作者|沐风
来源|AI先锋官
3月6日凌晨,阿里巴巴发布并开源了全新的推理模型通义千问QwQ-32B。
在冷启动基础上,阿里通义团队针对数学和编程任务、通用能力分别进行了两轮大规模强化学习,在32B的模型尺寸上获得了惊人的推理能力提升。
根据官方发布的基准测试结果,这款320亿参数的模型通过强化学习技术,其性能在多项基准测试中与拥有6710亿参数(其中370亿被激活)的 DeepSeek-R1 相媲美。
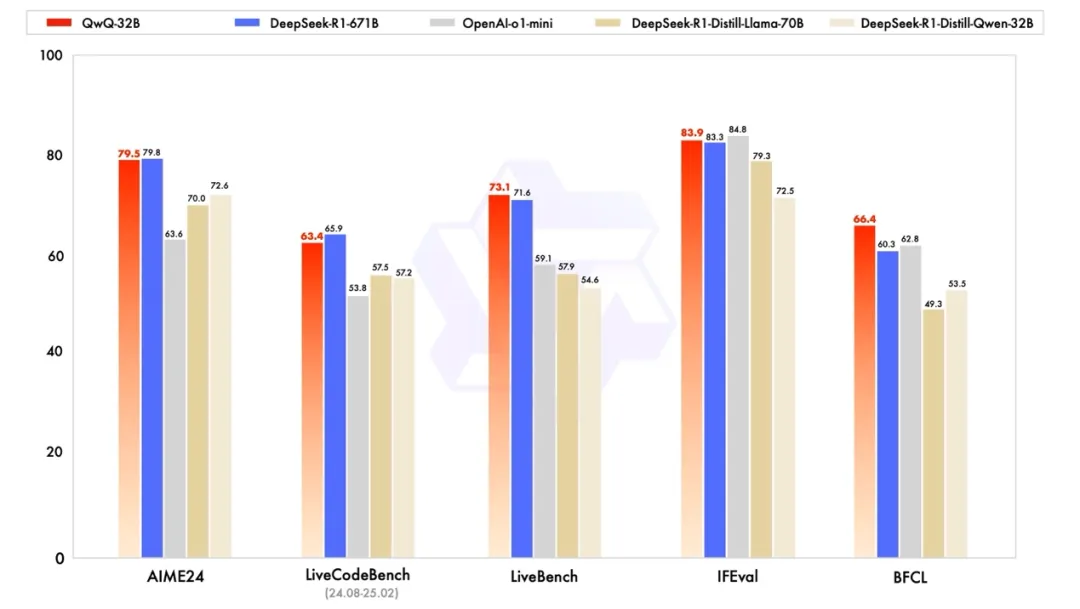
在数学推理基准AIME24上,QwQ-32B达到了79.5分,几乎与DeepSeek-R1-617B的79.8分持平,远超OpenAI o1-mini的63.6分,及相同尺寸的R1蒸馏模型。
在编程能力方面,QwQ-32B 在LiveCodeBench上获得了63.4分,接近DeepSeek-R1-617B的 65.9分,也同样优于o1-mini的53.8分和蒸馏模型。
在由Meta首席科学家杨立昆领衔的“最难LLMs评测榜”LiveBench、谷歌等提出的指令遵循能力IFEval评测集、由加州大学伯克利分校等提出的评估准确调用函数或工具方面的BFCL测试中,通义千问QwQ-32B的得分均略微超过了DeepSeek-R1-617B。
