

这是一篇让 LLM 从“单打独斗”进化成“团队作战”的神奇论文!现在的LLM虽然能写诗、编代码,但遇到需要深度推理的问题时,常常像极了熬夜赶论文的我们——脑子一片浆糊,只会疯狂挠头。这篇论文给LLM配了三个“外挂小秘书”:
-
网瘾少年搜索助手:随时帮LLM上网冲浪查资料; -
码农代码助手:替LLM写代码跑程序,省得它自己debug到崩溃; -
思维导图管家:把推理过程整理成知识图谱,防止LLM“逻辑迷路”。
从此,LLM的推理能力直接开挂,博士级难题也能轻松拿捏!
 论文:Agentic Reasoning: Reasoning LLMs with Tools for the Deep Research
论文:Agentic Reasoning: Reasoning LLMs with Tools for the Deep Research
链接:https://arxiv.org/pdf/2502.04644
项目:https://github.com/theworldofagents/Agentic-Reasoning
方法
整个框架就像给LLM配了一个“复仇者联盟”:
-
搜索助手:LLM一发出🔍信号,立马谷歌学术+维基百科狂搜,还自带总结功能,只喂给LLM最相关的“知识零食”; -
代码助手:LLM喊一声💻,它就秒写Python代码并运行,结果用大白话返回,避免LLM被代码语法逼疯; -
思维导图管家:把推理过程画成超酷的知识图谱,还能自动分模块、做摘要,堪比AI版“思维导图APP”。
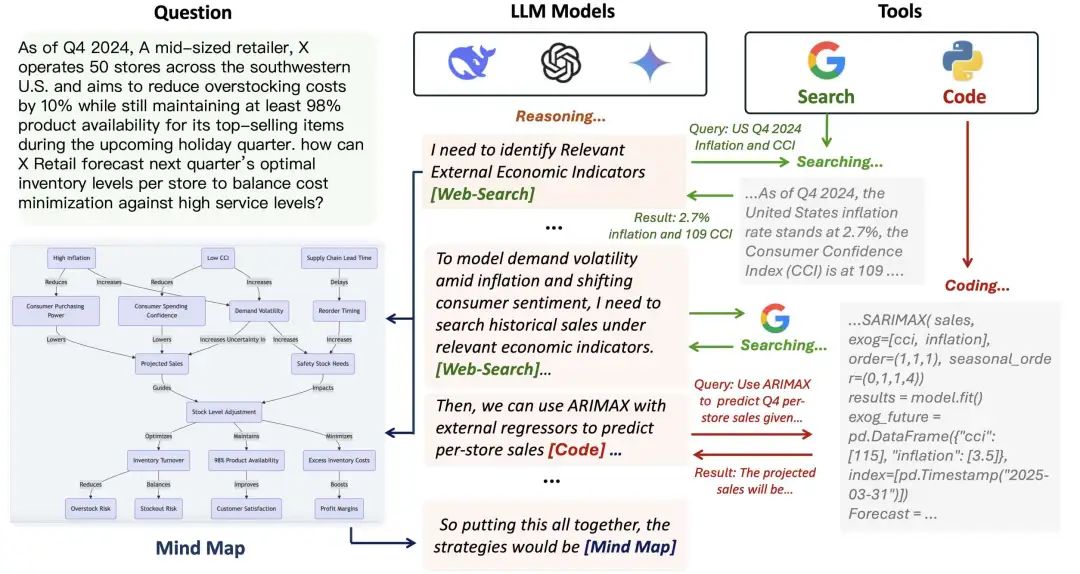
最萌的是,LLM推理时会主动“举手提问”🙋!比如需要数据就插个🔍标记,需要计算就塞个💻符号,活像课堂上憋不住问题的小学生~
实验
为了验证这波操作有多强,作者们搞了一堆硬核测试
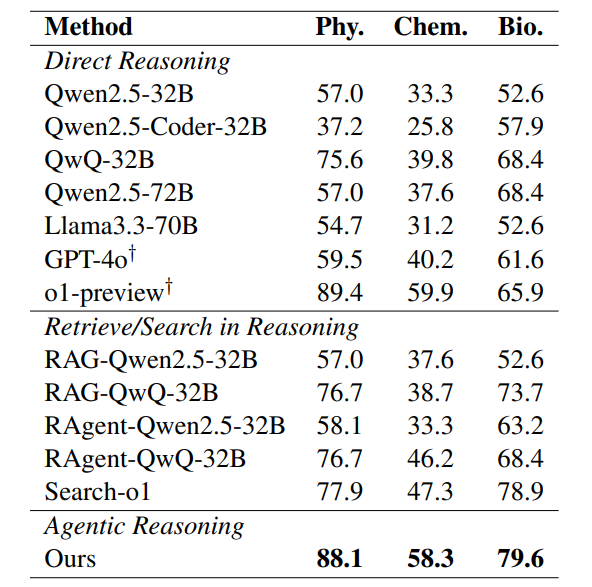
博士级考试暴击
用GPQA数据集(物理/化学/生物博士级选择题)狂虐模型,结果:
-
Agentic Reasoning在物理题拿下88.1%正确率,化学58.3%,生物79.6%,直接把其他模型按在地上摩擦!
