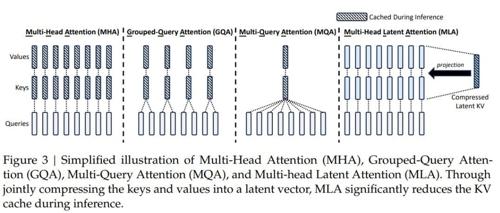
手撕大模型Attention:MLA、MHA、MQA与GQA(含实现代码) 2025年5月20日19时 作者 Datawhale 多头注意力机制(Multi-Head Attention,MHA) 多头注意力(Multi-Hea
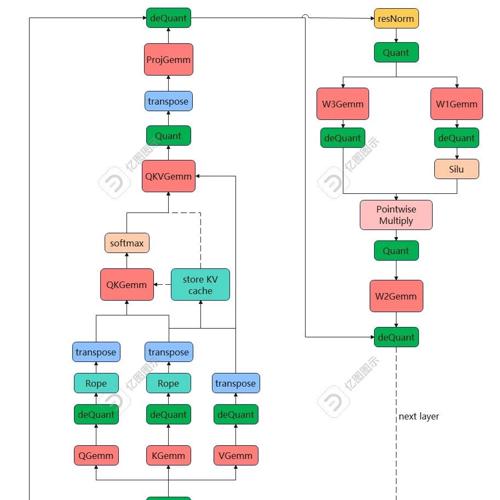
【CUDA编程】手撸一个大模型推理框架 FasterLLaMA 2024年12月27日8时 作者 极市干货 写在前面 :之前笔者写过 4 篇关于 Nvidia 官方项目 Faster Transformer