

你还在用markdown 格式给大模型喂网页吗?
一种叫HtmlRAG的新方法,让RAG系统不再「目不识丁」,而是能够充分利用HTML的结构信息,大大提升了知识检索的准确性。
一起来看看这个「神奇」的HtmlRAG到底有什么过人之处。

RAG系统的「近视」问题
要知道,现在的RAG系统可是有点「近视」。
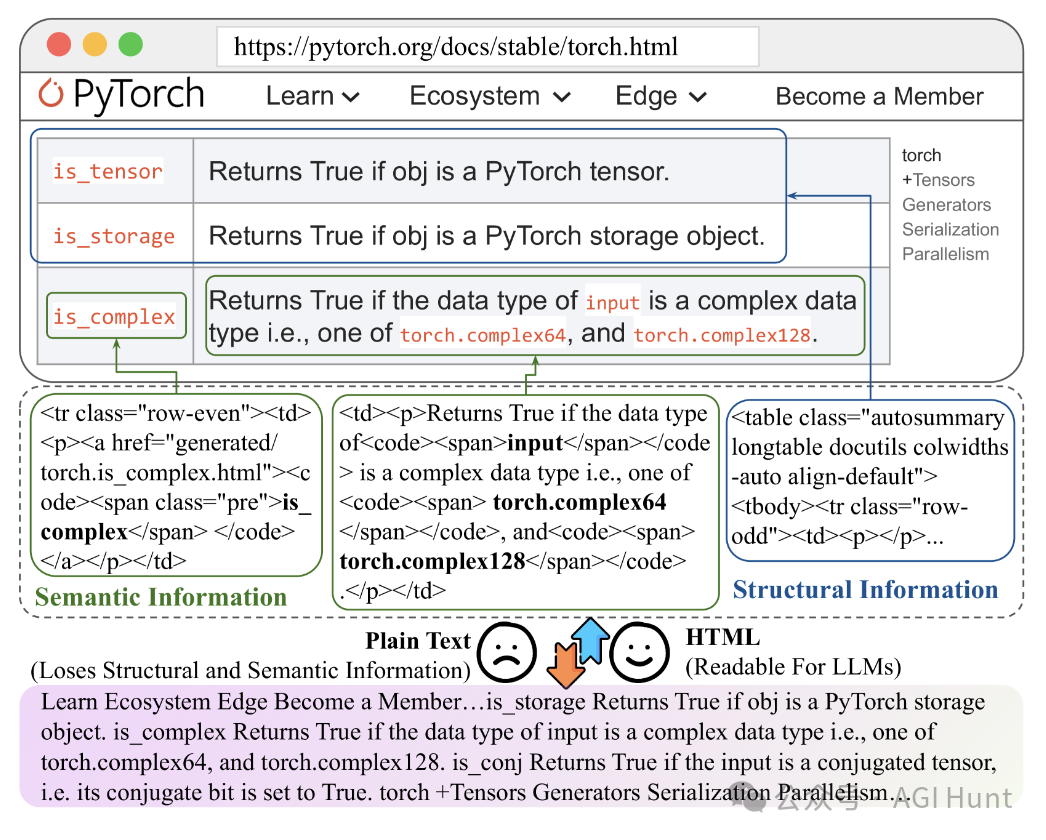
它们在处理网页内容时,通常会把HTML转换成纯文本,结果就像是把一本精美的图文并茂的书变成了一堆没有章法的文字。
这样一来,网页中的标题、表格结构等重要信息全都丢失了。
更糟糕的是,原始的HTML文档动辄就有8万多个token,里面还夹杂着大量的CSS和JavaScript代码,简直就是一团乱麻。
HtmlRAG:给RAG系统装上「老花镜」
面对这个问题,研究团队可不甘心就此认输。
他们开发的HtmlRAG就像是给RAG系统装上了一副「老花镜」,让它能够看清HTML的结构,并充分利用这些信息。
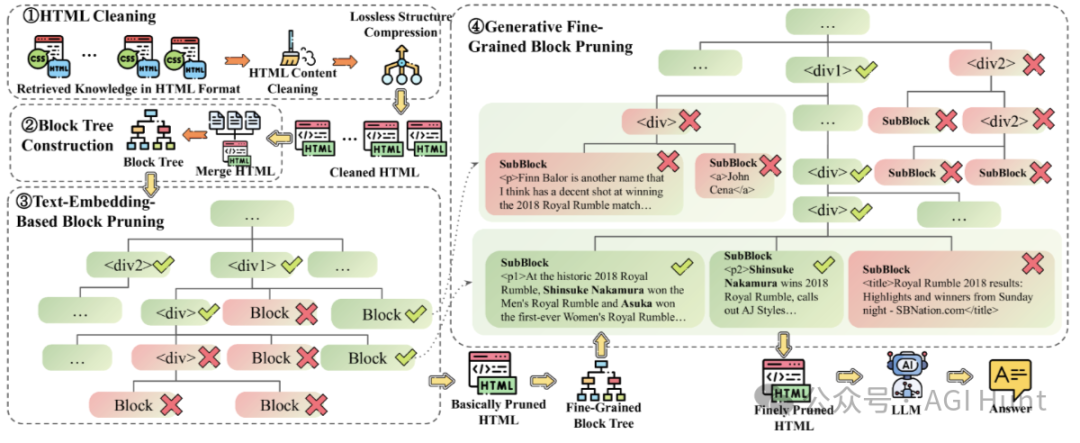
HtmlRAG主要包含三个关键组件:
-
HTML清理模块:这个模块会去掉CSS、JavaScript等无关内容,同时压缩重复的结构,但保留语义信息。经过处理后,文档大小居然缩小到了原来的6%!
-
块树构建:这个模块会从DOM树中构建一个优化后的树结构,可以根据不同的需求进行调整。
-
两步HTML剪枝:首先用嵌入模型对不太相关的块进行粗略剪枝,然后再用生成模型对剩下的块进行更精细的剪枝。
HtmlRAG的过人之处
HtmlRAG的设计可谓是别出心裁,它有几个让人眼前一亮的特点:

