

赵学亮 投稿
量子位 | 公众号 QbitAI
大模型架构研究进展太快,数据却快要不够用了,其中问题数据又尤其缺乏。
为此,港大和蚂蚁的研究人员反向利用思维链,提出了PromptCoT方法,并基于Llama3.1-8B训练了一个问题生成模型。
实验结果表明,合成的问题难度较开源数据和已有算法有显著提升,接近了AIME水平。

研究团队利用问题生成模型构造了400k SFT数据。
基于这份数据,团队训练了DeepSeek-R1-Distill-Qwen-7B模型,在MATH-500、AIME 2024以及AIME 2025上的表现均超过了32B的s1模型。
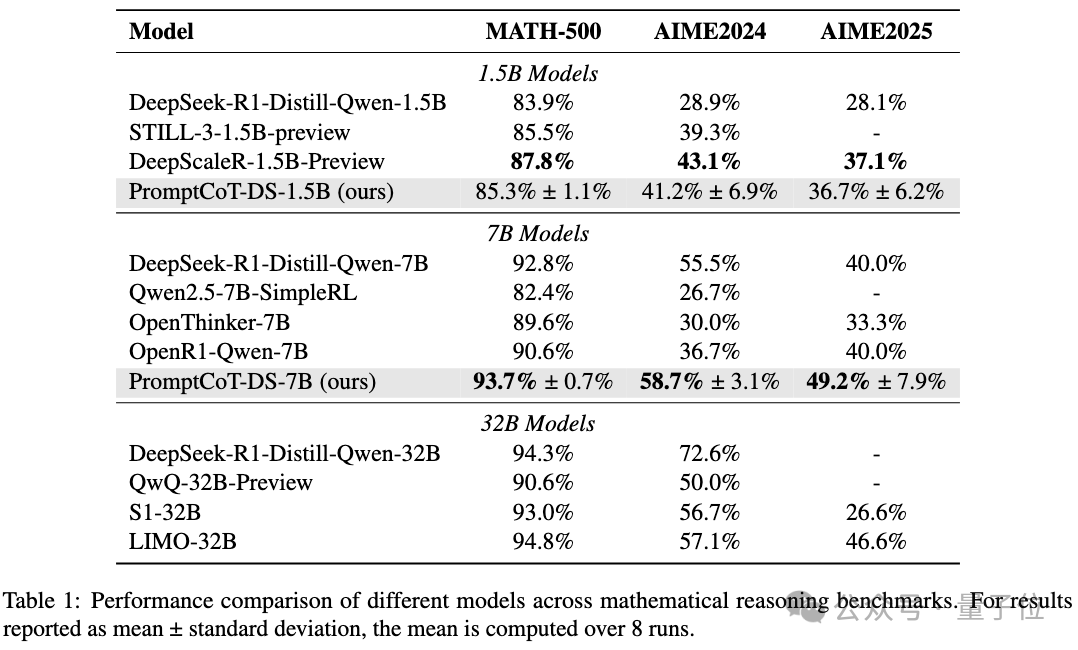
并且相比DeepScaleR-1.5B-Preview,PromptCoT-DS-1.5B仅用1/15的GPU hours即可达到相似的结果。
所有模型和数据均已开源。社区可以根据自己需求合成任意问题数据,用于模型蒸馏或RL训练。
大模型训练缺乏“难题”
当大模型原理“越辩越明”、开源代码越来越多时,数据的不足反而成了限制模型发展的瓶颈。
因为无论是SFT还是RL,一份高质量且颇具挑战的问题数据都是必不可少的,其中,问题数据又尤为重要。
2024年8月,DeepMind的研究阐明了问题挑战性对于模型能力的重要性,但如何能以一种可扩展的方式获得高质量且足够挑战的问题数据呢?
开源社区中虽然有很多数据集(比如NuminaMath和 OpenMathInstruct),但这些数据中“难题”的比例却不高。
简单问题让模型在训练中快速饱和,而困难的问题又不多,这可能是当下研究者在构建推理模型时感到最为受限的地方。
因此,研究团队感到相比又一份训练方法的复现代码,一个能够规模化产生高质量困难问题的模型可能更重要。
那么,能不能把“出题”的任务,也交给大模型呢?
让大模型学会自己出题
开源数据到底够不够难?
