

-
论文标题:Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
-
论文地址:https://arxiv.org/pdf/2503.07572
-
项目主页:https://cohenqu.github.io/mrt.github.io/



-
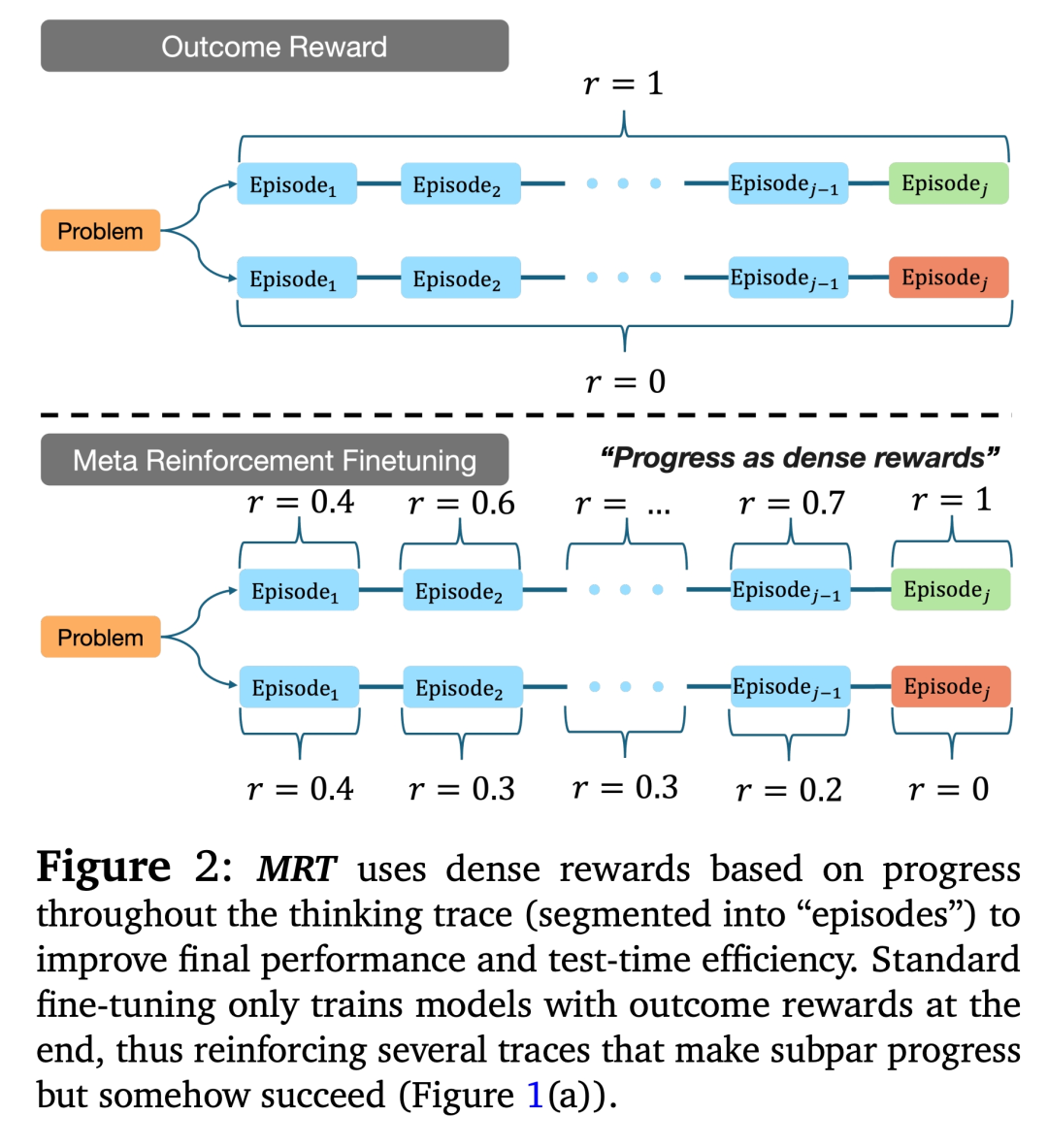
强制终止当前的思考块(thought block),使用「time is up」提示(prompt);
-
让模型根据当前的推理前缀(reasoning prefix)生成其最佳猜测的解决方案。
-
使用元证明器策略 μ 计算思维前缀的奖励;
-
基于这个前缀采样多个策略内的轨迹(rollouts),这些轨迹被均匀分配为:继续进一步推理;终止思考轨迹并生成最佳猜测的解决方案;
-
根据对进展(progress)的奖励,然后计算进展奖励。