-
利用LLM的HTML理解能力:大语言模型在预训练时就已经学会了理解HTML,所以用HTML来表示知识再合适不过了。
-
通用性强:HTML不仅可以表示网页,还可以很好地表示PDF、Word等其他文档格式,几乎不会丢失信息。
-
高效的块树结构:相比直接处理DOM树,块树结构让HTML处理变得更加高效。
-
两阶段剪枝的威力:结合使用嵌入模型和生成模型的两阶段剪枝,效果比单阶段方法要好得多。
实验结果令人振奋
研究团队在6个问答数据集上进行了测试,包括模糊问答、自然问答、多跳问答和长篇问答。结果显示,HtmlRAG在各项指标上都大幅超越了使用纯文本的基线方法。
最让人惊喜的是,HTML清理后的文档大小只有原来的6%,但关键信息却得到了很好的保留。
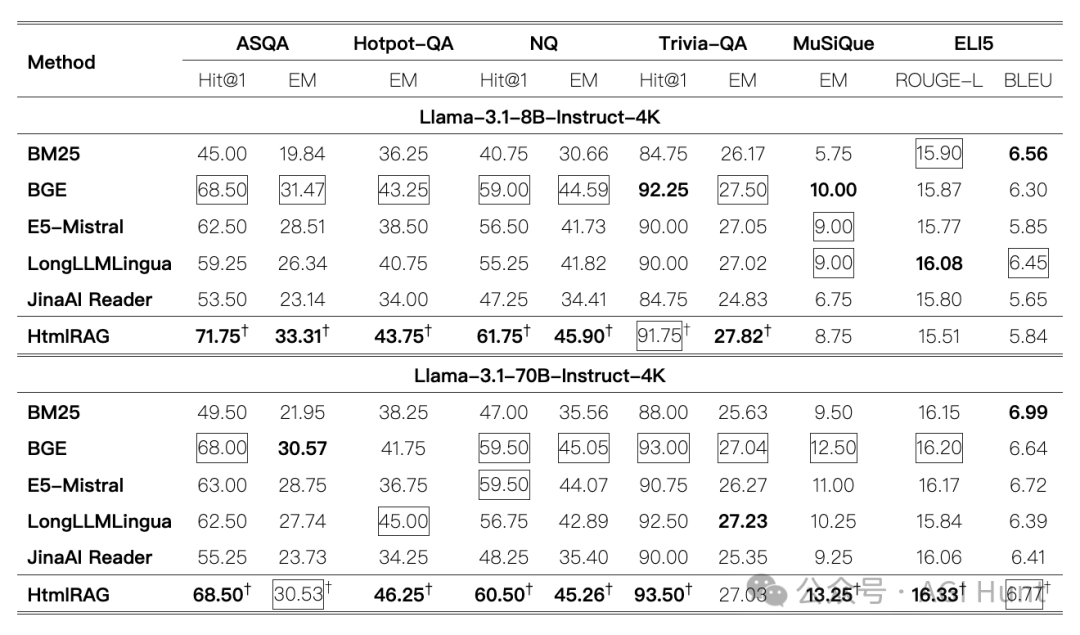
这意味着,HtmlRAG不仅提高了准确性,还大大提升了效率。
HtmlRAG的出现,不仅让RAG系统变得更「聪明」,还为我们处理和利用网页信息提供了新的思路。
论文地址:https://arxiv.org/abs/2411.02959
(文:AGI Hunt)