

©PaperWeekly 原创 · 作者 | 王琦、李佳键
单位 | 上海交大、宁波东方理工大学
研究方向 | 强化学习、世界模型
LS-Imagine 通过纯视觉观测来玩 Minecraft,仿照人类玩家的做法来学习 RL 控制策略,不开外挂,不使用特权信息。
在高维开放世界中训练视觉强化学习智能体面临诸多挑战。尽管有模型的强化学习方法(MBRL)通过学习交互式世界模型提高了样本效率,但这些智能体往往具有“短视”问题,因为它们通常仅在短暂的想象经验片段上进行训练。
我们认为,开放世界决策的主要挑战在于如何提高在庞大状态空间中的探索效率,特别是对于那些需要考虑长期回报的任务。
所以,我们提出了一种新的强化学习方法:LS-Imagine,通过构建一个长短期世界模型(Long Short-Term World Model),在目标驱动的情况下模拟跳跃式状态转换,并通过放大单张图像中的特定区域计算相应的功用性图(Affordance Map)来实现在有限的状态转移步数内扩展智能体的想象范围,使其能够探索可能带来有利长期回报的行为。

论文标题:
Open-World Reinforcement Learning over Long Short-Term Imagination
论文作者:
李佳键*,王琦*,王韫博(通讯作者),金鑫,李洋,曾文军,杨小康(* 共同一作)
项目网址:
https://qiwang067.github.io/ls-imagine
论文链接:
https://openreview.net/pdf?id=vzItLaEoDa
代码链接:
https://github.com/qiwang067/LS-Imagine

简介
在强化学习背景下,开放世界中的决策具有以下特征:
1. 广阔的状态空间:智能体在一个具有巨大状态空间的交互式环境中运行;
2. 高度灵活的策略:所学习的策略具有较高的灵活性,使智能体能够与环境中的各种对象进行交互;
3. 环境感知的不确定性:智能体无法完全观测外部世界的内部状态和物理动力学,即其对环境的感知(例如,原始图像)通常具有较大的不确定性。
例如,Minecraft 是一个典型的开放世界游戏,符合上述特性。
基于最近在视觉控制领域的进展,开放世界决策的目标是训练智能体仅基于高维视觉观测来接近人类级别的智能。然而,这也带来了诸多挑战。例如在 Minecraft 任务中:
-
基于高层 API 的方法(如 Voyager)由特定环境的 API 进行高层控制,不符合标准的视觉控制设定,限制了泛化能力和适用范围。
-
无模型强化学习方法(如 DECKARD)缺乏对环境底层机制的理解,主要依赖高成本的试错探索,导致样本利用率低,探索效率不佳。
-
有模型的强化学习方法(如 DreamerV3)尽管提高了样本效率,但由于仅依赖短期经验优化策略,智能体表现出“短视”问题,难以进行有效的长期探索。
为了提高有模型强化学习过程中行为学习的效率,我们提出了一种新方法——LS-Imagine。该方法的核心在于使世界模型能够高效模拟特定行为的长期影响,而无需反复进行逐步预测。

▲ 图1:LS-Imagine 的整体框架
如图 1 所示,LS-Imagine 的核心在于训练一个长短期世界模型(Long Short-Term World Model),在表征学习阶段融合任务特定的指导信息。
经过训练后,世界模型可以执行即时状态转换和跳跃式状态转换,同时生成相应的内在奖励,从而在短期与长期想象的联合空间中优化策略。跳跃式状态转换使智能体能够绕过中间状态,直接在一步想象中模拟任务相关的未来状态 ,促使智能体探索可能带来有利长期回报的行为。
然而,这种方法引发了一个经典的“先有鸡还是先有蛋”的问题:
如果没有真实数据表示智能体已经达成目标,我们如何有效训练模型以模拟从当前状态跳跃式转换到未来和目标高度相关的状态?
