
“ 自定义数据集既是未来人工智能技术的重点,也是人工智能技术的难点 ”
在人工智能领域中,数据的重要性得到了充分的体现;但很多人还不知道怎么打造一个数据集,所以今天我们就用一些图片来模仿MINST数据集打造一个类MINST数据集,能够直接被神经网络加载和使用。
当然,为了简单起见我们对数据就只进行简单的处理,如统一图片大小,不会按照严格的数据处理方式;比如说图片裁剪,增强等。
自定义数据集实现
以MINST数据集为例,其主要由四个压缩文件组成;训练集的图片和标签,以及测试集的图片和标签。如下图所示:
而我们今天就以训练图片数据为例,使用一些图片构造一个训练集。
首先我们需要从网上或者其它地方找到一些特征数据,放到一个目录里面,作者这里使用的是一些蚂蚁的图片数据。如下图所示:
由于找到的图片格式不同,大小也不同,因此我们第一步就通过对图片大小进行变换以获取同样大小的图片,如MINST数据集的图片就是28*28统一大小的数据。统一图片大小的好处是方便神经网络进行处理。
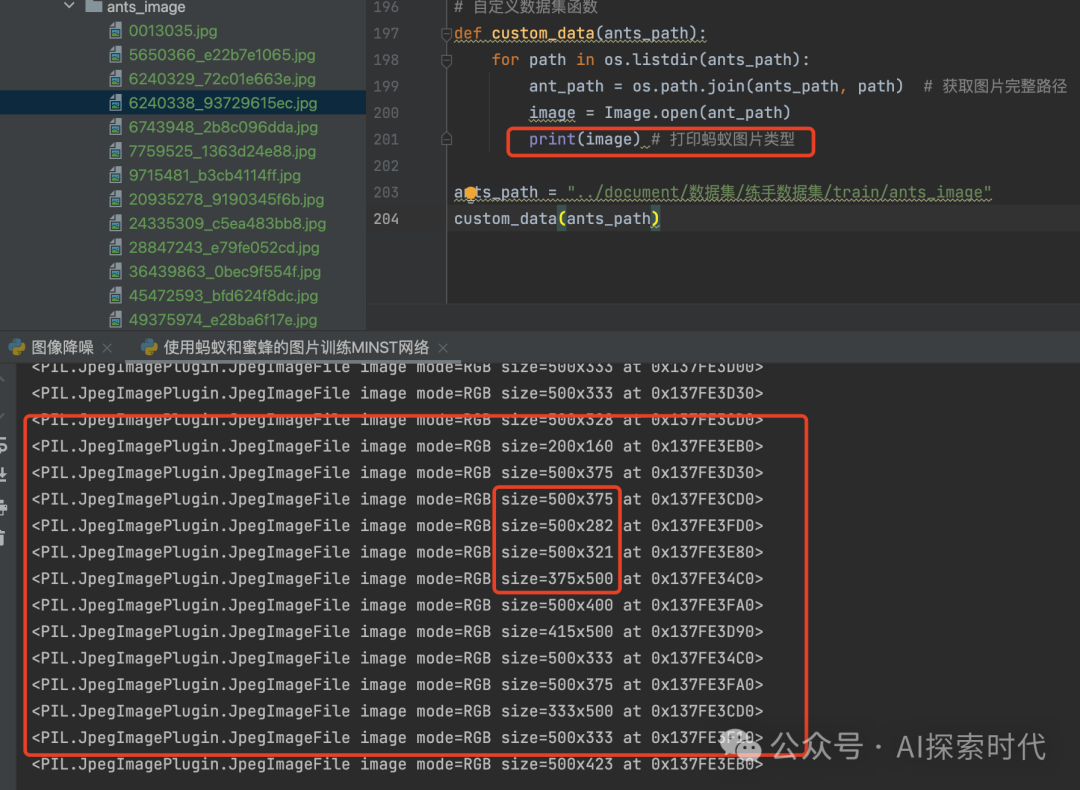
首先我们需要读取图片数据,并对图片数据大小进行统一处理,如下所示,可以明显看到图片的size参差不齐。
因此,我们需要对图片大小进行统一处理;函数如下:
# 图片大小转换函数 这种只是简单的大小变换 会导致图片变形只作为例子使用def resize_image(img, target_size=(500, 500)): # img 是待处理图片 target_size是目标大小,如(500, 500)return img.resize(target_size, Image.Resampling.LANCZOS)
如下图所示,变换之后的图片大小变成了统一的500*500;但这里只是举个简单的图片处理例子,在实际的业务场景中,对图片数据的处理会更复杂,更严格;比如对图片进行裁剪,统一通道,等比缩放等;而现在这种简单的变形方式会导致图片变形,因此只作为例子使用。
这里对图片处理的工具使用的是Python经典的图片处理包PIL,当然读者也可以选择自己喜欢的其它工具包,如OpenCV等。总之,目的就是把图片处理成自己需要的格式。
在对图片数据进行初步处理之后,就可以使用Numpy把图片转换为向量格式,也就是多维矩阵。
img = np.array(img)完整代码如下所示:
import osfrom PIL import Imageimport numpy as npimport struct"""自定义图片数据集 缺少的包需要自己按照 pip(3) install 包名"""# 图片大小转换函数def resize_image(img, target_size=(500, 500)):# img 是待处理图片 target_size是目标大小,如(500, 500)return img.resize(target_size, Image.Resampling.LANCZOS)# 把处理后的图片打包成类似MINST的二进制格式 数据集的前部分是数据集的描述内容 因此需要添加文件头 类似于MINST的真实图片都是从16字节开始的def save_images_as_minst(file_path, images):""" 将图像数据保存为 MNIST 格式 :param file_path: :param images: 