

极市导读
本文提出Pixel2Pixel,一种创新性零样本去噪框架,不需要除噪声图像本身之外的任何额外训练数据。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
提出一种全新的从像素到像素(Pixel2Pixel)零样本图像去噪方法,借鉴传统Non-Local Means方法深度挖掘图像的自相似性,构建像素库(Pixel Bank),在此基础上利用随机采样策略生成大量伪实例(噪声样本图像),最终实现高效零样本图像去噪。此外,理论证明了提出方法的有效性和对噪声的泛化能力。

论文地址: Pixel2Pixel: A Pixelwise Approach for Zero-shot Single Image Denoising
项目地址:https://github.com/qingma2016/Pixel2Pixel
1. 引言
近年来,基于深度学习的方法凭借其卓越性能主导了图像去噪领域。监督学习方法通过大规模成对数据集训练网络,取得了最佳效果,但其对噪声-干净或噪声-噪声图像对的依赖导致数据收集耗时且复杂。为缓解这一问题,自监督去噪方法通过挖掘噪声图像内部监督信号,避免了干净数据的需求,但仍需大量训练图像,且对真实噪声的泛化能力不足,尤其面对未知噪声类型时性能显著下降。
进一步减少数据依赖的零样本方法成为研究热点。这类方法聚焦于单张噪声图像生成训练对及高效网络设计,例如通过添加随机噪声或下采样构造数据,并采用U-Net等轻量架构。然而,现有方法存在明显局限:一方面,基于像素独立噪声假设的模型难以应对真实噪声的空间相关性(由图像信号处理器引入);另一方面,数据生成策略过度依赖局部平滑性假设(如Neighbor2Neighbor的邻域相似性、Noise2Fast的方向性约束),忽略了自然图像中广泛存在的非局部自相似性——即图像中重复出现的相似结构块。这种局限性导致传统方法在真实噪声场景下性能受限。

针对上述挑战,本文提出Pixel2Pixel,一种创新性零样本去噪框架,其核心贡献体现在理论与方法两方面:
理论层面:我们首次证明,在Noise2Noise范式下,全局最小化器本质上是条件风险最小化器。这一发现表明,统计模式可在比整图更微观的层面被捕捉,且通过选择合适的损失函数(如基于噪声统计特性的L1或Huber损失),可等效实现Noise2Clean式的优化目标,为无监督学习提供了新的理论支撑。
方法层面:提出两大核心技术:
-
非局部像素库构建:通过大范围滑动窗口搜索相似像素,聚合图像全局自相似性,形成冗余特征库。相较于传统方法局限于较小邻域或固定方向采样,该方法能够挖掘非局部的结构相似性(如建筑物纹理、生物显微结构的重复模式),为噪声抑制提供丰富先验。 -
像素级随机采样策略:从像素库中随机选择不连续位置像素生成伪训练对。该策略通过空间置换打破噪声的空间相关性,同时保留真实信号的非局部一致性。例如,在显微图像中,随机采样可有效分离荧光噪声的空间关联性,提升去噪信噪比。
2. 方法
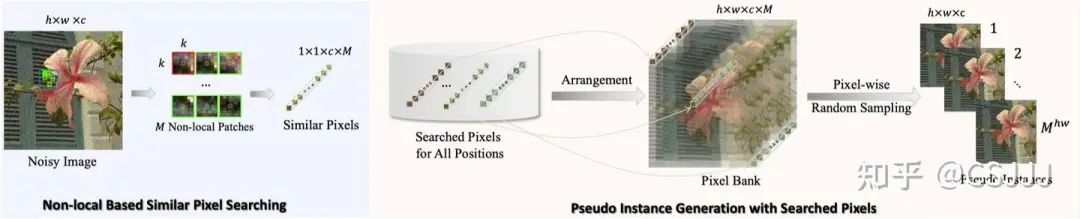
2.1 像素点搜索
我们方法构建训练样本的主要思想如图2所示。给定一个噪声图像,对于中的每个像素,我们提取一个局部块,并在的足够大窗口内搜索个与相似的非局部块。考虑到噪声的多样化统计特性,我们选择适当的距离来衡量块的相似性。特别地,对于零均值噪声,我们使用距离;对于非零均值噪声中占主导地位的干净像素,我们使用距离。在对非局部块进行排名后,我们从每个块中提取中心像素,创建一个张量。这种技术旨在利用图像的NSS先验,寻找与相似但不同的像素。直接使用进行搜索可能会得到相同的像素匹配,无法为网络训练提供新信息。通过对中所有像素重复此过程,我们生成了一个张量,称为“像素库”。
2.2 像素点采样
构建像素库后,我们能够使用逐像素随机采样策略抽取大量样本(总共个),我们称之为“伪实例”。这种方法在防止网络过度拟合方面非常有效。在每次训练迭代中,网络随机抽取一对(总共有对,对于每个空间位置,我们确保两次采样的像素不同)进行训练。在创建伪实例对时,Pixel2Pixel打乱了噪声图像中像素的原始空间排列。这个过程不限于邻近像素形成对,有助于减少真实噪声图像中邻近像素间噪声的空间相关性。这种策略显著增强了该算法在真实世界噪声图像上的去噪效果。