-
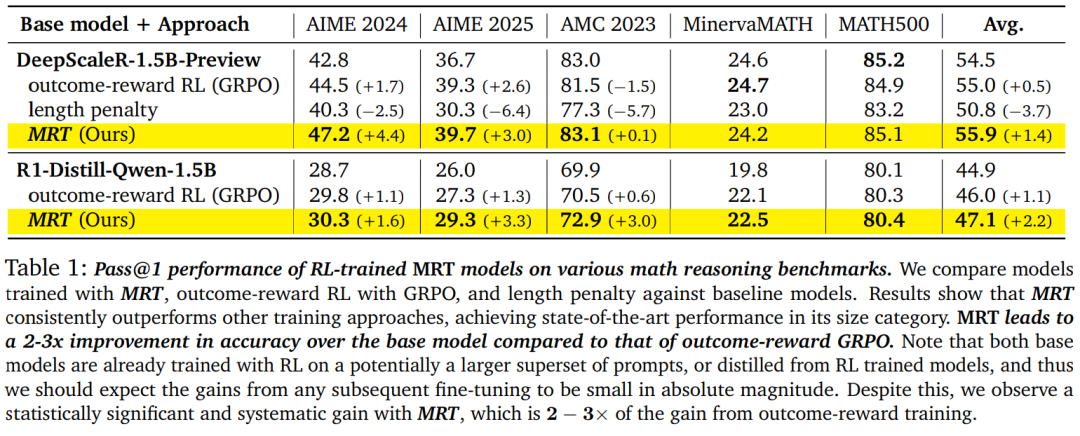
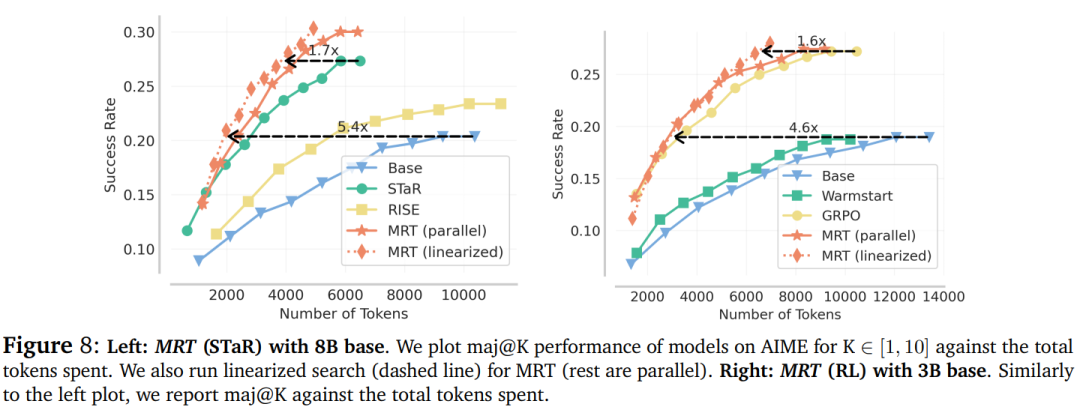
基于 DeepScaleR-1.5B-Preview 基础模型微调的模型达到了其规模下 SOTA 水平。由于模型在经过蒸馏或已经经过强化学习(RL)训练的基础模型上进行了训练,因此绝对性能提升较小。然而,与基于结果奖励的 RL 方法(如 GRPO)相比,使用 MRT 的相对性能提升约为 2-3 倍。
-
当使用 DeepScaleR-1.5B 模型在 AIME 问题数据集上进行微调时,MRT 不仅在 AIME 2024 和 AIME 2025 评估集上取得了更好的性能(这或许在意料之中),而且在相对于结果奖励强化学习(RL)分布外的 AMC 2023 数据集上也保持了较好的性能。



©
(文:机器之心)