
就在昨天,阿里 Qwen(千问)团队发布并开源了一个“小而美”的推理模型:QwQ-32B。
这个模型凭借其“娇小的身材”——32B 参数,即320亿,及其媲美大参数模型的性能——比如满血版 DeepSeek-R1,迅速走红。
截至写这篇文章,Qwen 的官宣帖阅读数已超过170万。

32B 这么小的参数量是什么概念?
意味着这个模型能够直接在消费级显卡上跑起来,比如英伟达的 RTX 3090和4090。具体说来,拥有 24 GB 显存的 GPU 即可以全精度运行 QwQ-32B 完整版模型。
相较于 DeepSeek-R1,它的满血版可是有 671B(6710亿)参数,约为 QwQ-32B 的20倍。同样的硬件配置,只能跑得起 DeepSeek-R1 的 32B 蒸馏小模型。
更详细的硬件配置需求,可以参考下面的这个表格自查。

而通过 Qwen 团队公布的 QwQ-32B 模型基准测试结果,在数学、代码方面完全可以不输于满血版的 DeepSeek-R1。
具体看下图,红色柱是 QwQ-32B 的分数,蓝色柱是满血版 DeepSeek-R1 的得分。

但值得一提的是,虽然说 QwQ-32B 实力不俗,但要让它真正和满血版 DeepSeek-R1 在各方面大战一场,那必定是打不过的。连 Qwen 官方用的词都是“媲美”,这就能说明情况了吧。
之前曾出过一期教程:手把手教你本地部署DeepSeek-R1:3步搞定,有手就行!,其中详细介绍了如何在本地电脑上部署各个小参数的蒸馏版 DeepSeek-R1。
现在,有了 QwQ-32B,这些蒸馏版模型可以彻底下岗了,毕竟参数又小,性能又强劲,何乐而不为。
部署方法大同小异,因为就在刚刚,Ollama 也添加了对 QwQ-32B 的支持。

1. 第1步:安装 Ollama
官网安装,命令行安装都可以。
划重点,之前已经安装过的可以自行忽略这一步。
https://ollama.com/

安装完成后,打开 终端 运行下面的命令。正常来说会输出Ollama的版本号,如“ollama version is 0.5.7”。
# 验证安装
ollama --version
第2步:下载 QwQ-32B 模型
QwQ-32B 模型参数约 32.8B,使用 Q4_K_M 量化版本,模型文件约 20GB,Apache 2.0 开源证书。
# 下载 QwQ-32B
ollama pull qwq
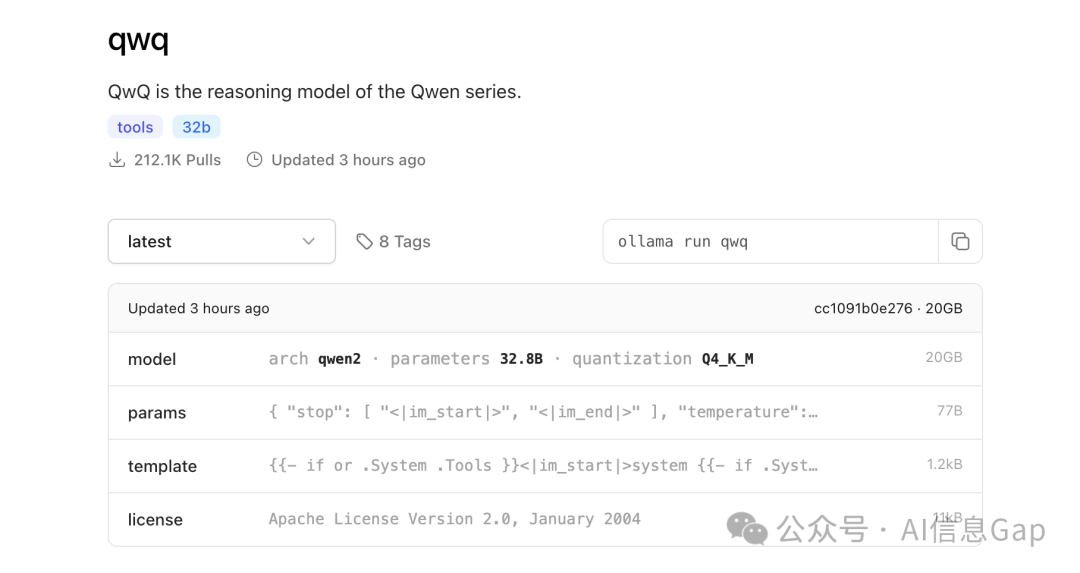
下载完成后,可以用下面这条命令验证模型,该命令会输出你通过 Ollama 安装的模型。如果一切正常,qwq 应该出现在输出列表中。
# 验证模型
ollama list
第3步:运行 QwQ-32B 模型
如果是通过客户端安装 Ollama,模型安装好后会自动进入交互式会话模式,此时你就可以和模型聊天了!
如果没有进入会话模式,用下面的命令启动模型。
# 运行模型
ollama run qwq
当然,也可以选择在第三方客户端里使用这个本地模型,比如 Chatbox,详情参考上一篇本地部署教程。
https://chatboxai.app/zh

如果你只是想单纯的使用这个模型,那么在 Qwen Chat 里或者 Hugging Face 里有现成的 QwQ-32B 可以使用。
Qwen Chat(通义千问海外版) :https://chat.qwen.ai Hugging Face Demo :https://huggingface.co/spaces/Qwen/QwQ-32B-Demo Hugging Face QwQ-32B 模型首页 :https://huggingface.co/Qwen/QwQ-32B
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)