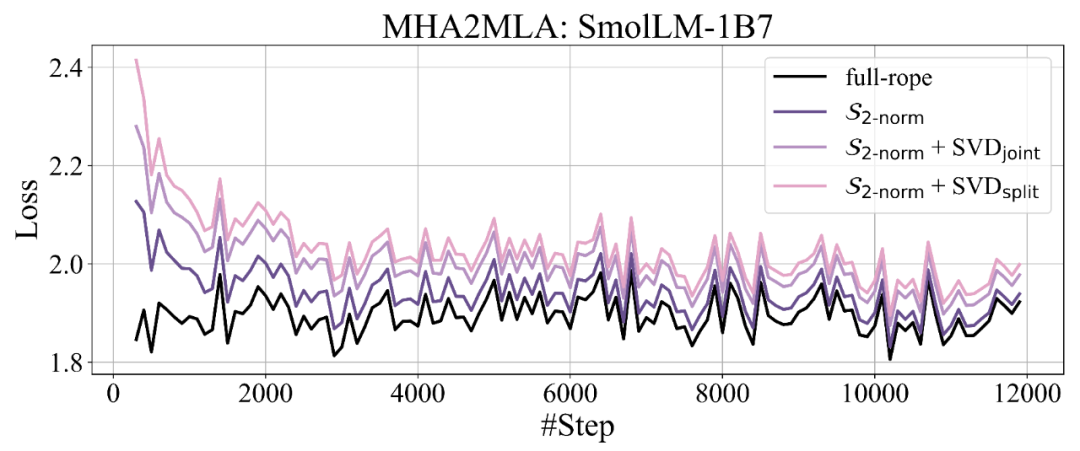
作者主要尝试了四种移除 RoPE 的策略:1)保留高频位置信息 S_high,该方法最简单直接,保留了局部语义特征相关的高频特征 [2];2)保留低频位置信息 S_low,与保留高频位置信息的策略形成对比,检验低频成分在语义理解任务中的潜在作用;3)均匀采样策略 S_uniform,等间隔均匀采样频率保留位置频率;4)使用查询、键向量范数乘积 (2-norm) 近似注意力贡献值 [2] 的筛选策略 S_{2-norm},针对每个注意力头,计算所有频率的平均 2-norm 分数,随后选择得分较高的频率保留位置信息。该策略能自适应识别对模型性能关键的特征频率。
Partial-RoPE 的消融实验表明:1)保留低频位置信息的 S_low 导致了最大的性能损失,保留高频位置信息的 S_high 导致的性能损失明显小于保留低频,说明了高频维度的重要性;2)S_uniform 和 S_{2-norm} 均展现出更优的性能,分别在 135M 模型和 1.7B 模型上取得了最少的性能损失。最终作者选择 S_{2-norm} 作为默认配置,是因为注意力贡献分数较低的维度在结合低秩近似时损失更少。
移除了大量维度的 RoPE 之后,MHA2MLA 就可以对值向量和 PE 无关的键向量进行低秩近似,从而大幅减少缓存空间。为最大化保留预训练知识,本文提出两种基于奇异值分解 (SVD) 的投影矩阵初始化策略:1)SVD_split,分别对矩阵进行低秩分解,保持各自的表征特性;2)SVD_joint,考虑键值矩阵之间的关联性,参数矩阵拼接后整体进行低秩分解。
消融实验表明:无论是在 GQA 基座还是 MHA 基座上,SVD_joint 方法始终优于 SVD_split 方法。
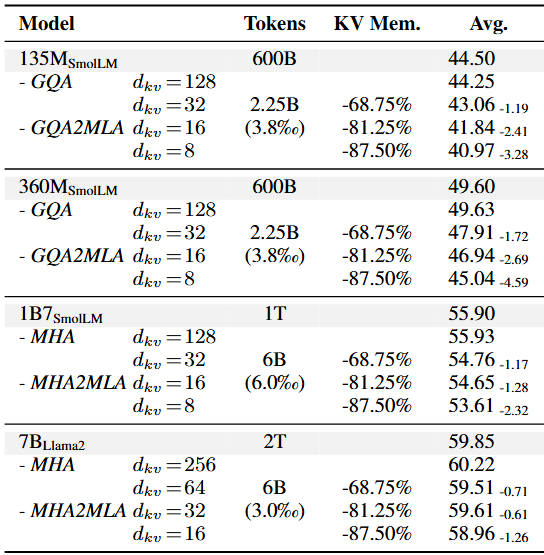
作者在多种规模的语言模型(SmolLM-135M/360M/1B7 和 Llama2-7B)以及不同压缩比例的配置下评估了所提出的方法。实验表明:1)相同微调设置下,压缩比例越高,性能损失越大,特别是对于两个 GQA 模型;2)相同压缩比例下,原始模型参数越多,性能损失越小,揭示了 MHA2MLA 的潜在 scaling law。3)MHA2MLA 的微调数据量仅需预训练数据的 0.3%~0.6%,避免了从头预训练 MLA 模型的高昂成本。