为了解决这个问题,我们在观察图像上针对特定区域不断执行放大(Zoom in)操作以模拟智能体在接近该区域过程中的连续观察视频帧,并将这段视频帧与任务的文本描述进行相关性评估,从而生成功用性图用于突出观察中与任务相关的潜在关键区域。
在此基础上,我们通过与环境交互收集来自相邻时间步长的图像观察对以及跨越较长时间间隔的图像对作为数据集,对世界模型的特定分支进行训练,使其能够执行即时状态转换和跳跃式状态转换。
世界模型训练完成后,我们基于世界模型生成一系列想象的隐状态序列,优化智能体的策略。在决策的过程中,可以借助跳跃式状态转换直接估计长期回报,从而增强智能体的决策能力。

主要创新点和贡献
我们提出了一种新颖的有模型强化学习方法,能够同时执行即时状态转换和跳跃式状态转换,并将其应用于行为学习,以提高智能体在开放世界中的探索效率。
LS-Imagine 带来了以下四点具体贡献:
1. 长短期结合的世界模型架构;
2. 一种通过图像放大模拟探索过程以生成功用性图的方法;
3. 基于功用性图的新型内在奖励机制;
4. 一种改进的行为学习方法,该方法结合了长期价值估计,并在混合的长短期想象序列上运行。

方法
LS-Imgaine 包含以下的关键的算法步骤:
3.1 功用性图计算
如图 2 所示,为了生成功用性图,我们在不依赖真实成功轨迹的情况下模拟并评估智能体的探索过程。

▲ 图2:功用性图计算过程
