

📢本周AI快讯 | 1分钟速览🚀
1️⃣ ❌ DeepSeek-R2 传闻被辟谣 :官方声明 3 月 17 日发布 R2 模型为不实消息,公司尚未公布具体发布时间和技术细节。市场预期或在 5 月发布。
2️⃣ 🤝 Manus 牵手阿里千问 :双方达成战略合作,基于通义千问系列开源模型打造国产创造力通用智能体产品,合作将加速中文语境适配。
3️⃣ 🚀 清华开源赤兔推理引擎 :首次实现非英伟达架构 GPU 及国产芯片原生运行 FP8 精度模型,部署 DeepSeek-R1-671B 时比国外框架速度提升 3.15 倍,GPU 使用减少 50%。
4️⃣ 🖼️ 谷歌发布 Gemini 2.0 Flash :首个面向公众的全模态模型,支持通过自然语言指令进行图像生成和编辑,具备文本与图像结合、对话式编辑和长文本渲染等特点。
5️⃣ 💪 谷歌推出 Gemma 3 小模型 :号称”全球最强单加速器模型”,仅需单块 H100 GPU 即可高效运行,支持 35+ 种语言和图像分析,Elo 得分达 1338,超越需多 GPU 的竞品。
6️⃣ 📊 谷歌发布 Gemini Embedding :新文本处理模型在 MTEB 评测中以 68.32 分居首,支持 8K tokens 输入,可输出高达 3K 维向量,覆盖 100+ 种语言。
7️⃣ 🤖 OpenAI 推出 Agent 开发工具 :包括 Responses API、内置工具和 Agents SDK,简化 AI 智能体开发流程,深度融合对话功能与内置工具,降低开发门槛。
8️⃣ 🔍 Cohere 发布 Command A 模型 :轻量级模型仅需两块 A100/H100 GPU 运行,支持 256K 长上下文,每秒输出 156 个 Token,比 GPT-4o 快 1.75 倍,支持 23 种语言。
9️⃣ 💰 谷歌投资 Anthropic 超 30 亿美元 :持有约 14% 股份但无投票权与董事席位,计划再注资 7.5 亿美元,Anthropic 近期估值达 615 亿美元,保持独立运营。
1. DeepSeek-R2 模型 3 月 17 日发布为不实消息
近日,有媒体报道称,DeepSeek 将于 3 月 17 日发布其下一代 AI 模型 DeepSeek-R2,并宣称该模型在编程能力、多语言推理能力等方面取得重大突破。
然而,DeepSeek 官方很快公开辟谣,表示此消息纯属虚构,强调公司尚未公布 R2 模型的具体发布时间和技术细节。
此前,市场预期 DeepSeek-R2 模型将于 5 月发布。
2. Manus 与阿里千问团队达成战略合作
3 月 11 日,AI 创业公司 Manus 宣布与阿里巴巴旗下的通义千问团队正式达成战略合作。双方将基于通义千问系列开源模型,致力于在国产模型和算力平台上实现 Manus 的全部功能。目前,两家技术团队已展开紧密协作,旨在为中国用户打造更具创造力的通用智能体产品。

阿里巴巴方面确认了这一合作,并表示期待与更多全球 AI 创新者开展合作。此前,Manus 创始人季逸超曾透露,其产品采用了基于阿里千问大模型(Qwen)的多个微调模型。
Manus 于 3 月 6 日发布了首款 AI 智能体产品,被定义为“全球第一款通用 Agent 产品”,具备多领域任务处理、复杂任务规划与执行、工具调用与自动化、自主学习与优化以及实时交互与协作等核心功能。发布后引起广泛关注,但其主页面一直为英文界面,尚未完成足够的中文语境适配。
3. 清华开源大模型推理引擎 赤兔 Chitu
3 月 14 日,清华大学高性能计算研究所翟季冬教授团队与清华系科创企业清程极智联合宣布,正式开源大模型推理引擎 赤兔 Chitu。该引擎首次实现了在非英伟达 Hopper 架构 GPU 及各类国产芯片上原生运行 FP8 精度模型,打破了对特定硬件的依赖,为国产 AI 芯片的广泛应用和生态建设带来了新的突破。
在实际应用中,赤兔 推理引擎在部署 DeepSeek-R1-671B 满血版时,在 A800 集群的测试中,相比部分国外开源框架,GPU 使用量减少 50% 的情况下推理速度仍有 3.15 倍的提升。这意味着企业可以用更少的硬件资源获得更高的推理性能,极大降低了部署门槛和运营成本。