在方法设计之前,研究团队先调研了一下已有开源数据(包括开源方法)的问题难度。
由于“难度”是一个相对主观的指标,研究团队考虑了三个指标:
-
大模型在问题上的跑分:相当于找个“好学生”来做题,好学生都不会做,说明题目难。
-
深度思考模型完成题目所需的推理长度:类似的,如果“好学生”需要思考很久才能解一题,说明题目难。
-
用该数据精调一个大模型能带来的收益。

△开源数据(方法)问题难度研究
上表给出了一些典型数据和方法的对比。
从前两列可以看到,和AIME相比,已有数据(或方法)的问题在Qwen2.5-Math-72B-Instruct这样强模型下是比较容易解决的,同时也不需太长的推理。
与之相对,PromptCoT给出的问题无论在跑分上还是在推理长度上都更接近AIME。
同时,PromptCoT也是唯一能让Qwen2.5-Math-7B的base模型在精调后可以超过其Instruct版本的数据(第三、四列,Δ代表精调后和Instruct的差)。
怎样才能合成难题?
在已有方法中,不乏用大模型合成问题的工作(如KPDDS、OpenMathInstruct等),但问题难度上不去,研究团队认为是缺乏一个深入思考的过程。
就像一位经验丰富的老师,不假思索可以给出一些问题,但这些问题要么耳熟能详,要么过于直接。
如果想要出一些有挑战的问题,就需要仔细思考。
因此,研究团队考虑将思维链“倒过来”用于合成“难题”上。具体来说,PromptCoT包含三个步骤:
-
概念抽取;
-
出题逻辑生成;
-
问题生成模型训练。
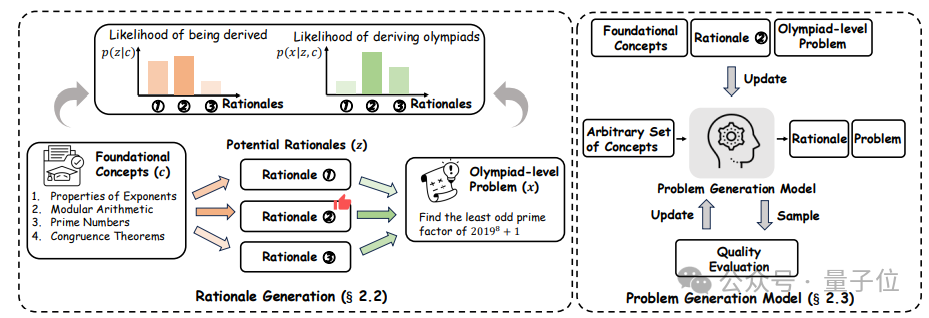
△PromptCoT方法概览
先看第一步,概念抽取。
PromptCoT是以一些数学相关的概念为生成起点的(比如组合数学、概率论等)。
首先从AoPS上抓取6000多个竞赛级数学题作为种子数据,然后通过Prompt一个大模型从中抽取概念,最后将这些概念去重过滤得到概念池。
抽取完成后,就是逻辑生成。
具体来说,给定一组概念以及一个问题,问题生成的目标是最大化,其中对应一个出题逻辑。
通过一些简单的推导,可以得出的最优后验概率是与以及成正比的。那么一个“好”的应该能同时让和最大。
在这样的理论指导下,本工作通过Prompt大模型的方式生成逻辑,具体如下图所示。

△逻辑生成Prompt
确定逻辑之后,就可以对模型进行训练。
首先利用逻辑生成为每条种子数据构造一个问题合成的思考逻辑,得到数据集。
在这些数据基础上,通过模型精调和拒绝采样的方式来训练一个问题生成模型。
其中模型精调(SFT)可以看作是预热阶段,让模型初步掌握合成问题的能力;
而拒绝采样(rejection sampling)可以看作是质检阶段,利用两个额外的大模型给合成的问题打分,只将最高分的问题留下并用作下一轮训练,以让模型在预热阶段后能进一步自我提升,确保生成的问题质量。
训练效果显著增强
合成的问题有用吗?