具体而言,对于单帧观察图像,我们使用一个滑动边界框从左至右、从上至下遍历扫描整张观察图像。对于滑动边界框所在的每个位置,我们从原始图像开始裁剪出 16 张图像,以缩小视野来聚焦于边界框所在的区域,并调整回原始图像的大小,得到连续的 16 帧图像用于模拟智能体向边界框所示区域移动时的视觉变化。
随后,我们使用预训练的 MineCLIP 模型来评估模拟探索视频和任务文本描述之间的相关性,以此作为该区域的潜在探索价值。当滑动边界框扫描完整个图像后,我们融合所有边界框位置的相关性值,从而生成一张完整的功用性图,为智能体的探索提供指导。
2.2 快速功用性图生成
上述步骤 1 中的功用性图计算过程涉及广泛的窗口遍历,并对每个窗口位置使用预训练的视频-文本对齐模型进行计算。这种方法计算量大、时间开销高,使其难以应用于实时任务。
为此,我们设计了一套基于 Swin-Unet 的多模态 U-Net 架构,并通过上述的基于虚拟探索的功用性图计算方法来标注数据作为监督信号,训练该多模态 U-Net 架构,使其可以如图 3 所示在每个时间步利用视觉观察与语言指令,高效地生成功用性图。
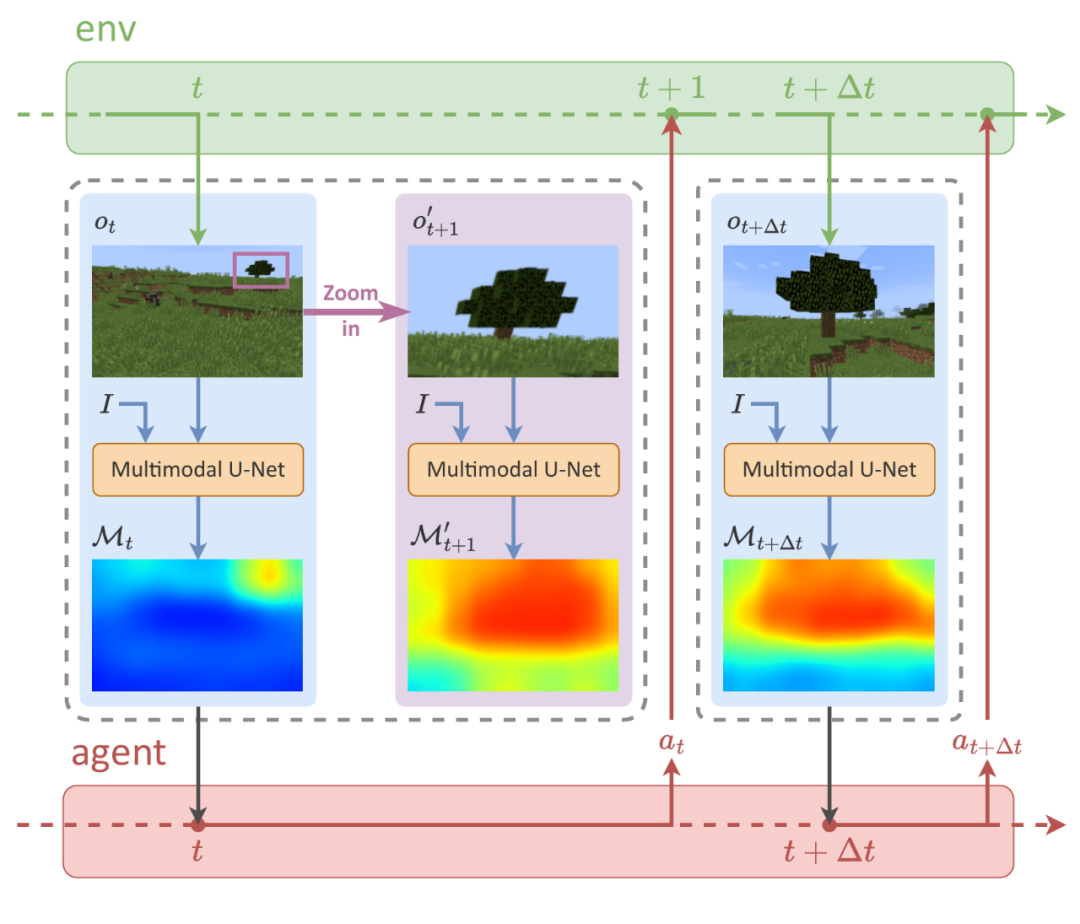
▲ 图3:利用多模态 U-Net 高效生成功用性图
2.3 根据功用性图计算内在奖励以及评估跳跃式状态转换的必要性
如图 4 所示,为了利用功用性图所提供的任务相关先验知识,我们计算功用性图与同尺寸的二维高斯矩阵逐元素相乘的均值,并将其作为功用性驱动的内在奖励(affordance-driven intrinsic reward)。该奖励能激励智能体不断靠近目标并将目标对齐在视角中心。
