
今天是2025年3月15日,星期六,北京,天气雪。
春已来,却又雪。咋暖还寒时候,最难将息。
我们今天继续回到RAG话题,看两个话题,一个是视频多模态RAG记忆增强检索,一个是GDELT事件知识图谱构建及与RAG效果评估。
看看这两个话题的话题,可以再次看到有哪些方法可以构建面向RAG的KG,尤其是GDELT这种mysql关系数据库,也可看看各自的缺陷。也可以看看长视频理解RAG怎么做。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、视频多模态RAG记忆增强检索思路
传统多模态大型语言模型(MLLMs)主要针对短视觉输入设计,难以处理长视频的复杂性和高计算成本。

给定特定任务,多模态模型(MMLLs)统一采样帧作为输入,由于粗放的下采样导致显著的信息丢失,标准的RAG缓解了这个问题,但仅限于明确指定的查询。
因此,《Memory-enhanced Retrieval Augmentation for Long Video Understanding》,https://arxiv.org/pdf/2503.09149,提出基于记忆增强的RAG框架,用于长视频理解任务先进行记忆整体视频信息,根据记忆推理任务的信息需求,根据信息需求检索关键时刻。

几个模块:
记忆模块,通过编码整个视频为结构化的记忆来捕捉长程依赖和上下文检索线索。使用预训练的可视编码器将原始视频像素压缩为视觉特征,然后通过Transformer模型将这些特征转换为推理导向的键值缓存。当问题到达时,将预计算的记忆与问题嵌入进行拼接,并进行单次推理,生成检索线索。,具体地,生成4个查询感知线索和草稿答案,随后检索前4个片段、前4个字幕片段和51个全局均匀帧。
推理模块,利用记忆模型R来推断潜在的信息需求 C,通过上下文感知推理来分解查询意图,生成检索线索。这个生成模型需要做微调,使用Qwen2VL-72B生成10000个合成线索和草稿答案,过滤出正确回答问题的线索作为高质量训练标签,并通过直接偏好优化(DPO)生成多样化的线索变体,并使用冻结的视频理解模型的置信度分数评估线索质量。
检索模块 先基于LanguageBind-Large将长视频分割成多个非重叠的固定时长片段(例如10秒),形成可搜索的候选池。对于每个检索线索,计算其与每个片段的相似度,并聚合检索结果。为了保持全局信息和强调证据片段,从信息片段中采样帧并按时间顺序排列,形成一组信息帧,占据总上下文约束的一部分(例如α=0.5),并用均匀采样的帧补充剩余的1-α部分,以确保全局信息的覆盖。最后将所有帧按时间顺序排列,并输入到下游生成模型中进行处理。
聚焦模块 使用检索到的信息性时刻和原始问题合成最终答案。
二、GDELT事件知识图谱构建及与RAG效果评估
如何有效地从非结构化的新闻文章中自动提取和构建知识图谱,以及如何在问答任务中利用这些图谱来提高信息检索的准确性,是当前知识图谱的一个出路。
最近的工作,《Talking to GDELT Through Knowledge Graphs》,https://arxiv.org/pdf/2503.07584,这个工作重点看看,为了研究各种检索增强再生(RAG)方法,以了解每种方法在问答分析中的优缺点。使用了全球事件、语言和语调数据库(GDELT)数据集的案例进行处理。
为什么要说这个,因为之前将事件情报分析中,我们讲过很多,GDELT的重要性很高。
我们先来回顾下。
1、GDELT是什么?