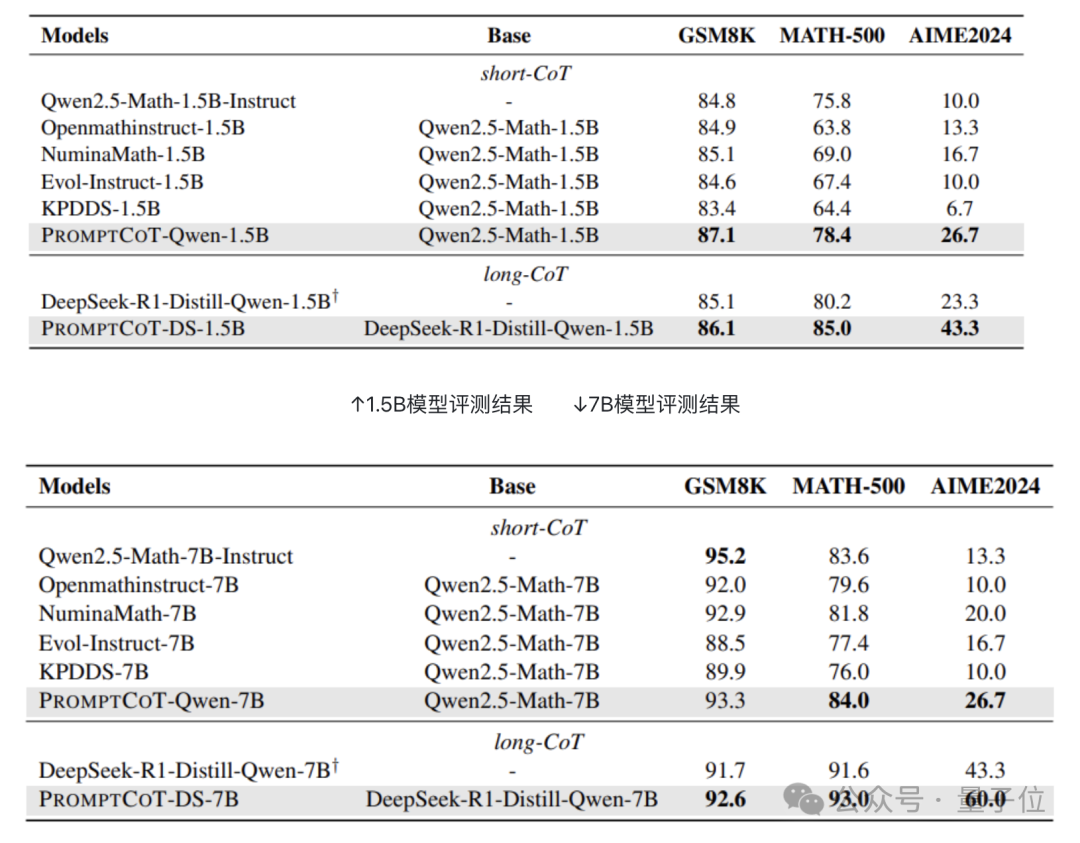
回答这个问题最直接的办法就是用生成的问题数据构造蒸馏数据集,然后观察训练强模型的收益。
这里采用的训练方法是SFT,评估数据采用的是GSM8K,MATH-500,以及AIME 2024,分别代表了小学、高中、以及竞赛级的数学难度。
为了公平比较,Evol-Instruct和KPDDS采用Llama3.1-70B-Instruct做底座。
评估考虑了short-CoT以及long-CoT两种情形。Short-CoT用Qwen2.5-Math-72B-Instruct做教师模型,Qwen2.5-Math-1.5B和7B的base版本做学生模型;
而long-CoT则用DeepSeek-R1-Distill-Qwen-7B做教师模型,DeepSeek-R1-Distill-Qwen-1.5B和7B做学生模型。
下展示了评测结果,可以看到,无论是1.5B模型还是7B模型,PromptCoT都能带来非常显著的增益。
合成数据有无规模效应?
下图展示了随着问题数据规模变大,Qwen2.5-Math-1.5B base模型在MATH-500上的效果变化。
可以看到,与OpenMathInstruct相比,PromptCoT合成的数据具备更加显著的规模效应,这也侧面反映了问题难度对于模型效果的作用。
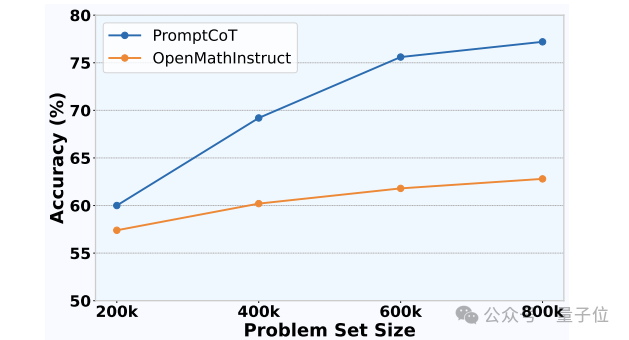
△PromptCoT的数据规模效应
作者简介
该工作第一贡献者为香港大学计算机系博士生赵学亮;
蚂蚁技术研究院武威、关健为共同贡献者。
论文地址:
https://arxiv.org/abs/2503.02324
Github:
https://github.com/inclusionAI/PromptCoT
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)