
今天是2025年3月14日,星期五,北京,天气晴。
我们今天来看看Light-R1-32B对R1的复现工作,先说一个结论,复现的是效果,不是路线,这个要区分开,并且这个效果,一定要加上限定,是哪些任务上的效果,Light-R1-32B的评测,其实只是在AIME24、AIME25、GPQA Diamond这些数据集上,是数学领域。思路上是有特色的借鉴意义。
但这也说明了,复现R1的效果,其实路径有很多种,这也是技术魅力之所在,百家争鸣。
当然,在对比的过程中,我们还发现一个细节问题。关于R1的蒸馏模型所用800K数据是用来训练R1的,还是用R1生成的?。我们来抛出这个问题。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、Light-R1-32B对R1的复现认识:复现的是数学特定域效果,而不是路线重现
最近的工作,Light-R1-32B工作【老刘之前所在360智脑大模型团队出品,工作很踏实,但也要限定前提,领域谨慎】,有一些思路,可以看呐看呐。
1)Light-R1-32B:从零复现满血版DeepSeek-R1;
2)Light-R1-32B-DS:在DeepSeek-R1-Distill-Qwen-32B基础上,只需3K数据接近满血版DeepSeek-R1;
3)Light-R1-14B-DS:首次在14B模型上复现强化学习效果,表现超过32B的DeepSeek-R1-Distill-Qwen-32B模型。
项目地址在https://github.com/Qihoo360/Light-R1
模型地址在https://huggingface.co/qihoo360/Light-R1-32B
数据开源地址在https://huggingface.co/datasets/qihoo360/Light-R1-SFTData
技术报告在https://github.com/Qihoo360/Light-R1/blob/main/Light-R1.pdf
但是,虽然说是复现,Light-R1-32B采用课程式SFT与DPO训练,其实并不是严格意义上的R1复线路线,后者是SFT+RL+SFT+RL,前者是SFT+SFT+DPO+Model_Merge。
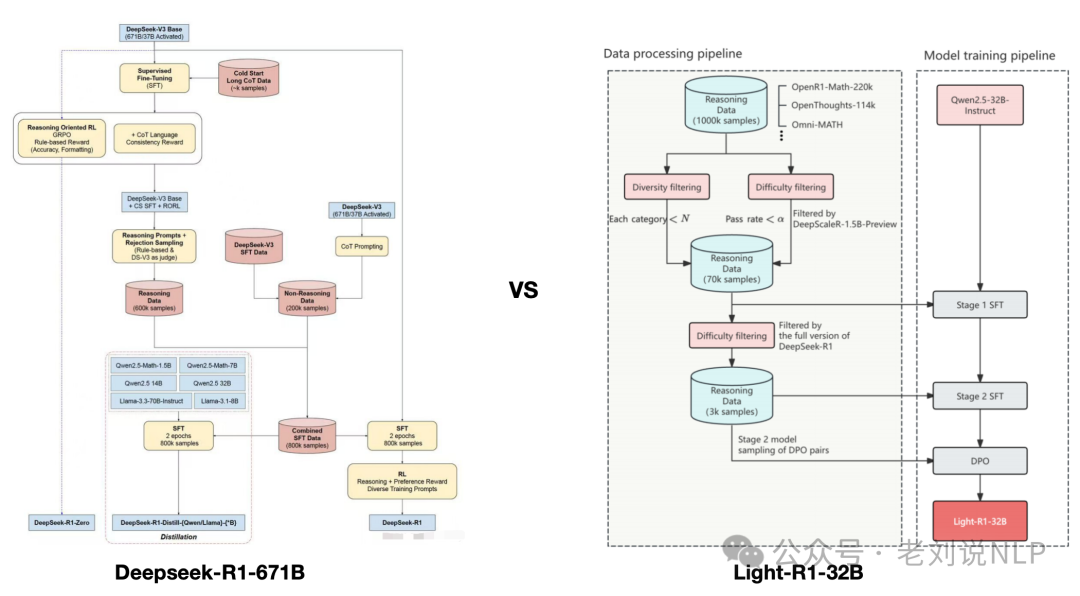
例如,我们来看Light-R1的实现细节:
1)Light-R1-SFT-stage1:收集DeepSeek-R1针对这些问题给出的回答,并通过采样DeepScaleR-1.5B-Preview进行验证与难度评级,筛选后构建了一个包含76k数据的数据集,用于SFT(监督微调)的第一阶段,得到Light-R1-SFT-stage1;
2)Light-R1-SFT-stage2:从这76k数据集中进一步筛选,构建了一个更具挑战性的数据集,包含3k数据,用于SFT的第二阶段训练,得到Light-R1-SFT-stage2。这一阶段的训练使得DeepSeek-R1-Distill-Qwen-32B在AIME 24/25上的表现从72.6/54.9提升至0.779/0.675。
3)Light-R1-SFT-stage2-DPO:采样Light-R1-SFT-stage2的回答,对每个问题的正确与错误回答进行分类,并基于验证结果与DeepSeek-R1的回答构建了DPO(直接偏好优化)配对。基于Light-R1-SFT-stage2,利用360-LLaMA-Factory进行进行DPO。
4)模型融合。融合Light-R1-SFT-stage2、DPO以及另一个AIME24评分为74.7的DPO版本模型。这两个DPO版本的区别在于,其中一个版本在拒绝响应中跳过了特殊标记。
但是,DS-R1则用了五个步骤:SFT冷启动->面向推理的RL->拒绝取样->监督微调SFT->适用于所有场景的强化学习RL。
这意味着DeepSeek-R1实际上是通过监督微调和强化学习对DeepSeek-V3-Base进行的微调,大部分工作是确保生成高质量的样本
在冷启动SFT阶段,使用小型高质量推理数据集(≈5,000个token)对 DeepSeek-V3-Base 进行微调,这样做是为了防止冷启动问题导致可读性差;
在面向推理的强化学习RL中,使用与训练 DeepSeek-V3-Zero 类似的 RL 过程训练生成的模型。但是,添加了另一个奖励措施以确保目标语言保持一致;
在拒绝取样中,利用得到的强化学习模型生成合成推理数据,供后续监督微调使用。通过拒绝采样(基于规则的奖励)和奖励模型(DeepSeek-V3-Base),生成了60万个高质量推理样本。另外,利用DeepSeek-V3和部分训练数据,创建了20万个非推理样本。
在监督微调SFT中,使用得到的800K个样本的数据集对DeepSeek-V3-Base模型进行监督微调;
在适用于所有场景的强化学习RL中,使用与DeepSeek-R1-Zero中类似的方法对生成的模型进行基于RL的训练。为了符合人类的偏好,添加了额外的奖励信号,重点关注有用性和无害性。该模型还被要求总结推理过程以防止可读性问题。
二、R1的蒸馏模型所用800K数据的一个细节问题
但是呢,关于R1的蒸馏模型,目前有个误区。在大家很多人的认识都是,80k用于训练R1,也同样用于训练蒸馏模型,而不是80k是来自于R1。这里都是800k,所以容易产生误解。
也就是生成了800k对V3 进行SFT+RL 得到R1,刚好R1又生成了800k微调qwen?就是下面这张图,可能有问题。