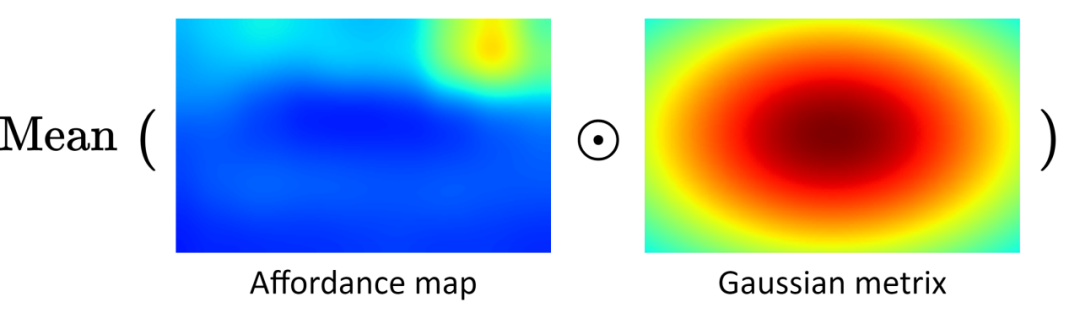
▲ 图4:功用性驱动的内在奖励计算方法
此外,为了评估想象过程中跳跃式转换的必要性,我们引入了一个跳跃标志(jumping flag)。
如图 5 所示,当智能体的观察中出现远距离的任务相关目标时,会在功用性图上体现为高价值区域高度集中,这也会导致功用性图的峰度(kurtosis)显著升高。在这种情况下,智能体应采用跳跃式状态转换(也称作长期转换),以高效抵达目标区域。
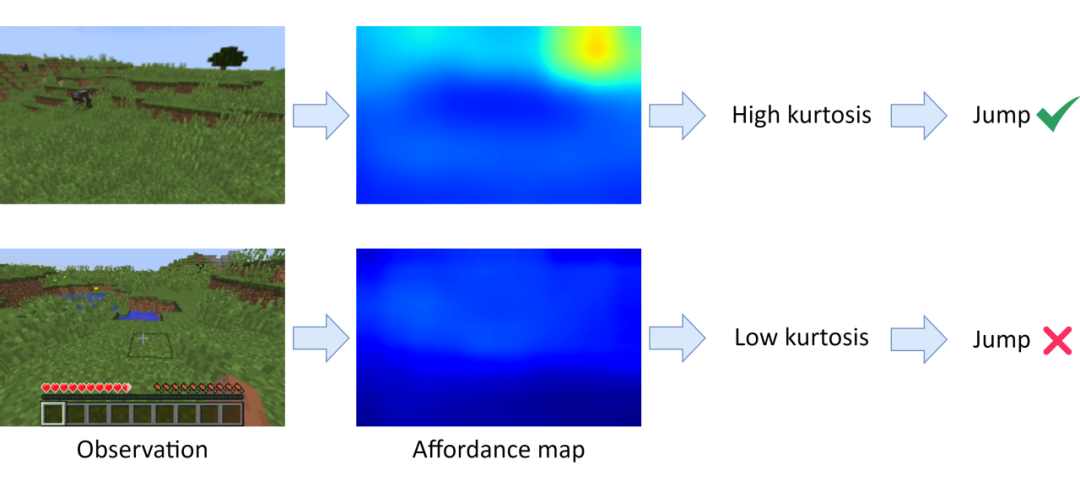
▲ 图5:跳跃式状态转换必要性评估
2.4 长短期世界模型
在 LS-Imagine 中,世界模型需要能够同时支持即时状态转换(短期状态转换)和跳跃式状态转换(长期状态转换)。所以,如图 6(a)所示,我们在状态转换模型中设计了短期和长期两个分支,短期状态转换模型将结合当前时刻的状态和动作来执行单步的即时状态转换以预测下一相邻时间步的状态。
长期转换模型则模拟目标导向的跳跃式状态转换,引导智能体快速想象向目标探索。智能体可以根据当前的状态决定采用哪种类型的转换,并通过所选的转换分支预测下一状态。
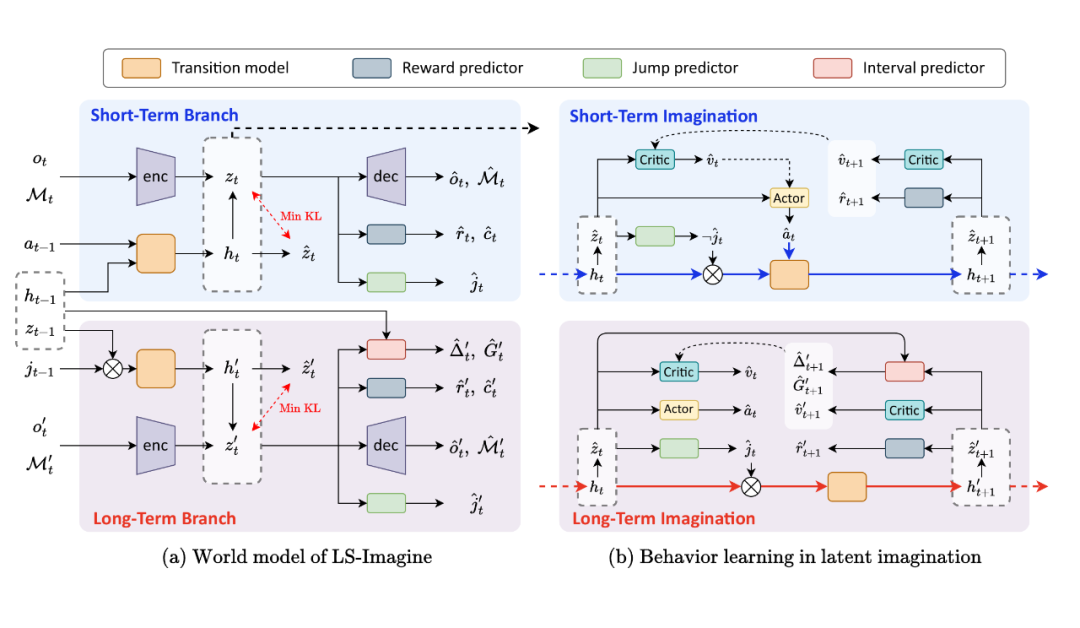
▲ 图6:长短期世界模型架构以及基于长短期想象的行为学习