2.3 网络训练
接下来,我们详细介绍我们的网络架构、训练方案和使用的损失函数。我们的神经网络使用一个简单的CNN架构,包含五层,每层的卷积有64个通道,每个卷积层后面跟着一个leaky ReLU激活层。在最后一层,我们使用的卷积。值得注意的是,我们的网络设计省略了残差连接,并避免使用残差损失,因为这会导致性能下降。
如图3所示,在我们的网络训练过程中,我们不使用噪声图像作为固定输入,而是在每次迭代中随机从像素库中抽取两个伪实例作为输入和输出。这种增加样本随机性的方法显著提高了网络性能。与以前的方法如Neighbour2Neighbour或ZS-N2N不同,我们的训练样本可能有对应像素在噪声图像中位置更远。我们根据噪声的统计特性选择合适的损失函数。具体来说,对于零均值噪声,我们使用损失,而对于非零均值噪声中占主导地位的干净像素,我们使用损失。
3. 实验
3.1 合成噪声
零均值噪声: 在表1中,我们展示了不同方法的去噪性能。值得注意的是,BM3D需要输入特定的噪声水平。对于高斯噪声,我们直接输入实际噪声水平,而对于泊松噪声,我们使用基于估计的噪声水平。对于零样本方法,传统方法BM3D在已知噪声水平(高斯)下表现优秀,但在未知噪声水平(泊松)下效果减弱。对于基于深度学习的方法,DIP远远落后于其它方法,而S2S在较高噪声水平下表现出色,尽管其成功很大程度上依赖于其集成策略,这往往会导致图像过度平滑。ZS-N2N在较低噪声水平下表现良好,但在较高噪声水平下性能显著下降,这是由于其降采样策略在训练和测试图像之间造成的噪声水平不匹配。相比之下,我们的Pixel2Pixel方法在大多数情况下始终实现最佳或接近最佳的性能,突显出最为稳健的选择。在图4中,我们展示了不同方法在高斯噪声上的去噪效果。


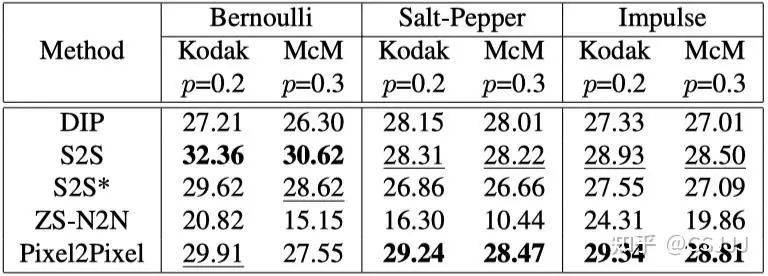
干净像素占主导的非零均值噪声: 我们主要考虑三种不同类型的非零均值噪声:伯努利噪声、椒盐噪声和脉冲噪声。在处理以干净像素为主的非零均值噪声时,我们采用损失函数。为了保持公平比较,我们也将其他方法的损失函数调整为它们各自的变体。如表2中所示,ZS-N2N在处理非零均值噪声时遇到困难。这个限制来源于它的方法,在原始噪声图像中的区域内沿主对角线和反对角线平均像素以创建降采样对。这种方法无意中改变了噪声的性质,影响了去噪效果。例如,在椒盐噪声的情况下,这种降采样技术会将值为0和1的噪声像素转换为中间值。另一方面,S2S在处理伯努利噪声方面表现出色,这归功于其训练过程中涉及通过伯努利采样原始噪声图像生成图像。我们的Pixel2Pixel方法在处理椒盐噪声和脉冲噪声方面达到了最佳性能。在图5中,我们展示了用于非零均值噪声去除的去噪图像的定性比较。结果清楚地表明,我们的方法在所有测试方法中提供了有竞争力的视觉质量。值得注意的是,对于伯努利噪声,尽管S2S方法获得了更高的PSNR分数,但由于它是50个网络测试结果的平均值,出现了过度平滑的问题。