医学诊断实战
让模型处理“计算最佳氧气浓度”的医疗决策,它居然能:
-
召唤代码助手算FiO₂; -
派搜索助手查PEEP值; -
综合结果给出治疗方案——AI医生执照指日可待!

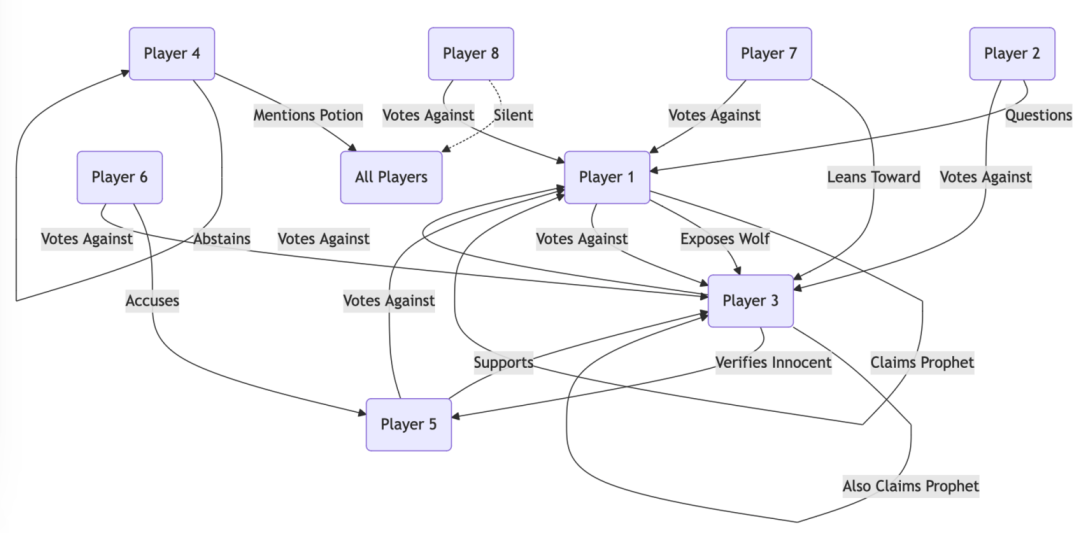
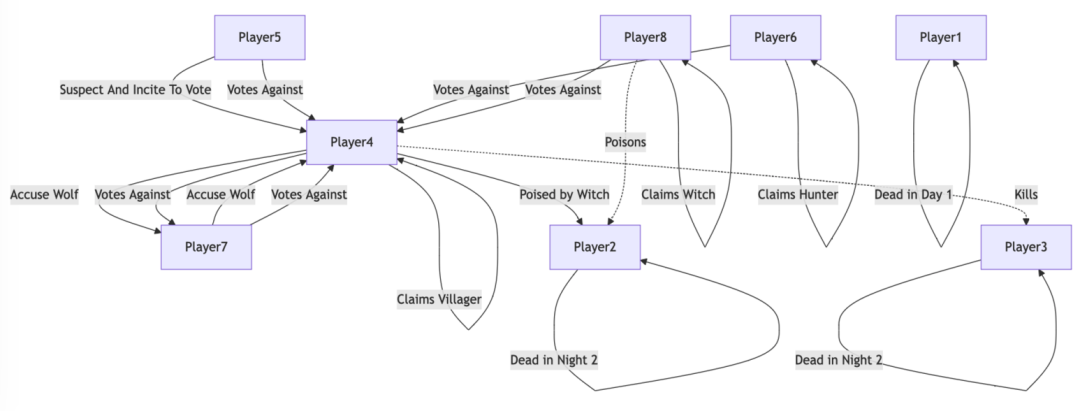
狼人杀智商碾压
最搞笑的是,作者让模型玩狼人杀!通过思维导图记录玩家发言的逻辑关系,最终胜率72%,吊打人类老玩家。
人类专家惨遭KO
在GPQA扩展集上,模型在物理(75.2%)、化学(53.1%)、生物(72.8%)全面超越人类专家,物理学家们看完直呼“AI抢饭碗啦!”
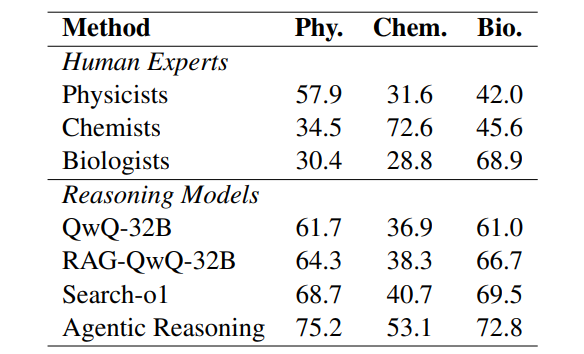 人类vs模型战绩表
人类vs模型战绩表结论
这篇论文的核心就一句话:“三个臭皮匠,顶个诸葛亮”!给LLM配上一群专业小助手,让它从“死记硬背”进化成“逻辑狂魔”。实验结果证明,这套框架不仅能搞定博士级考题,还能玩转狼人杀、写深度报告,甚至让人类专家瑟瑟发抖~
未来,这个思路还能用来训练更聪明的LLM——想象一下,AI带着搜索+代码+思维导图全家桶,直接变身科研超人!
(文:机器学习算法与自然语言处理)