区别于传统的世界模型架构,我们特别设计了跳跃预测器(Jump predictor)以根据当前的状态判断应该执行哪种类型的转换。
同时,对于跳跃式的状态转换,我们设计了间隔预测器(Interval predictor)以估计跳转前后的状态所间隔的环境时间步数 以及期间的累积折扣奖励 ,它们将用于在后续的行为学习中估计长期回报。
此外,我们还将功用性图 作为编码器(encoder)的输入,它可以为智能体提供基于目标的先验引导,以提升决策过程的有效性。
在此架构基础上,智能体与环境交互并收集新数据,得到对应于短期状态转换的相邻时间步长的样本对,并根据功用性图建模出对应于长期状态转移的跨越较长时间间隔的样本对。我们将使用这些数据来更新重放缓冲区(replay buffer)并从中采样数据对长短期世界模型进行训练。
2.5 在长短期想象序列上进行行为学习
如图 6(b)所示,LS-Imagine 采用演员-评论家(actor-critic)算法,通过世界模型预测的潜在状态序列来学习行为。其中,演员(actor)的目标是优化策略,以最大化折扣累积奖励 ,而评论家(critic)的作用则是基于当前策略估算每个状态的折扣累积奖励。

▲ 图7:动态选择使用长期转移模型或短期转移模型预测长短期想象序列
如图 7 所示,从采样的观测和功用性图编码的初始状态出发,我们根据跳跃预测器预测的跳跃标志 动态选择使用长期或短期的状态转换模型,以预测后续状态。