3.2 真实噪声
相机噪声: 我们在PolyU数据集和SIDD数据集上进行评估。对于每个数据集,我们并从每张图像的中心提取一个的区域。不同方法在处理真实相机噪声方面的去噪性能总结在表3中。与合成噪声不同,在处理真实相机噪声方面,DIP的表现优于S2S和ZS-N2N。我们的方法在两个数据集上都取得了最佳性能。这归功于S2S、ZS-N2N和我们的方法都基于不同像素点噪声独立的假设。然而,真实噪声图像中相邻像素的噪声总是显示出相关性,这在S2S和ZS-N2N算法的设计中没有考虑到。相比之下,我们的方法从非局部块的中心像素创建像素库,并从像素库中随机抽样形成伪实例,有效地打破了噪声的空间相关性。在图6中,我们提供了去噪图像在相机噪声去除方面的定性比较。结果显示,尽管原始噪声图像中的噪声不强烈,S2S和ZS-N2N仍导致图像质量受损。这种不足源于它们依赖噪声独立的假设,忽略了真实图像中噪声的固有空间相关性。在构建训练数据时的这种疏忽导致它们在处理真实相机噪声方面的效果降低。显然,我们的方法脱颖而出,取得了优越的主观和客观结果。


显微镜噪声: 我们还使用荧光显微数据集(FMD)来评估比较方法在显微镜噪声上的性能。FMD数据集由使用商业共聚焦、双光子和宽场显微镜拍摄的图像组成,这些显微镜对细胞、斑马鱼和小鼠脑组织等代表性生物样本进行成像。我们选择三个类别进行测试:光子BPAE、光子Mice和共聚焦BPAE,每个类别包含20张图像。表4中显示了不同方法的结果,我们的方法在各个类别中和平均所有类别中都达到了最佳性能,取得了显著的提升。

3.3 计算复杂度
我们比较了零样本去噪方法的计算效率。表5详细说明了使用不同方法对Kodak24数据集中单张图像进行去噪所需的平均时间,以及网络参数和PSNR分数。值得注意的是,对于BM3D,我们报告的是CPU运行时间,而基于深度学习的方法报告的是GPU运行时间。表格显示,在所有基于深度学习的方法中,ZS-N2N具有最少的参数数量和最短的计算时间,但其性能较差。另一方面,S2S方法在去噪质量方面表现出高性能,但代价是显著的计算资源消耗,使其在处理时间和资源利用方面成为较低效的选择。Pixel2Pixel方法作为一个强大的解决方案,实现了高质量性能和计算效率之间的令人称赞的平衡。其网络参数和计算时间略高于ZS-N2N,但在去噪能力方面显著优于后者。这使Pixel2Pixel成为在性能和效率都受重视的场景中的最佳选择。

4. 结论
本文提出了Pixel2Pixel,一种零样本去噪方法,不需要除噪声图像本身之外的任何额外训练数据。通过为每个像素点搜索相似像素(基于块评估相似性),我们构建了一个像素库。然后通过逐像素随机采样生成训练样本。构建像素库并通过从像素库中逐像素随机采样生成训练图像可以减少相邻像素间噪声的空间相关性,从而增强算法处理真实世界噪声图像的能力。我们使用了一个只有五层的网络,使训练过程非常快。广泛的实验表明,Pixel2Pixel的性能超过了现有的基于深度学习的零样本去噪方法,特别是在存在真实相机噪声和真实显微镜噪声的情况下。

(文:极市干货)