GDELT是大量的新闻报道集合,提供了每15分钟发布一次的全球事件的实时计算记录,汇总了来自各种新闻来源、博客和社交媒体平台的信息,构建了包括人物、组织、地点、主题和情感信息在内的大量数据。
本质上,GDELT提供了世界集体事件的一个快照,使研究人员和分析师能够探索全球社会内部的复杂模式与关系,通过分析这些数据,可以识别新兴趋势、评估风险、理解公众情绪,并追踪各种问题随时间的演变。
GDELT-GKG2则为多个链接表格,记录文章与事件之间的关系信息,因此实际上具有关系数据库的结构,包括三个相关表格组成的数据库:expert.csv捕捉事件信息;GKG.csv 捕捉文章信息;mentions.csv关联哪些文章提到了哪些事件。
如下所示:
 三个表格按事件(绿色)、提及(粉色)和文章(蓝色)进行了颜色编码,单个事件表格以多个绿色子表格显示,仅为了清晰和方便布局一个长记录结构。单头箭头表示表格之间的一对多关系。
三个表格按事件(绿色)、提及(粉色)和文章(蓝色)进行了颜色编码,单个事件表格以多个绿色子表格显示,仅为了清晰和方便布局一个长记录结构。单头箭头表示表格之间的一对多关系。每个事件通过共享的全局事件ID字段映射到多个提及。