在具有想象范围 的长短期想象序列中,我们通过世界模型中的各类预测器预测状态对应的奖励 、继续标志 ,以及相邻状态所间隔的环境时间步数 以及期间的累积折扣奖励 等信息,并采用改进的 bootstrap -returns 结合长期与短期想象以计算每个状态的折扣累积奖励:
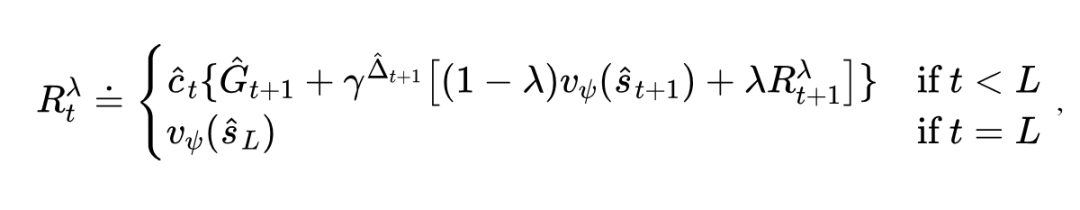
并采用演员-评论家算法进行行为学习。

实验结果
我们在 Minecraft 游戏环境中进行实验来测试 LS-Imagine 智能体。我们设置了如表 1 所示的 5 个开放式任务来进行实验:

▲ 表1:Minecraft 任务描述
我们将 LS-Imagine 和 VPT、STEVE-1、PTGM、Director、DreamerV3 等多种方法进行了比对,评估的指标包括在指定步数内完成任务的成功率以及平均完成任务所需要的交互步数。实验的结果如图 8、图 9 和表 2 所示。
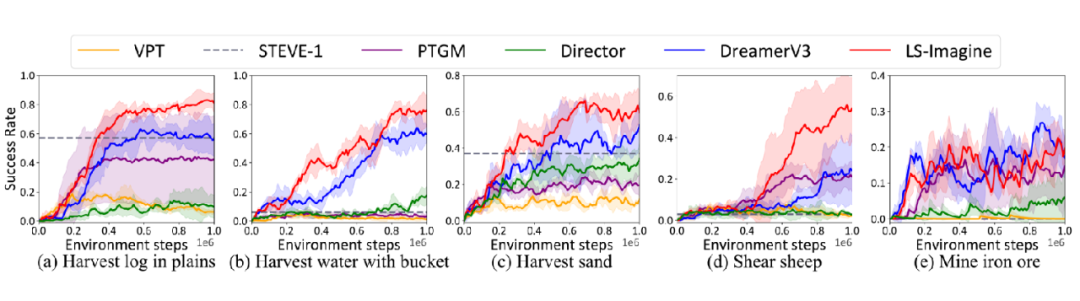
▲ 图8:各项任务上成功率的对比
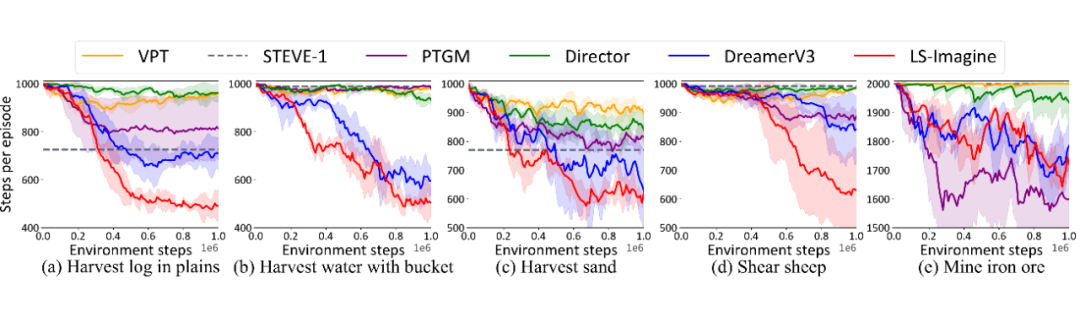
▲ 图9:完成各项任务所需交互步数的对比
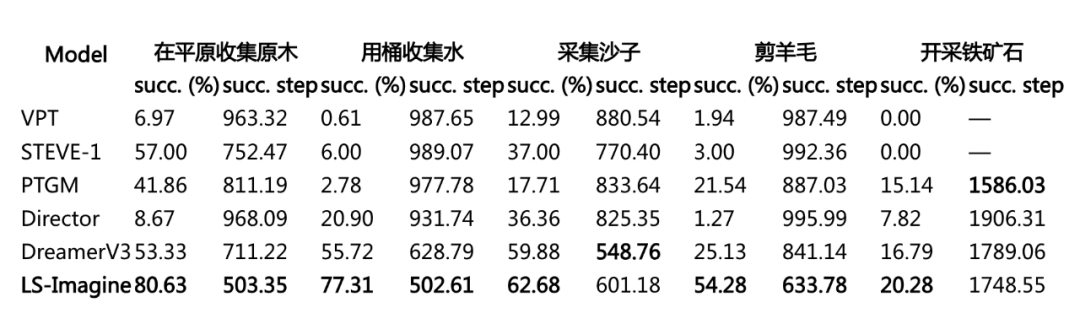
▲ 表2:成功率和完成任务所需交互步数的数值结果
我们发现,LS-Imagine 在对比模型中表现显著优越,尤其是在目标稀疏分布的任务场景下,其优势更加明显。
