

极市导读
离散值空间分布对于自回归建模不是必需的。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 MAR:不使用 Vector Quantization 的自回归图像生成
(来自 MIT,Kaiming 团队)
1.1 MAR 的诞生背景
1.2 MAR 做法
1.3 重新思考 Discrete-Valued token
1.4 Loss Function:Diffusion Loss
1.5 采样器:反向扩散过程
1.6 自回归模型使用 Diffusion Loss
1.7 统一自回归和 Masked Generative Models
1.8 MAR 实现结果
太长不看版
传统观点认为,用于图像生成的自回归模型 (Autoregressive model) 通常使用矢量量化 (Vector-quantized) 的 token。MAR 观察到这个观点站不住脚,即:离散值空间分布对于自回归建模不是必需的。
在 MAR 这项工作中,作者提出使用扩散过程对每个 token 的概率分布进行建模,这使 MAR 能够在连续值空间中应用自回归模型。
MAR 定义了一个 Diffusion Loss 函数来模拟每个 token 的概率,而不是使用分类 Cross-entropy 损失。这种方法消除了对 discrete-valued tokenizers 的需求。
通过去除矢量量化,图像生成器在享受自回归模型的序列建模速度优势的同时取得了很好的结果。
1 MAR:不使用 Vector Quantization 的自回归图像生成
论文名称:Autoregressive Image Generation without Vector Quantization (NeurIPS 2024)
论文地址:
http://arxiv.org/pdf/2406.11838
代码链接:
http://github.com/LTH14/mar
1.1 MAR 的诞生背景
自回归模型 (Autoregressive model) 是目前生成模型常用的解决方案。这些模型根据前面的单词作为输入来预测序列中的下一个 token。鉴于语言的离散性质,这些模型的输入和输出都是离散的。这种流行的方法带来了人们传统的认知,即自回归模型本质上与离散表征相关联。
因此,将自回归模型推广到连续值域 (比如图像生成领域) 的研究,主要集中在对数据进行离散化。一种常用的策略是对图像训练一个 discrete-valued tokenizer,通过 Vector Quantization (VQ)[1]获得的有限词汇表。然后将自回归模型操作在 discrete-valued token 空间上,类似于语言。
这个工作的目标是解决以下问题:自回归模型是否需要与 Vector Quantization 的表征相结合。作者注意到:自回归性质,即 “predicting next tokens based on previous ones”,与值是离散的还是连续的无关。自回归性质真正需要的是:对每个 token 的概率分布进行建模。
如果值是离散的,那么可以很方便地使用一个分类 Loss 建模,但并不是必须的。如果有其他方式可以求得每个 token 的概率分布,那就可以在没有 Vector Quantization 的情况下处理自回归模型。
基于这个观察,本文提出了一种对每个 token 的概率分布进行建模的方式:在连续值域上操作的扩散过程。
1.2 MAR 做法
MAR 采用如下做法在连续值域上对 每个 token 的概率分布 进行建模。
MAR 利用扩散模型原理来表示任意概率分布。具体而言,MAR 自回归预测每个标记的向量 作为去噪扩散模型(例如,一个小的 MLP)的 Condition。去噪扩散过程使我们能够表示输出 的底层分布 ,如图 1 所示。小的扩散模型随着自回归模型一起训练,以连续值 token 作为输入和目标。
从概念上讲,这个应用于每个 token 的小预测头的行为类似于测量 质量的损失函数。作者将此损失函数称为 Diffusion Loss。
MAR 消除了对 discrete-valued tokenizers 的需求。Vector-quantized tokenizer 很难训练,并且对梯度逼近策略敏感。与连续值模型相比,重建质量往往较差。MAR 允许自回归模型享有高质量,无需量化的 tokenizer。
MAR 揭示了图像生成的一个很大程度上未知的领域:通过自回归建模 token 之间的相互依赖性,通过扩散建模 每个 token 的分布。这与典型的 latent diffusion model 不同,后者使用扩散过程建模所有 token 的联合分布。