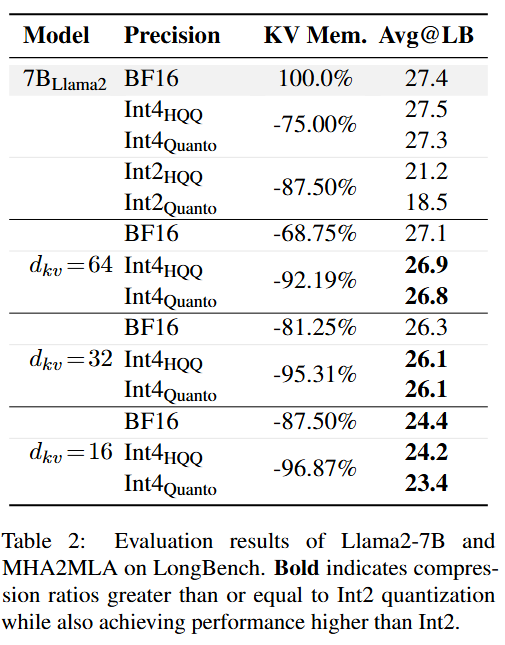
作者在 LongBench 长文本生成任务中评估了结构迁移后的 Llama2-7B 模型,将 KV 缓存量化作为基准对比方案。实验表明,MHA2MLA 能在 d_{kv}=16 的情况下实现与 2-bit 量化相同的压缩比例(87.5%),同时仅损失一半的性能(-3.0% vs. -6.2%);进一步结合 4-bit 量化后,不仅压缩比例超过 2-bit 量化,性能损失也都优于所有 2-bit 的基线方法,例如 92.19% 压缩比例仅掉 0.5%,96.87% 压缩比例仅掉 3.2%,证明了 MHA2MLA 能显著减少推理时的访存瓶颈。
本文主要研究如何将基于 MHA 的预训练 LLMs(或其变体)适配为 KV 缓存高效的 MLA 架构,以显著降低推理时的访存瓶颈。通过精心的架构设计,MHA2MLA 仅需 0.3% 至 0.6% 预训练数据。该框架展现了与现有压缩技术的强兼容性,同时保持了常识推理和长上下文处理能力,为部署资源高效的 LLMs 提供了一条实用路径。
作者提到该研究受限于硬件条件,当前实验未能覆盖 Llama3 等需 128K 长上下文微调的模型,也未突破 7B 参数规模的验证瓶颈。扩展至更多的基座将作为未来工作之一。作者还计划结合参数高效微调策略,进一步降低架构迁移过程中的参数更新规模。
[1] DeepSeek-AI, Aixin Liu, Bei Feng et al.DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. ArXiv preprint.
[2] Federico Barbero, Alex Vitvitskyi, Christos Perivolaropoulos, Razvan Pascanu, Petar Veličković. Round and Round We Go! What makes Rotary Positional Encodings useful? CoRR 2024
(文:机器之心)