同时,我们在图 10 中展示了基于长短期想象状态序列重建的观测图像和功用性图的可视化结果。
其中第一行显示了跳跃式状态转换前后的潜在状态,并将其解码回像素空间,以直观呈现状态变化;
第二行可视化了由潜在状态重建的功用性图,以更清晰地理解功用性图如何促进跳跃式状态转换,以及它们是否能够提供有效的目标导向指导;
最后一行通过透明叠加的方式将功用性图覆盖在重建的观测图像上,从而更直观的凸显出智能体关注的区域。
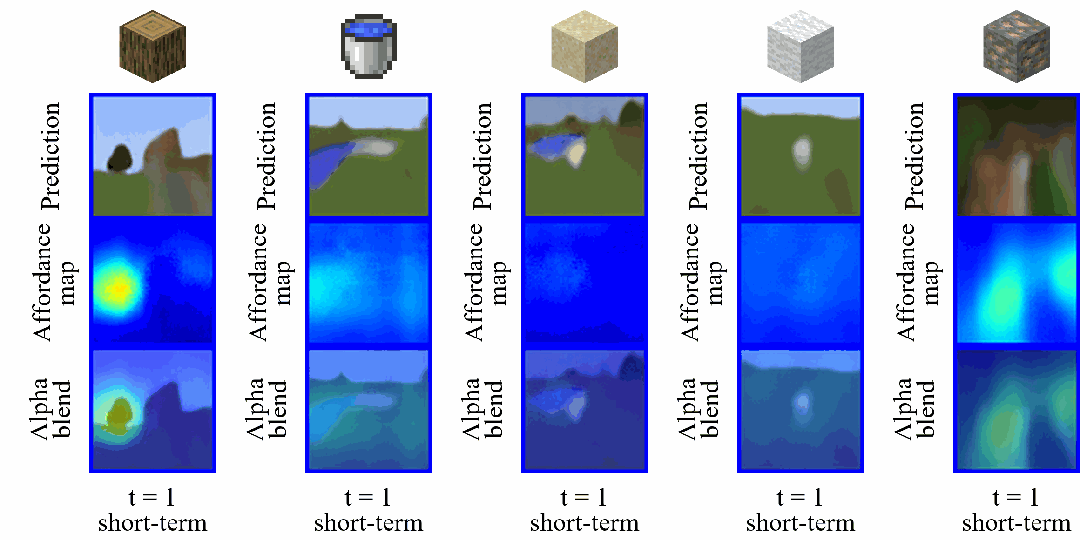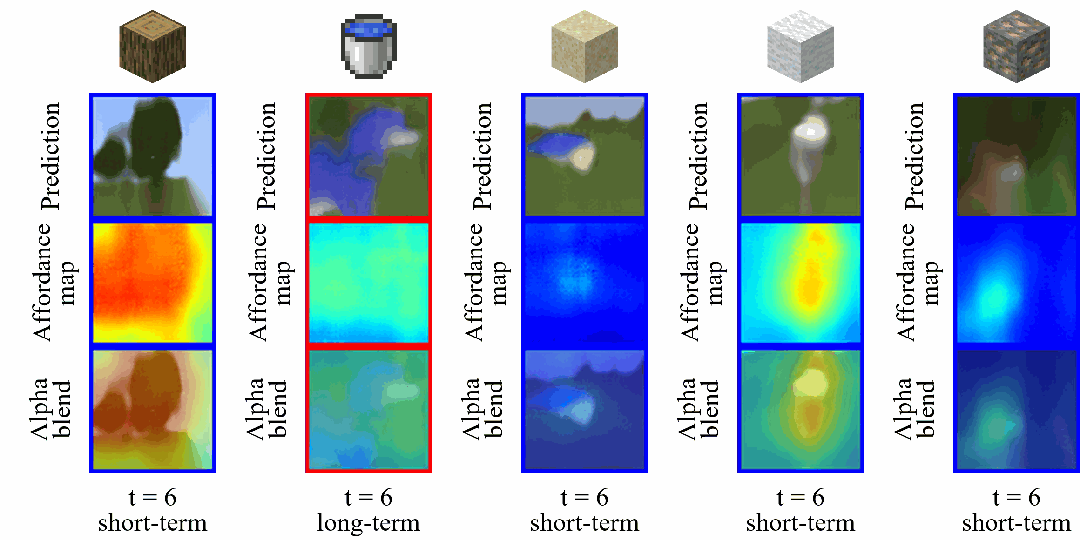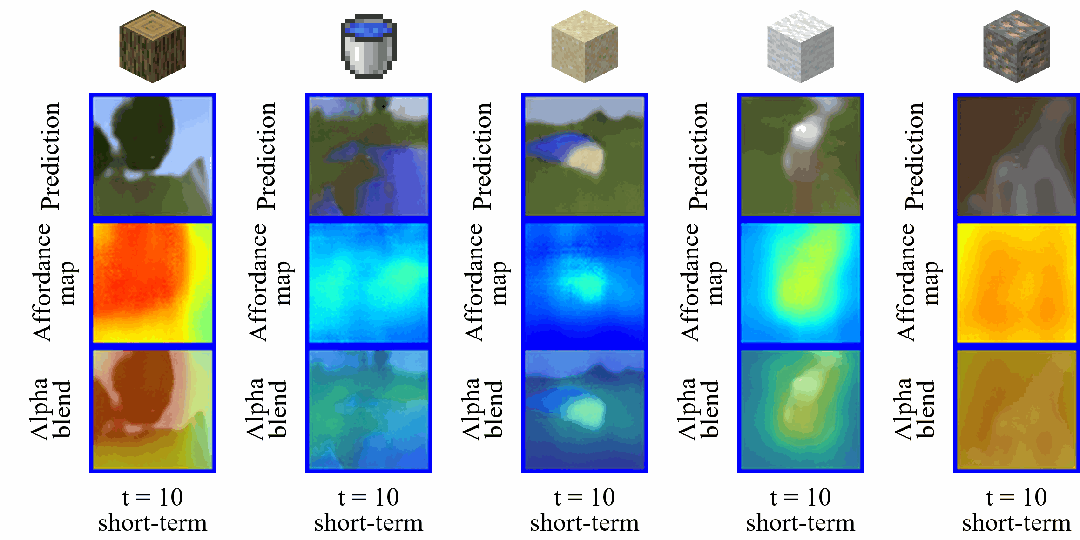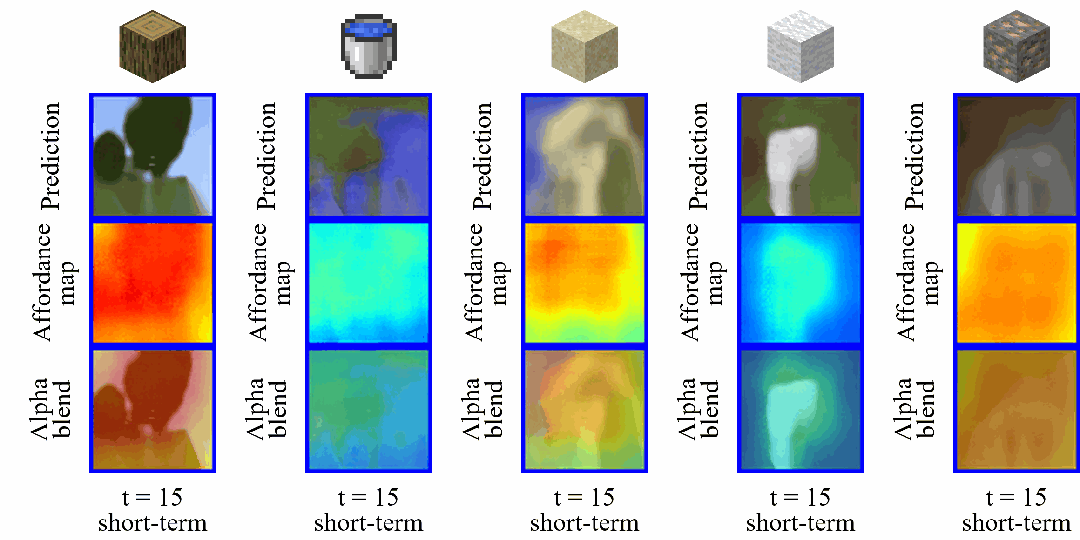
▲ 图10:长短期想象序列可视化
这些可视化结果表明,LS-Imagine 的长短期世界模型能够根据当前视觉观测自适应地决定何时进行长期想象。此外,生成的功用性图能够有效对齐与最终目标高度相关的区域,从而促进智能体执行更高效的策略探索。
此外,鉴于我们的方法依赖功用性图来识别高价值的探索区域,从而实现长期状态跳跃,有人可能会认为,如果目标被遮挡或不可见,我们的方法将失效。为了证明我们的功用性图生成方法并不仅仅是一个目标识别算法,并不会仅在目标可见时才高亮相关区域,我们在图 11 中展示了当目标被遮挡或不可见的情况下生成的功用性图的例子。