目前,赤兔 引擎已适配英伟达多款 GPU 及多款国产芯片,目标是建立覆盖从纯 CPU 到大规模集群的全场景大模型部署需求。
4. 谷歌发布全模态模型 Gemini 2.0 Flash
3 月 13 日,谷歌正式发布了其首个面向公众的全模态模型 Gemini 2.0 Flash,为用户提供了通过自然语言指令进行图像生成和编辑的全新体验。这一功能的推出,使用户只需“动动嘴”,即可完成对图像的修改和创作,轻松制作海报、表情包等多种视觉内容。

Gemini 2.0 Flash 的主要特点包括:
-
文本与图像结合:根据用户的文字描述,生成连贯且符合上下文的图像。例如,在创作故事时,模型可自动生成与情节相匹配的插图,并在整个故事中保持角色和场景的一致性。
-
对话式图像编辑:用户可通过自然语言指令,对图像进行多轮次的编辑和优化,无需专业软件或复杂操作。例如,用户可以要求模型在图像中添加或移除元素,调整颜色等,模型会根据指令实时作出相应修改。
-
基于世界知识的图像生成:模型融合了世界知识和增强推理能力,能够生成更符合现实逻辑的图像。例如,在制作食谱时,模型不仅能提供详细的步骤说明,还能生成对应的菜品图片,提升用户体验。
-
长文本渲染:在处理包含大量文本的图像时,
Gemini 2.0 Flash表现出色,能够准确呈现清晰、可读的文字内容。这对于需要制作广告、社交媒体帖子或邀请函的用户来说,具有重要意义。
5. 谷歌发布号称最强的小参数模型 Gemma 3
3 月 12 日,谷歌正式发布了最新的开源 AI 模型 Gemma 3,声称这是全球最强的单加速器模型。该模型经过优化,可在单块英伟达 H100 GPU 或谷歌的 TPU 上高效运行,性能表现超越了 DeepSeek 的 R1(需要 34 块 H100)和 Meta 的 Llama 3(需要 16 块),突显了 AI 推理阶段的成本效益优势。
Gemma 3 支持超过 35 种语言,具备分析文本、图像及短视频的能力。其升级的视觉编码器支持高分辨率和非方形图像,并包含 ShieldGemma 2 图像安全分类器,以过滤露骨或暴力内容。谷歌表示,Gemma 3 是“世界上最好的单加速器模型”,在配备单个 GPU 的主机上的性能表现超越了 Facebook 的 Llama、DeepSeek 和 OpenAI 等竞争对手。

在 Chatbot Arena Elo 分数排行榜上,Gemma 3 的性能优势明显。只需一块 NVIDIA H100 GPU,其旗舰版 270 亿参数模型就跻身顶级聊天机器人之列,Elo 得分高达 1338。而许多竞品需要多达 32 块 GPU 才能达到相似表现。
目前,Gemma 3 可直接在 Google AI Studio 上体验,并可在 Hugging Face、Ollama 或 Kaggle 等平台下载后自行部署使用。
6. 谷歌推出嵌入模型 Gemini Embedding
3 月 7 日,谷歌发布了全新的文本处理模型 Gemini Embedding,现已集成至 Gemini API。在 Massive Text Embedding Benchmark(MTEB)中,Gemini Embedding 以平均任务得分 68.32 的成绩,超越了 Mistral、Cohere 和 Qwen 等竞争对手,荣登榜首。