1.3 重新思考 Discrete-Valued token
假设 是要在下一个位置预测的真实 token。使用 Discrete-Valued tokenizer, 可以表示为整数: ,假设词汇表大小为 。自回归模型产生连续值 维度的向量 ,然后由 分类器矩阵 投影。使用 对分类概率分布进行建模。
在生成式建模的背景下,这个概率分布必须表现出 2 个基本属性:
-
一个 Loss Function,可以测量估计分布和真实分布之间的差异。在离散值的情况下,可以简单地通过 Cross-entropy Loss 完成。 -
一个采样器,可以在推理时从分布 中抽取样本。在离散值的情况下,通常被实现为从 中抽取样本,其中 是控制样本多样性的温度。
从这个分析不难看出,对于自回归模型而言,discrete-valued token 并非必须的。必须的是去挨个建模 token 的分布。
在离散值的情况下,token 的分布容易建模,因为 GT 都是确定的,所以可以使用分类损失 CE Loss;
在连续值的情况下,GT 也是连续的值,因此 token 的分布不容易建模,因此本文提出使用 Diffusion Loss 来建模。在这种情况下,亦需要确定 Loss Function 和采样器。
1.4 Loss Function:Diffusion Loss
根据以上分析,任务变成了在连续值的情况下去挨个建模 token 的分布。
Diffusion Model 是建模任意分布的有效框架。但是 Diffusion Model 是同时建模所有 token 的联合分布,在本文中,Diffusion Loss 用于建模每个 token 的分布。
考虑一个连续值向量 ,它表示要在下一个位置预测的 GT token。自回归模型在此位置生成一个向量 。现在,目标是对以 为 condition,对 的概率分布进行建模,即 。损失函数和采样器可以按照扩散模型定义:

其中, 是从 中采样的噪声向量。 ,其中 是 noise schedule。噪声估计器 是一个小型 MLP 网络,以 为输入, 和 为条件。从概念上讲,式 1 表现为分数匹配的一种形式。Diffusion Loss 是参数化损失函数的一种形式,与 adversarial loss 或 perceptual loss 相似。
注意到数学期望 是与 相关的,由于去噪网络很小,可以对任何给定 进行多次采样。这有助于提高损失函数的利用率,无需重新计算 z 。作者在每个图像的训练期间将 采样 4 次。
1.5 采样器:反向扩散过程
推理时,需要从分布 中抽取样本。抽样是通过反向扩散过程完成的:

式中, 是从高斯分布 中采样的, 是时间步 的噪声 level。从 开始,这个过程产生一个样本 ,使得 。
现有的工作,无论是在语言还是图像中,都表明 temperature 在自回归生成中起着至关重要的作用。从概念上讲,当 temperature 为 时,相当于是从 中采样,score function 就变成了 。在实践中,[2]建议将 除以 ,或者将噪声缩放 。本文采用后一种选择,在采样器中将 缩放 。直观地说, 通过调整噪声方差来控制样本的多样性。

1.6 自回归模型使用 Diffusion Loss
给定 token 序列 ,自回归模型将生成问题表述为 “next token prediction”:
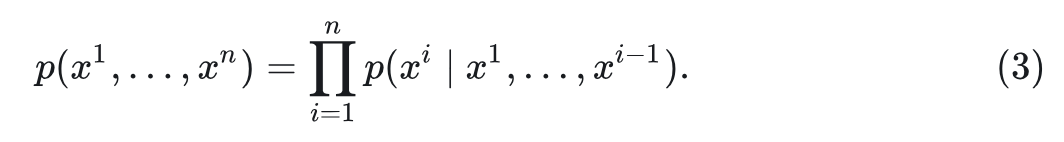
其中, 表示连续的值。首先使用自回归模型生成: ,然后使用扩散模型建模下一个 token: 。梯度反向传播到 以更新 的参数。
1.7 统一自回归和 Masked Generative Model
本文表明 MaskGIT[3]和 MAGE[4]这类 Masked Generative Model 可以泛化为广义的自回归模型,即 next token prediction。
自回归的概念与网络架构正交:自回归可以由 RNN、CNN 和 Transformers 完成。自回归的目标是在给定前一个 token 的情况下预测下一个 token;它不限制前一个 token 如何与下一个 token 通信。

Causal attention 限制每个 token 只关注先前的 token。输入移位一个 start token [s],训练时计算所有 token 的 loss。Bidirectional attention 允许每个 token 看到序列中的所有 tokens,mask token [m] 应用于中间层,添加了位置编码。训练时仅仅计算未知 token 的 loss。Bidirectional attention 在推理时可以自回归方式 one-by-one 地生成 token,也可以同时预测多个 tokens。
作者允许所有已知的 token 相互查看,所有未知 tokens 查看所有已知的 tokens。这样的 attention 模式比 causal attention 更好交流 token 的关系。在推理时,一步生成一个或多个 token,这也可以视为是一种自回归。但是,缺点是不能使用 causal attention 的 KV cache 来加速推理。但是由于可以一次生成多个 token,因此可以减少生成步骤以加快推理速度。这样可以显著提升质量并提供更好的速度-精度权衡。
为了把自回归模型和 Masked Generative Model 联系在一起,作者考虑了随即顺序的自回归模型,如下图 4(b) 所示。在这种情况下,需要告诉模型下一个要预测的 token 的位置。采用类似于 MAE 策略:将位置编码 (对应于未打乱的位置) 添加到 Decoder 层,这可以判断要预测的位置。该策略适用于因果版本和双向版本。如图 4(b)(c) 所示,随机顺序自回归的行为类似于一种特殊的 masked generation 形式,一次生成一个 token。