这个主要源自于论文,这句话造成的混淆很大,curated with DeepSeek-R1, as detailed in §2.3.3(这里讲的是训练DeepSeek-R1的800k数据是怎么做的),
在技术报告page16里面说的,其实是用R1生成的。

翻译过来就是:

为了让更高效的小型模型具备像DeepSeek-R1这样的推理能力,划的800k样本直接微调了Qwen和Llama等开源模型。进一步探讨了将推理能力提炼到小型密集模型的问题,使用DeepSeek-R1作为教师模型,生成800K个训练样本,并对多个小型dense模型进行微调。
github地址(https://github.com/deepseek-ai/DeepSeek-R1)中也有说,

那么是否可以这么认识,会更合适一些?论文应该是,发现训练R1的800k数据微调小模型有用,最后为了更好的提炼小模型,使用最终的R1生成了800k去微调,然后效果很好,所以最终这块的数据用的就是R1生成的。也有可能,这里说的R1,指的是中间的checkpoint?
所以,还是那样,很多细节信息,其实都在论文里,大家都可以多深挖。
总结
本文主要看看Light-R1-32B对R1的复现工作,先说一个结论,复现的是效果,不是路线,这个要区分开,并且,这个效果,一定要加上限定,是哪些任务上的效果,Light-R1-32B的评测,其实只是在AIME24、AIME25、GPQA Diamond这些数据集上。
看效果,看路线,要多看技术细节,并且多加限定。
参考文献
1、https://github.com/Qihoo360/Light-R1
2、https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
(文:老刘说NLP)