Gemini Embedding 的技术亮点:
-
强大的性能:支持 8K tokens 的输入长度,输出向量维度高达 3K,并可根据需求灵活调整向量维度(3K、2K、1K 或 512),以节省存储空间。
-
卓越的语义理解能力:无需额外微调,即可在金融、法律、医学等复杂领域精准捕捉文本中的细微语义差异。
-
广泛的多语言支持:支持 100 多种语言,在跨语言翻译、多语言客户服务自动化和内容排名等应用场景中具有显著优势。
7. OpenAI 推出全新 AI Agent 开发者工具
3 月 11 日,OpenAI 发布了一系列新的开发者工具,旨在简化 AI 智能体的开发流程,增强其功能和技能。
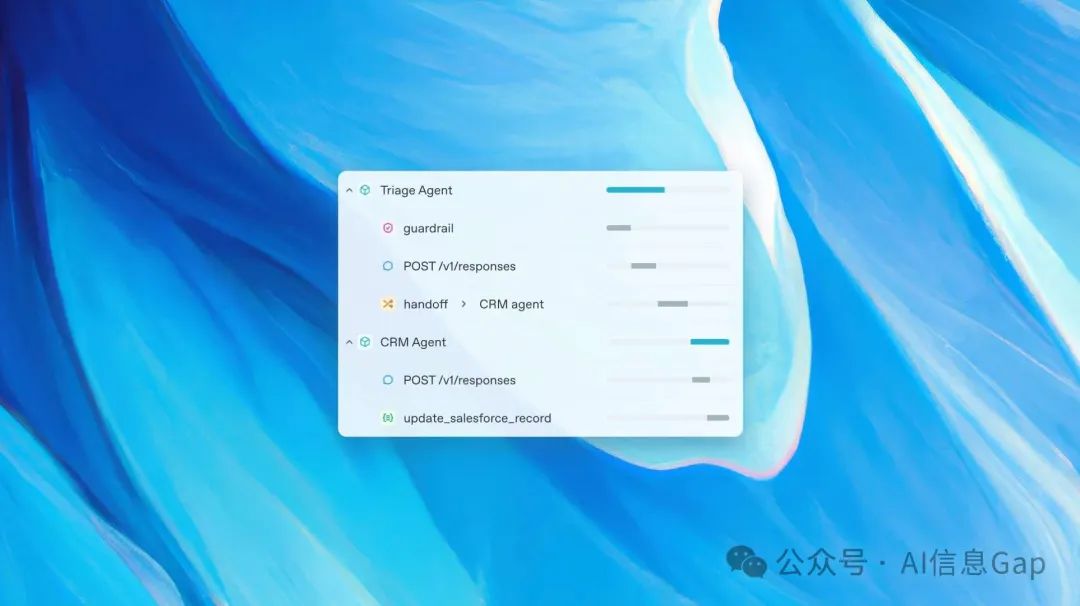
主要更新内容包括:
-
Responses API:这一全新的 API 将对话功能与内置工具深度融合,开发者无需集成多个 API 或依赖外部供应商,即可在应用中轻松结合 OpenAI 模型和工具。
-
内置工具:提供网络搜索、文件搜索和计算机使用等功能,帮助智能体获取实时信息、查找文件内容,并在用户授权下执行计算机任务。
-
Agents SDK:这套开发工具包简化了智能体的核心逻辑、编排和交互,降低了开发者构建智能体的入门门槛。
OpenAI 表示,随着模型功能的不断发展,Responses API 将为构建智能体的开发者提供更灵活的基础。只需一次 Responses API 调用,就能使用多种工具和模型转换来解决复杂任务。
8. Cohere 推出小参数模型 Command A
3 月 13 日,加拿大 AI 初创公司 Cohere 正式发布了其最新的轻量级 AI 模型 Command A。该模型主打高效、低成本部署,号称仅需两块英伟达 A100 或 H100 GPU 即可顺畅运行,而同级别竞品通常需要十几甚至几十块 GPU。与此同时,Command A 在处理复杂任务时的性能表现却能与 OpenAI 的旗舰模型 GPT-4o 相媲美。

据 Cohere 官方公布的数据显示,Command A 在性能指标上表现亮眼:它支持长达 256K 的长上下文输入,同时每秒输出的 Token 数可达到 156 个,比 GPT-4o 快约 1.75 倍,比 DeepSeek 的 DeepSeek-V3 快约 2.4 倍。此外,Command A 支持 23 种语言,且在指令追踪、SQL 查询、智能代理任务等企业级应用场景中表现突出。
目前,Cohere 已经通过自家平台发布了 Command A,并通过 Hugging Face 平台面向学术界开放使用权限。
9. 谷歌对 Anthropic 投资超 30 亿美元
近期披露的法庭文件显示,谷歌已累计向人工智能初创公司 Anthropic 投资超过 30 亿美元,持有该公司约 14% 的股份。尽管谷歌是大股东之一,但并未在 Anthropic 拥有投票权或董事会席位。此外,谷歌计划在今年通过可转换债券交易,再向 Anthropic 注资 7.5 亿美元。
Anthropic 成立于 2021 年,由前 OpenAI 成员创立,专注于开发通用 AI 系统和语言模型,致力于负责任地使用 AI 技术。该公司近期完成了 35 亿美元的融资,估值达到 615 亿美元。除了谷歌,亚马逊也在 2023 年对 Anthropic 投资了 40 亿美元,并计划在 2024 年底再投资 40 亿美元。
尽管谷歌和亚马逊等科技巨头对 Anthropic 投资巨大,但由于缺乏投票权和董事会席位,Anthropic 仍保持独立运营。此前,美国司法部曾建议法院强制谷歌出售可能与其搜索业务竞争的 AI 产品,包括其在 Anthropic 的股份,但这一提议已被撤回。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)