

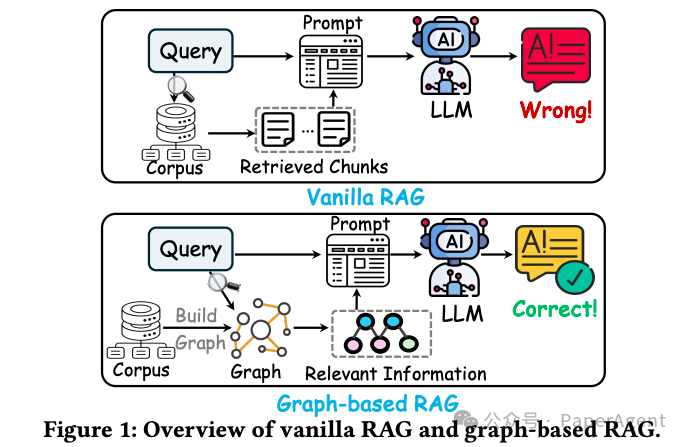
随着大语言模型(LLM)的快速发展,其在特定领域查询中仍存在“幻觉”问题,即生成的内容可能不准确或信息过时。此外,大模型训练更新的代价高昂,且缺乏对专业领域知识的有效整合。
Graph-based RAG方法通过构建结构化的知识图谱,将外部知识有效地引入LLM,能够显著提高内容准确性、适应性与可信度。然而,现有Graph-based RAG方法缺乏系统性的比较和统一的标准评测。

一、核心亮点
模块化框架 = 无限灵活性
统一框架实现了各组件的灵活组合,满足多样任务需求。
流程化开发 = 便捷搭建与对比
将复杂的RAG方法拆解为四个明确阶段,便于快速构建、调整与比较。
公平基准测试 = 可复现的结果
标准化测试平台确保了各方法之间公平、可重复的对比评估。
代码全部开源
二、主要贡献与创新
统一框架
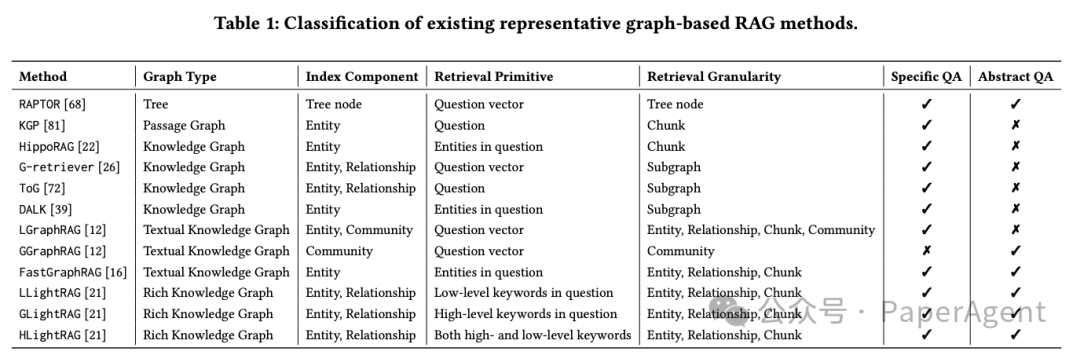
构建了一个全面的框架,覆盖主流十几种基于图的RAG方法,打破传统方法局限。
模块化解耦
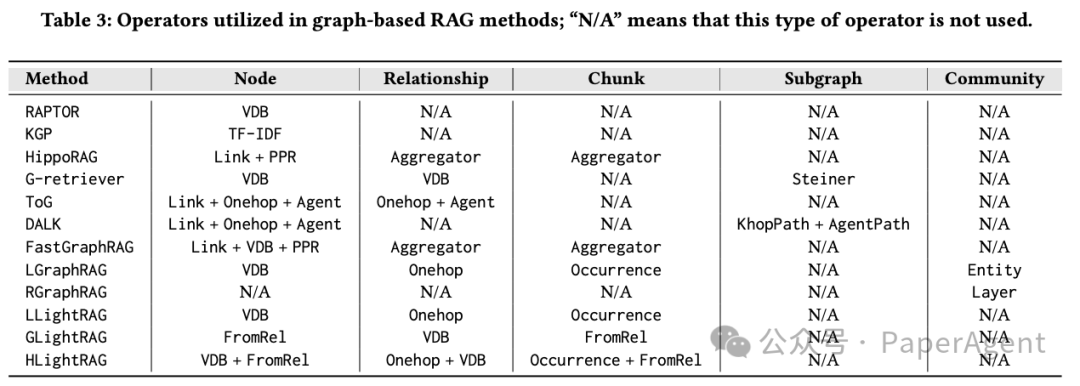
在检索阶段提出了19种算子,按节点、关系、文本块、子图和社区五大类别分类,支持灵活组合生成新算法变种。
超强实验验证
通过大量问答数据集实验,对比现有方法并发掘出两种全新SOTA算法,展示了优越的性能。
三、方案
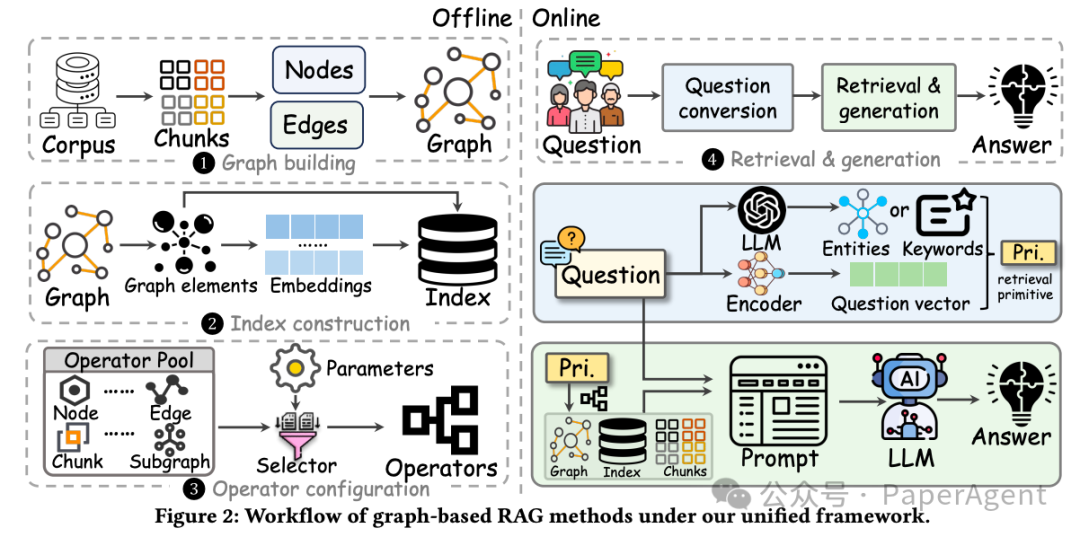
本文首次提出了一个统一的Graph-based RAG框架,清晰定义了四个关键流程,全面涵盖了主流十余种图增强生成方法:
-
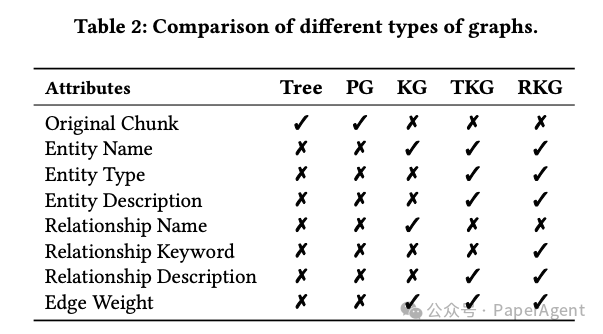
图构建(Graph Building) :基于原始语料构建知识图谱,支持五种类型的图结构(Passage Graph、树、知识图谱、文本知识图谱和丰富知识图谱)。