在 masked generative modeling 中,模型根据已知的 token 预测随机子集的 token。这可以表述为按随机顺序排列标记序列,然后根据先前的 token 预测多个 token,如图 4(c) 所示。
从概念上讲,这是一个自回归过程,可以写成估计条件分布: ,其中要预测多个 token 。可以将这个自回归模型写为:

这里, 是第 步要预测的 token 的集合,有 。
从这个意义上说,masked generative modeling 本质上是 “next set-of-tokens prediction”,因此也是自回归的一般形式。作者将此变体称为掩码自回归 (MAR) 模型。MAR 是一个 Random-order 自回归模型,可以同时预测多个 tokens。
1.8 MAR 实现结果
Diffusion 过程遵循 IDDPM[5],去噪网络预测噪声向量 。损失可以可选地包括变分下限项 。扩散损失自然支持 Classifier-free Guidance (CFG)。
扩散模型是一个小 MLP,3层,1024 channel,每层包括 LayerNorm (LN),一个线性层,SiLU 以及另一个线性层。AR/MAR 模型的输出向量 加到 time embedding 中,用作 MLP 的 condition。
Tokenizer 使用 LDM 中的 tokenizer,分为 VQ-16 和 KL-16 2 个版本,16 代表下采样 16 倍。Transformer 有 32 个 Block,宽度为 1024。
作者在 ImageNet 256×256 上进行了实验。
下图 5 比较了使用 Diffusion Loss 的连续值 token 和 Cross-entropy Loss 的离散值 token 的比较结果。具有连续值 token 的 Diffusion Loss 在所有实验中都优于具有离散 token 的 Cross-entropy Loss。

Diffusion Loss 的一个重要优势是它与各种 tokenizer 的灵活性。图 6 比较了几个公开可用的 tokenizer。

图 7 研究了去噪 MLP。即使是非常小的 MLP (2M) 也可能得到很有竞争力的结果。如预期的,增加 MLP 宽度有助于提高生成质量。增加深度有相似的观察结果。

图 8 研究了 Sampling steps。扩散过程遵循 DDPM 的常见做法:使用 1000-step noise schedule 进行训练,但使用更少的步骤进行推理。图 8 显示,在推理时使用 100 个 diffusion steps 足以实现强大的生成质量。

图 9 研究了 Temperature 参数。温度 对 FID (左) 和 IS (右) 都有明显的影响。
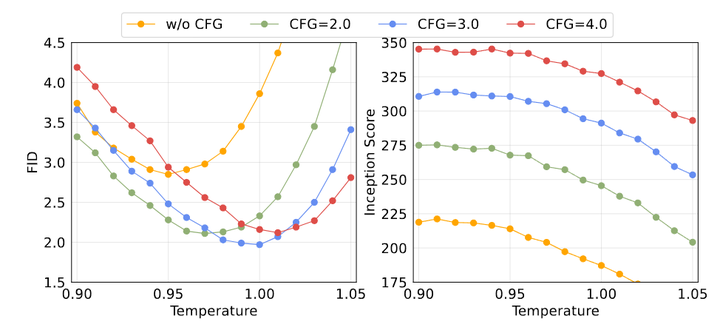
图 10 展示了 MAR 的 Speed-Acuracy trade-off。MAR 具有一次预测多个 token 的灵活性。这在推理时由自回归步骤的数量控制。MAR 比 AR 的 Speed-Acuracy trade-off,注意 AR 具有高效的 KV-cache。DiT 的 Speed-Acuracy trade-off 主要由其扩散步骤控制。与 MAR 的小 MLP 上的扩散过程不同,DiT 的扩散过程涉及整个 Transformer。MAR 更准确、更快。

图 11 是系统级别的比较。包含各种模型大小,训练 800 个 epoch。与自回归语言模型类似,可以观察到缩放行为。关于指标,作者报告了无 CFG 的 2.35 FID,大大优于其他基于 token 的方法。最好的结果有 1.55 FID,并且与其他模型相比具有优势。

参考
-
^Neural Discrete Representation Learning -
^Diffusion Models Beat GANs on Image Synthesis -
^MaskGIT: Masked Generative Image Transformer -
^MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis -
^Improved Denoising Diffusion Probabilistic Models
(文:极市干货)