图像数据,形状为 (num_samples, height, width) :return: """num_samples, height, width = images.shapewith open(file_path, 'wb') as f:# 写入文件头f.write(struct.pack('>IIII', 0x00000803, num_samples, height, width))# 写入图像数据f.write(images.tobytes())# 自定义数据集函数def custom_data(ants_path):# 收集向量化的图片列表image_data = []for path in os.listdir(ants_path):ant_path = os.path.join(ants_path, path)# 获取图片完整路径image = Image.open(ant_path)# print(image) # 打印蚂蚁图片类型img = resize_image(image) # 变换之后的图片大小# print(img)# 在对图片进行向量化之前 也可以指定图片对模式 L-灰度模式 RGB-彩色 PIL一共有九种模式 读者可以自信百度# 目前图片的默认模式是RGB模式 而MINST数据集是灰度模式 也就是L 表示黑白色 读者可以根据自己的需求进行处理 或采用默认即可img = img.convert('L') # 这里由于图片格式不一致 导致其通道数不同 因此这里使用最简单的灰度图——L 来统一图片 方便后续处理img = np.array(img) # 把向量化的图片放到一个列表中image_data.append(img)# print("image_data: ", image_data)# 统一转换成numpy 数组 方便使用二进制存储data = np.array(image_data)print("转换后的图片数组: ", data)# 打包文件名 保存在当前目录下 data是待打包的数据save_images_as_minst("custom_images_ants_ubyte", data)ants_path = "./ants_image"custom_data(ants_path)# 读取打包的文件def read_image(file_path):with open(file_path, 'rb') as f:magic, num, rows, cols = struct.unpack('>IIII', f.read(16))images = np.frombuffer(f.read(), dtype=np.uint8).reshape(num, rows, cols)return imagesfor img in read_image("./custom_images_ants_ubyte"):im = Image.fromarray(img)print(im)
这里只是举了一个简单的处理和打包数据集的例子,在真实的场景中数据处理要远比这复杂的多。
而且这里主要针对的是图片数据,工具使用的主要是PIL图片处理工具和Numpy科学计算工具。
如果是文本数据,还会涉及到词表的构建等;总之,数据处理是作为人工智能从业者所必备的技能。
完整数据和代码,也可以在公众号回复: 自定义MINST数据集 获取
(文:AI探索时代)