-
索引构建(Indexing) :针对节点、关系和社区建立索引,提升在线检索效率。
-
算子配置(Operators Configuration):提出19种模块化检索算子,覆盖节点、关系、文本块、子图、社区等多个检索粒度,可任意组合实现各种方法。
-
检索与生成(Retrieval & Generation):高效地检索相关信息,并利用LLM生成准确回答。
图类型探索
-
探索了5种图类型:Passage Graph、树、知识图谱、文本知识图谱以及丰富知识图谱
索引构建
-
提供3种索引方式:节点索引、关系索引和社区索引,用于高效检索
算子池
-
利用19种不同的检索算子,实现从低级节点到高层社区报告的多级检索策略,简化复杂RAG方法的开发与比较
四、结论与成果
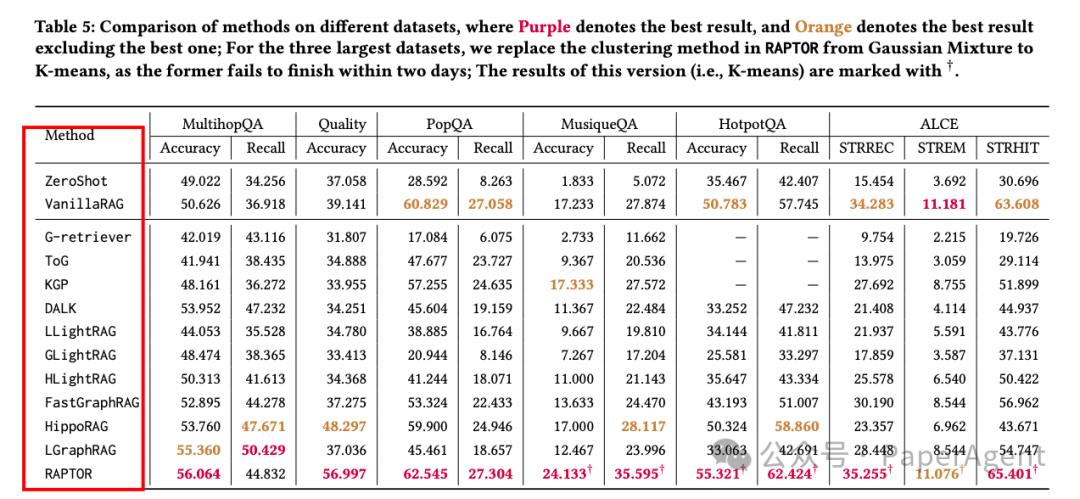
通过全面的实验分析,作者不仅验证了Graph-based RAG方法在特定查询任务中的优势,还发现并提出了两种全新的SOTA算法,在复杂问答任务中显著超过了现有方法。
核心发现
Graph-based RAG整体优于传统RAG方法,尤其是在复杂的多跳推理任务和抽象概念问答任务中。
不同的图类型和检索策略显著影响模型性能,社区级别的信息检索对抽象问题尤其有效。
面向未来的研究机会
探讨在动态更新的外部知识(如实时变化的维基百科)场景下如何高效适应。
设计更加节省代价但高效的图构建方法,提升图质量评估与构建效率。
结合更多原始文本信息和高层结构化知识,推动RAG领域的持续突破。
论文详情:https://arxiv.org/abs/2503.04338In-depth Analysis of Graph-based RAG in a Unified Framework源代码:https://github.com/JayLZhou/GraphRAG
(文:PaperAgent)