除了在性能上的提升,QwQ-32B的另一个亮点就是大幅降低了部署使用成本,671B,在FP16精度下需要1400G的显存,而现在,32B的QwQ,4张4090就能跑,这是将近15倍的差距,并且智能水平还差不多。
这也意味着开发者和企业在消费级硬件上就可以直接拿到一个足以对标DeepSeek R1的逻辑推理、数学推理、代码思考能力的大模型,将其部署到本地设备中。
目前,千问QwQ-32B已在魔搭社区、HuggingFace及GitHub等平台基于宽松的Apache2.0协议开源,所有人都可免费下载模型进行本地部署,或者通过阿里云百炼平台直接调用模型API服务。
个人用户也可通过Qwen Chat或通义APP直接体验该模型。
既然如此,小编也找来了一些题目,不如就让QwQ-32B与DeepSeek R1来较量一下,看看谁的推理能力更强。
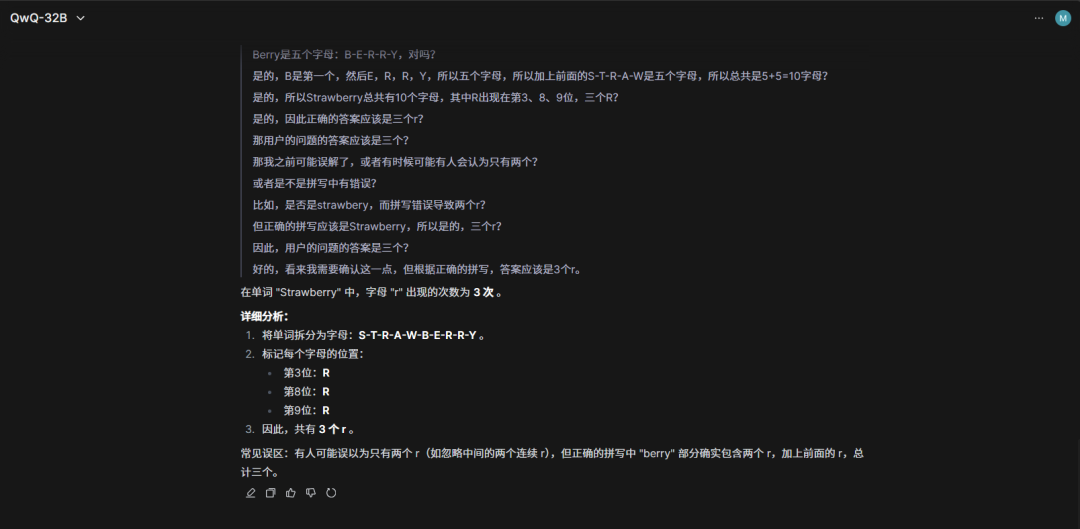
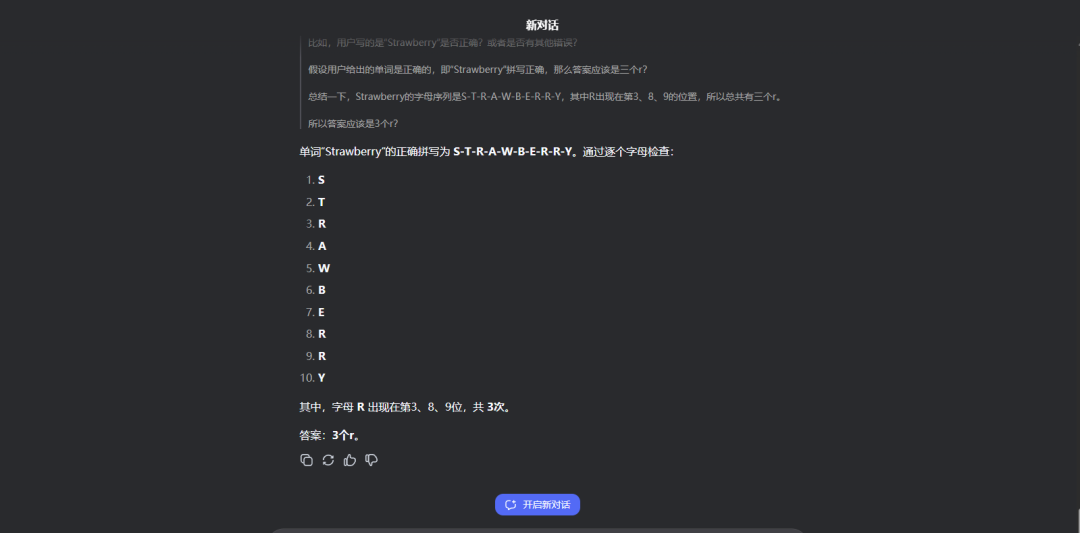
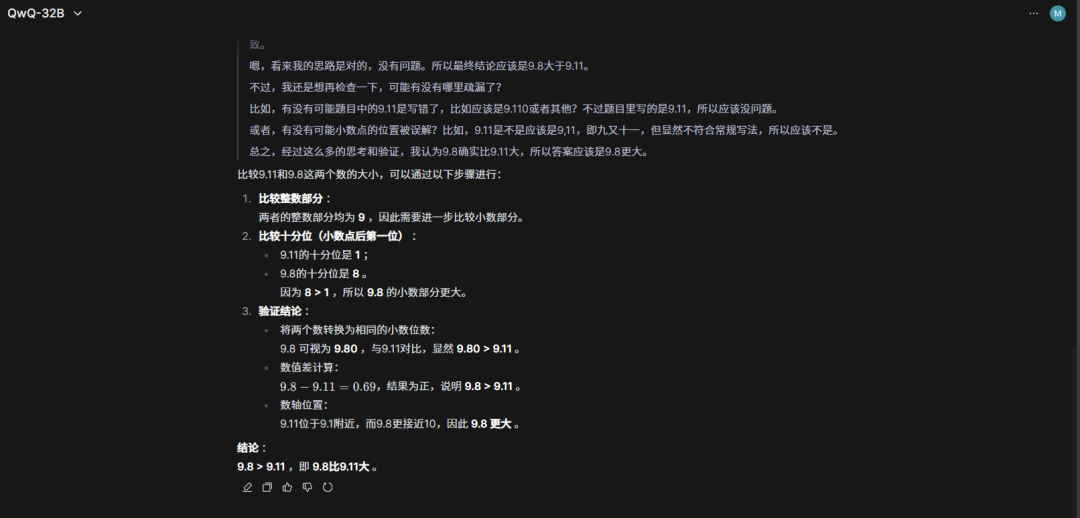
