
你见过可以边聊天边画图的 AI 模型吗?
大概率没有。
回想一下,DeepSeek,不论是 V3 还是 R1,都只能聊天,不能画图。
OpenAI 的 GPT-4.5、GPT-4o、o1 和 o3-mini,同样是清一色的文本模型,最多支持图片输入,而无法直接输出图片。
你可能有疑问,ChatGPT 不是能画图吗?其实不然,ChatGPT 的画图功能是基于“文生图”模型 Dall·e 3 的,而不是 GPT-4o。
比如我们查看一下 GPT-4o 官方说明卡片,上面清楚地标明 GPT-4o 仅支持文本输出。

在此前,AI 模型一直是“聊天不画图,画图不聊天”。这其实是由文本大模型和绘图大模型的底层架构的差异造成的。
而如今,原生绘图的“天”被谷歌率先捅破了。
3月13日,谷歌 AI Studio 产品负责人 Logan Kilpatrick 发文称:Gemini 2.0 Flash 已支持生成原生图像!
听起来稀松平常的功能,不就是画图吗,还至于这样“昭告天下”?
还真至于。要知道,Gemini 2.0 Flash 之前只是一个文本模型,也就是用来聊天的;现在加入了生图功能,不需要切换模型就能边聊边画图了!
并且,“原生图像”这个功能是 OpenAI 很早之前就给 GPT-4o 画的一个大饼,没想到被谷歌先给实现了!
来看效果。基于聊天画图,而不必精心构想很复杂的“文生图”提示词。更重要的是,一致性超级好!

Logan 表示,这种模型“原生”的生图功能之所以如此强,是因为 Gemini 模型本身拥有丰富的世界知识(即 海量的训练数据),这是传统的 AI 生图模型所不具备的。
比如定向修改图片里特定物体的颜色,就像下面这样,把马变成黑白色,地上的花换成黄色。

要想体验 Gemini 2.0 Flash 的原生画图功能,很简单。
可以直接在谷歌 AI Studio 里选择 Gemini 2.0 Flash-Exp 实验模型,注意,认准是实验模型,不是正式版的 Gemini 2.0 Flash。使用完全免费。
同时,也已支持 API 调用。

打开谷歌 AI Studio,选择 Gemini 2.0 Flash-Exp,让我们一起来实际体验一下这个原生画图功能的效果。
实测中、英文提示词都支持。
先来让 Gemini 2.0 Flash-Exp 解析一首古诗,并画出配图。
月落乌啼霜满天,江枫渔火对愁眠。
姑苏城外寒山寺,夜半钟声到客船。
逐句讲解并配图
就这么一句简单的提示词,输出了整首诗的详解以及每一句的配图,语文老师狂喜。

测试下来,Gemini 2.0 Flash-Exp 非常擅长边讲故事边画图,基本上是可以复刻 Logan 展示的 GIF 动画效果的。
就行下面这样。

动画风格的也可以。

再来试试定向修图。
先让它画一只猫。

然后我们再让它定向修改图片背景。
这不妥妥的就是 AI 抠图/P图!只能说太强了。
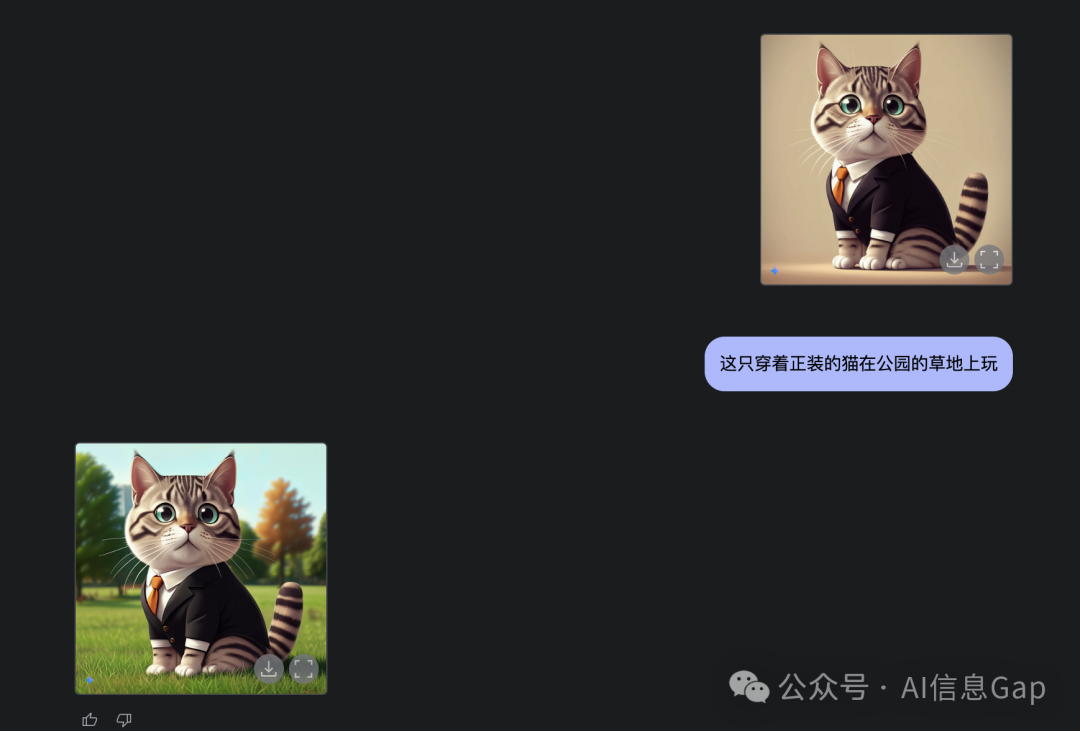
最后放上修改前和修改后的对比图。

结语
提示词简单,边描述边配图,风格极其一致,还能定向修图,谷歌 Gemini 2.0 Flash-Exp 正走在“逆天”的路上。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)