每篇文章通过文章一侧的文档标识符字段与提及一侧的提及标识符字段匹配,映射到多个提及。通过这种方式,提及表格充当一个“配对文件”,记录事件与文章之间的多对多关系:每个事件可以在多篇文章中被提及,并且每篇文章也可以提及多个事件。
每篇文章也通过全球知识图谱记录ID或文档标识符字段具有唯一标识符,因为全球知识图谱数据中的每一行代表一篇文章。
2、怎么把GDELT变成知识图谱?
1)图谱本体如何定义?
首先,看图谱的定义。可以使用一个从上述关系模式派生的本体作为图类型模式,将(部分)GDELT数据库转换为知识图谱(KG)。
如图2所示,
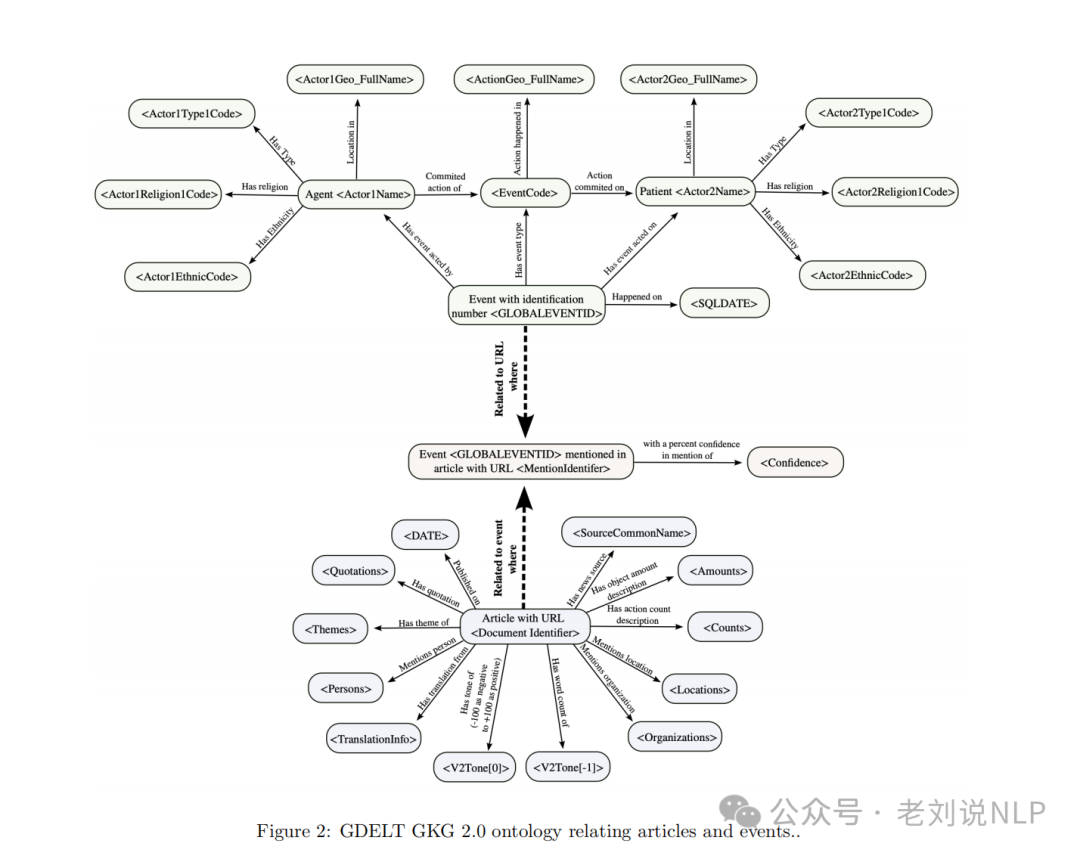
本体中的节点表示KG中可能的节点类型;节点通过颜色编码来指示其来源关系表;尖括号内的字段表示模式中的字段名称;实线边表示关系表中的一个字段,并用语义关系的类型标记;虚线和粗线边表示关系模式中的结构性一对多关系。
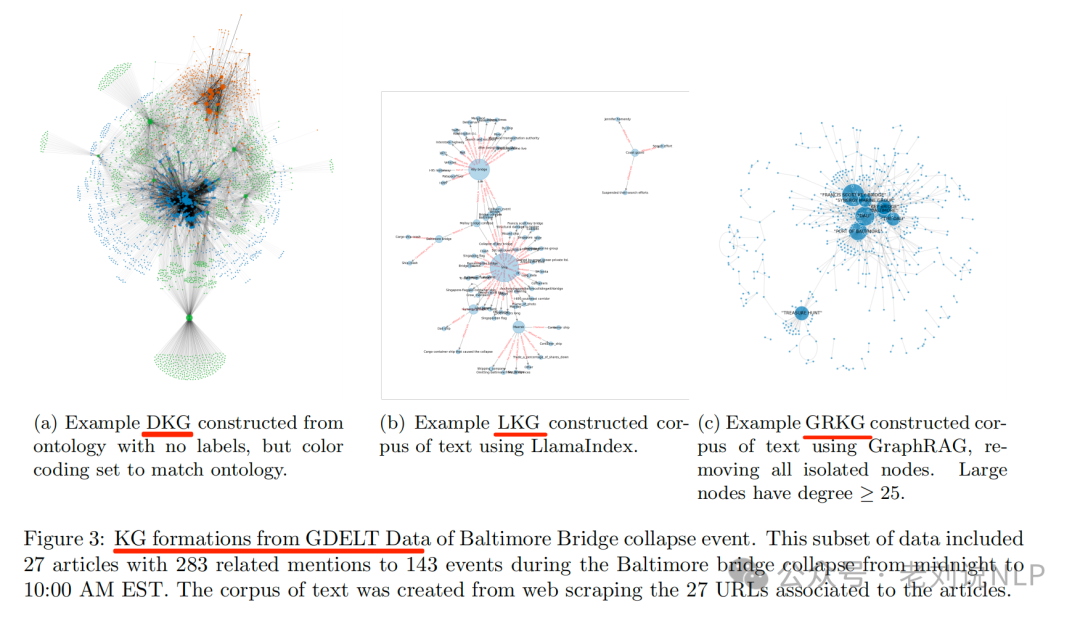
2)三种不同的知识图谱形态及构件方式?