▲ 图11:目标被遮挡或不可见情形下的功用性图
得益于 MineCLIP 模型在大量专家示范视频上的预训练,我们的功用性图生成方法能够在即使目标完全被遮挡或不可见的情况下生成为探索提供有效指导的功用性图。例如,如图 11(a)所示,在寻找村庄的任务中,尽管村庄在当前观测中不可见,功用性图依然能够提供清晰的探索方向,建议智能体向右侧的森林或左侧山坡的开阔区域进行探索。
类似地,在图 11(b)所示的挖矿任务中,尽管矿石通常位于地下,在当前观测中被遮挡,功用性图仍然能指引智能体向右侧的山体内部或前方的地面下挖掘。这些例子能够充分证明,即便目标被遮挡,功用性图依然可以帮助智能体有效地进行探索。

总结
我们的工作提出了一种新颖的方法——LS-Imagine,旨在克服在高维开放世界中训练视觉强化学习智能体所面临的挑战。通过扩展想象范围并利用长短期世界模型,LS-Imagine 能够在庞大的状态空间中高效进行策略探索。
此外,引入基于目标的跳跃式状态转换和功用性图,使得智能体能够更好地理解长期价值,从而提升其决策能力。
实验结果表明,在 Minecraft 环境中,LS-Imagine 相比现有的方法取得了显著性能提升。这不仅凸显了 LS-Imagine 在开放世界强化学习中的潜力,同时也为该领域的未来研究提供了新的启发。
论文的代码、checkpoint、环境配置文档均有提供,欢迎大家 GitHub star、引用。
(文:PaperWeekly)