
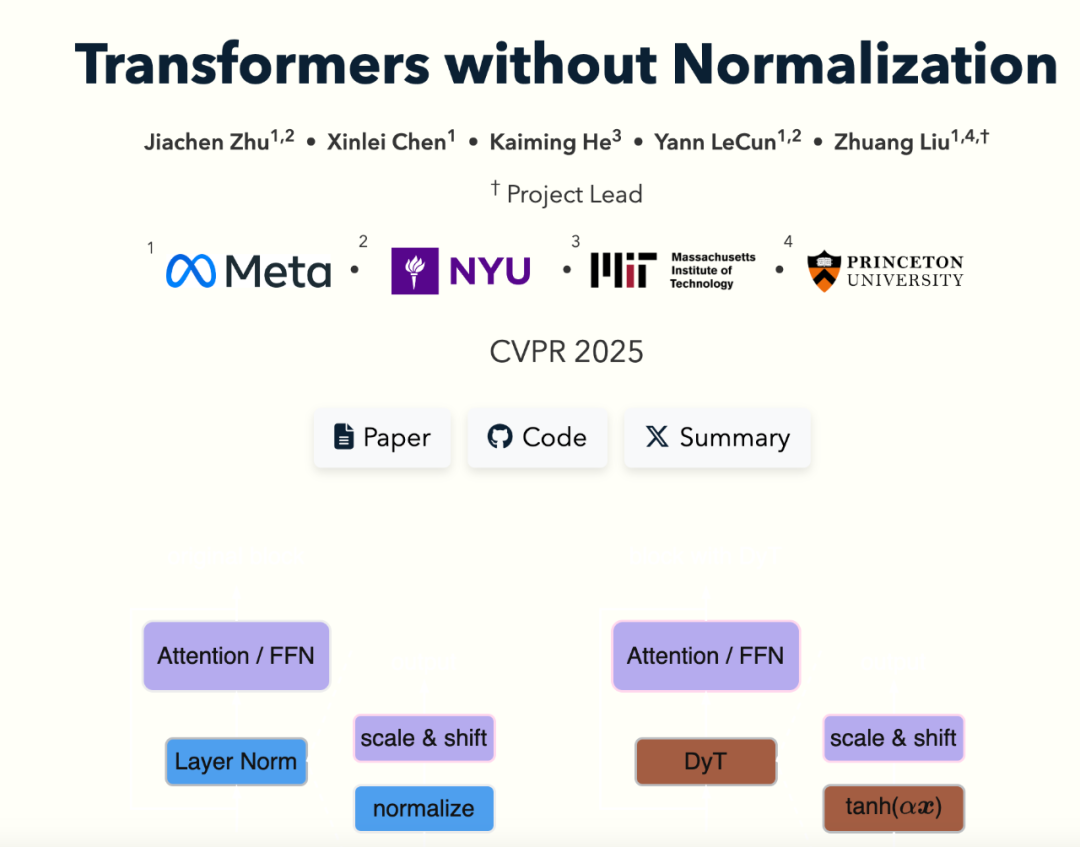
来自Meta AI的华人科学家刘壮团队,联合AI大神何恺明, 图灵奖得住Yann LeCun等大牛搞了个大新闻——他们的最新论文证明了:Transformer 模型,竟然可以不用Normalization(归一化)层也能达到甚至超越现有性能!,论文已经被CVPR 2025接收
Normalization层在现代神经网络中几乎是标配,大家都觉得它是必不可少的“定海神针”。但刘壮团队却打破了这个固有认知,简单来说事实证明,你可以用参数化的 tanh() 代替正则化层来训练深度网络
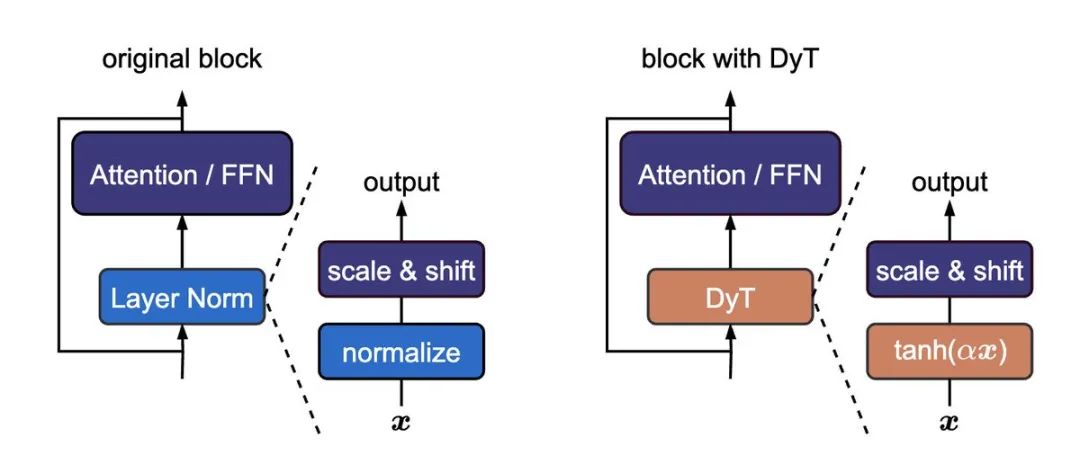
核心秘密:Dynamic Tanh (DyT),一个“复古”又强大的替代品!
他们的秘诀是什么呢?答案出乎意料地简单:Dynamic Tanh (DyT)。没错,就是那个我们在上世纪80年代就见过的 tanh 函数!