构建三种知识图谱,直接知识图谱(DKG)、LlamaIndex知识图谱(LKG)和GraphRAG知识图谱(GRKG)。
技术实现方式如下:
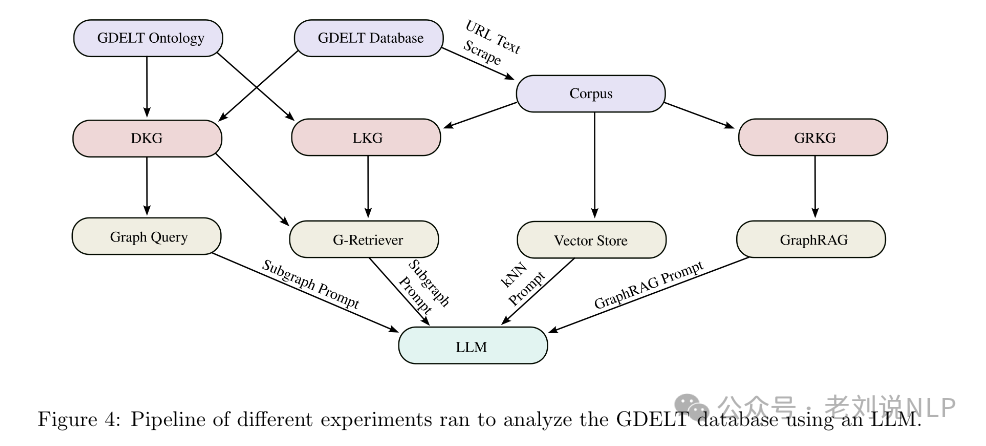
Direct KG(DKG),将GDELT数据集的子集直接转换为知识图谱,使用预定义的本体作为图的类型模式。节点表示可能的节点类型(如事件、文章、提及等),边表示关系类型(如相关于事件、提及人员、提及地点等)。
LlamaIndex KG(LKG), 使用LLM(如Mixtral-8x7B)处理源文章文本,提取三元组并根据简化的本体结构进行提示。尽管LLM在遵循本体结构方面存在困难,但仍然能够生成有用的知识图谱。
GraphRAG KG(GRKG),使用Microsoft的GraphRAG包,采用默认配置参数,从相同的文章文本中生成知识图谱,GraphRAG不依赖于预定义的本体,自动生成关系和实体。
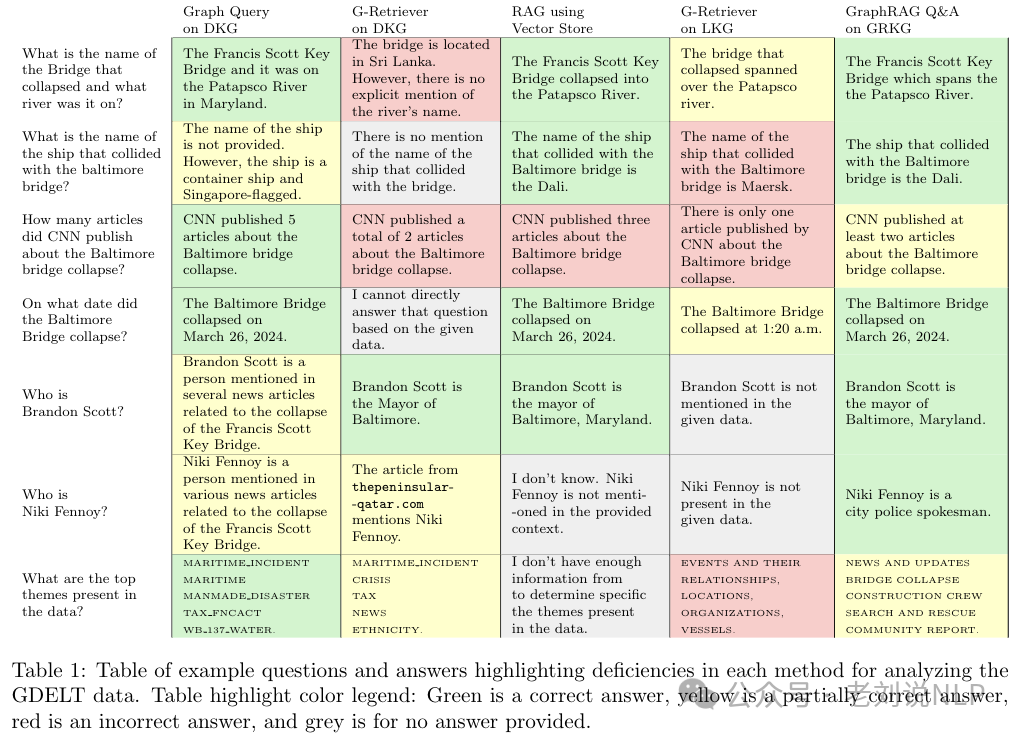
其对应的结果也有趣,直接从GDELT数据转换的KG,能够回答高层次和聚合问题;使用LLM生成的KG,虽然捕捉了事件摘要,但缺乏一致性和可解释性;使用GraphRAG生成的KG,在细粒度问题上表现较好,但在全局问题上仍有改进空间。
参考文献
1、https://arxiv.org/pdf/2503.07584
2、https://arxiv.org/pdf/2503.09149
(文:老刘说NLP)