题目一:找规律 24,14,26,33,46,()
两者用时几乎相似,但它俩都没算对,答案是62.5。
所以小编又向它俩提示到“给你一点点提示,24除以2加上14等于26,14除以2加上26等于33”。
这次它们虽然将答案算了出来,但QwQ-32B一直纠结于结果必须是整数,导致经过大量计算后还给出了62这个错误答案,而DeepSeek R1则是直接四舍五入给出了63这个答案,可是题目中并没有要求必须是整数。
虽然DeepSeek R1和QwQ-32B都回答正确,但是,可以看出它们均会出现过度思考的问题,例如这道很简单的问题它俩也会生成大量的思维链,导致其输出结果的速度较慢。
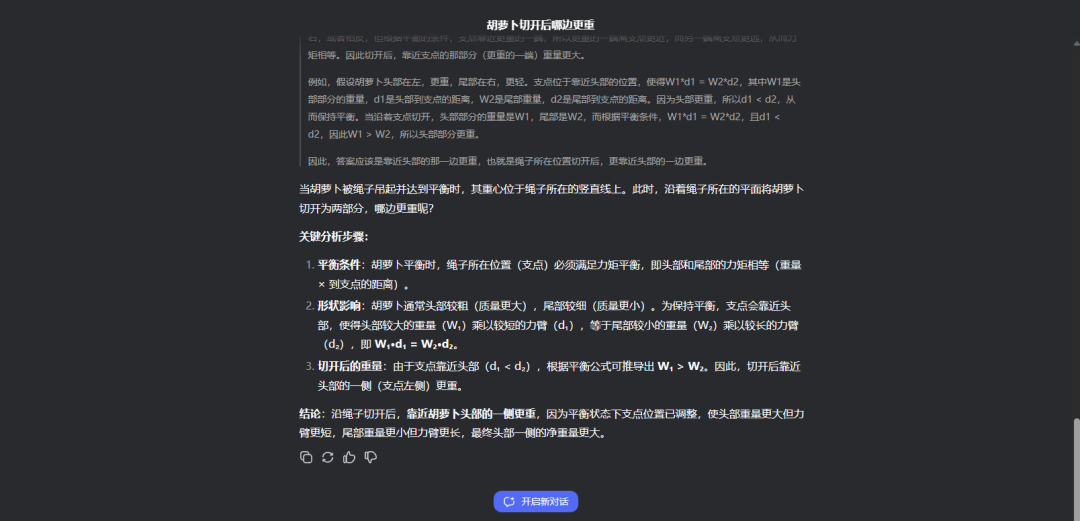
题目三:用一根绳子吊住一根胡萝卜,达到平衡,胡萝卜头尾在同一水平。这时候沿着绳子切开胡萝卜为两份,哪边更重?
没想到QwQ-32B会栽在这道题上,尽管QwQ-32B进行了约小万字的推理但还是错了。
这道题的正确答案是“因尾部较细力臂更长所以净重量要比头部更小,最终头部一侧的净重量更大。”恭喜DeepSeek R1回答正确。
题目四:房子里有五个人,A、B、C、D和E,A正在和B看电视,D在睡觉,E在打乒乓球,请问C在做什么?