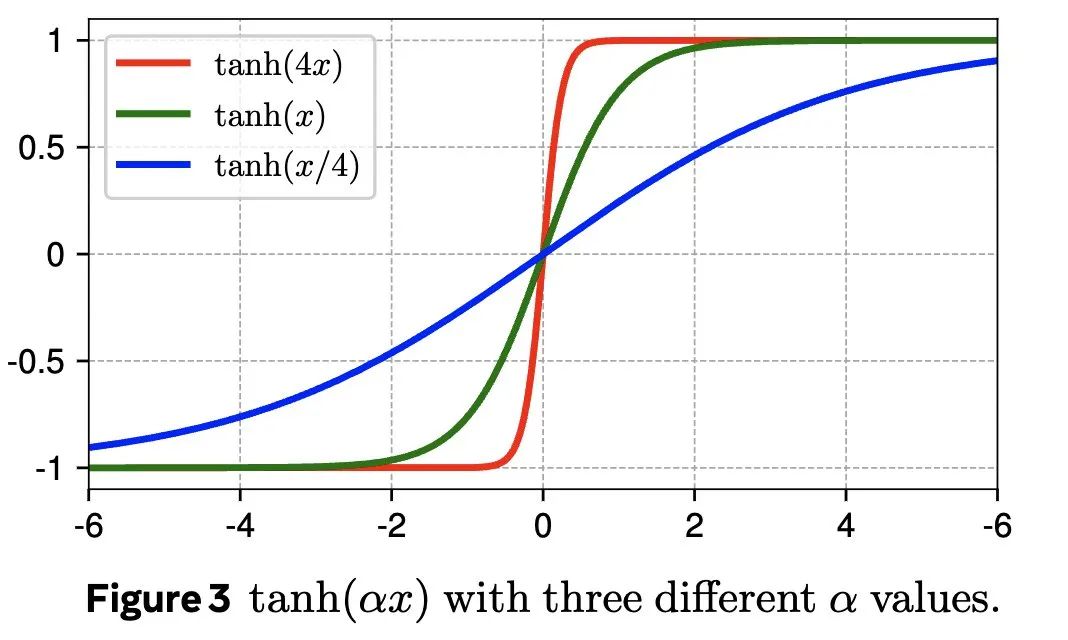
DyT 的公式也很简洁:DyT(x) = tanh(αx),其中 α 是一个可学习的缩放因子。这个操作简单来说,就是先通过 α 调整输入激活值的范围,然后再用 tanh 函数进行“挤压”,把极端值压下去
为什么要用 DyT?
庄刘团队的灵感来自于一个朴素的观察:Layer Normalization 在 Transformer 中,经常会产生类似 tanh 函数的 S 型输入输出映射。也就是说,LayerNorm 实际上也在做类似“挤压”的操作

既然如此,为什么不直接用 tanh 函数呢?
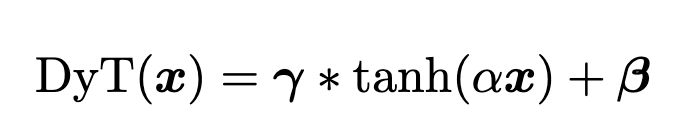
DyT 的优势:性能不输,速度更快,成本更低!
更让人惊喜的是,DyT 不仅简单,而且非常有效!刘壮团队在各种不同的任务和模型上进行了验证,发现:
-
• 覆盖面广: 从图像识别到生成,从监督学习到自监督学习,从计算机视觉到语言模型,DyT 都能胜任 -
• 模型适用性强: ViT、ConvNeXt、MAE、DINO、DiT、LLaMA、wav2vec 2.0、HyenaDNA、Caduceus,这些当下最火的模型,都能用 DyT 来替换 Normalization 层 -
• 性能给力: 在大多数情况下,DyT 都能达到或超越原有 Normalization 层的性能,而且几乎不需要额外的超参数调整 -
• 速度更快: 在 H100 这样的高端 GPU 上,DyT 甚至比 RMSNorm (一种在大型语言模型中常用的 Normalization 层) 还要快! -
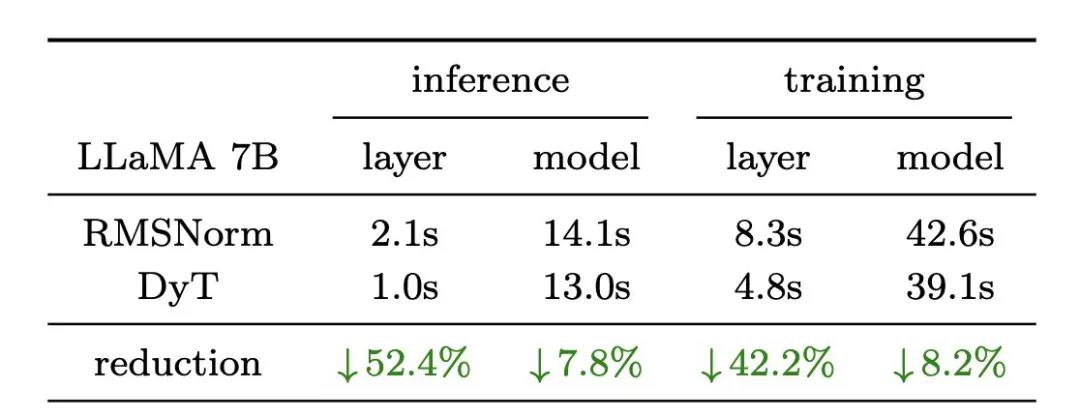
这意味着什么?
这意味着,我们可以用更简单、更快速的方法,训练出性能更好的 Transformer 模型!考虑到模型训练和推理需要耗费大量的计算资源,DyT 有潜力为我们节省大量的成本
代码和论文地址:
-
• 论文: http://arxiv.org/abs/2503.10622 -
• 代码和网站: http://jiachenzhu.github.io/DyT/
⭐
(文:AI寒武纪)