QwQ-32B、DeepSeek R1回答完全正确,看来现在这类题完全难不到它们了,那就再来个经典的。
这道经典必考题QwQ-32B和DeepSeek R1均回答正确,值得注意的地方是,它俩的推理过程极其相似。
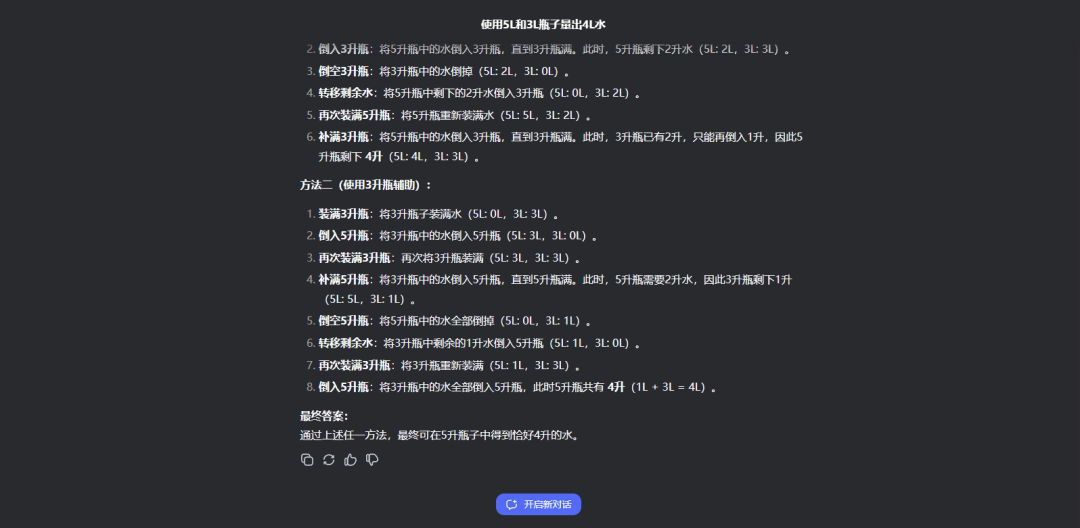
题目六:用5L容量和3L容量的瓶子怎么装出4L的水?
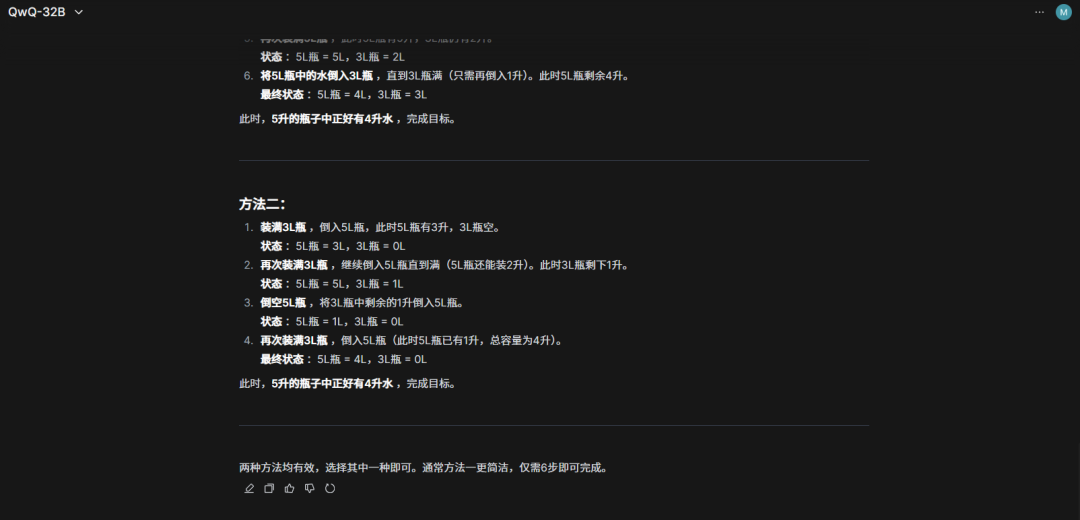
在这道题中,QwQ-32B将可实现的两种答案全部生成了出来,而DeepSeek R1虽然回答的也正确,但只给出了1种方法。
从这六个题目中可以看出来,QwQ-32B在逻辑推理、数学分析和知识储备方面展现出了与DeepSeek R1相媲美的实力。
但也暴露出QwQ-32B存在的一些短板,例如过度思考、处理复杂问题、运用物理知识和理解某些特定领域概念时,仍有提升空间,但其潜力是不容忽视的。
值得一提的是,有资料显示,从2023年至今,阿里通义团队已开源200多款模型,包含大语言模型千问Qwen及视觉生成模型万相Wan等两大基模系列,实现了全模态、全尺寸大模型的开源。
开源社区Hugging Face此前的榜单显示,开源仅6天的阿里万相大模型已反超DeepSeek-R1,登顶模型热榜、模型空间榜两大榜单,成为近期全球开源社区最受欢迎的大模型。
根据最新数据,万相2.1(Wan2.1)在Hugging Face及魔搭社区的总下载量已超百万,在Github的Star数超6k。
(文:AI先锋官)