


极市导读
从 Agent 前沿研究中一窥复制 Manus 的启示。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Manus 的出现将智能体推入当下 AI 格局的前列,使得这个过去略抽象的概念变得具体可感知。然而行业中也不乏对 Manus 的争议,认为 Manus 没有底层技术创新力,更多的是将现有技术融合从而在工程上创新,即所谓的“套壳”。
虽说工程创新也是一种护城河,但“套壳”的说法也并非完全没道理。近几年的时间里,学界和业界关于 Agent 的技术和实践成果颇丰。在 AI 智能体推理与决策研讨会(AIR 2025)上,来自伦敦大学学院、新加坡南洋理工大学、Weco AI、Google DeepMind、Meta、华为、阿里等多位学术界和工业界的研究人员围绕强化学习、推理决策、AI 智能体展开讨论。
新加坡南洋理工大学的安波教授揭示了从基于强化学习的智能体到由大型语言模型驱动的智能体的演变,分享了团队多项关于 Agent 的工作进展,其中 Q* 算法以多步骤推理作为审慎规划,在学习 Q 值模型的过程中,需要经历离线强化学习以交替更新 Q 值标签并拟合 QVM、使用表现最佳的回滚轨迹的奖励、使用与更强大 LLM 一起完成的轨迹的奖励三个关键步骤。
初创公司 Weco Al 的 CTO Yuxiang 阐述了在解空间中寻找智能的一些时间,介绍了由人工智能驱动的 Agent—— AIDE,能够处理完整的机器和工程任务。如果将机器学习和工程视为一个代码优化问题,那么它就会将整个搜索或代码优化的过程形式化为在解空间中的树搜索。在这个被形式化的解空间中,AIDE 是一个任何大语言模型都可以编写的代码空间。
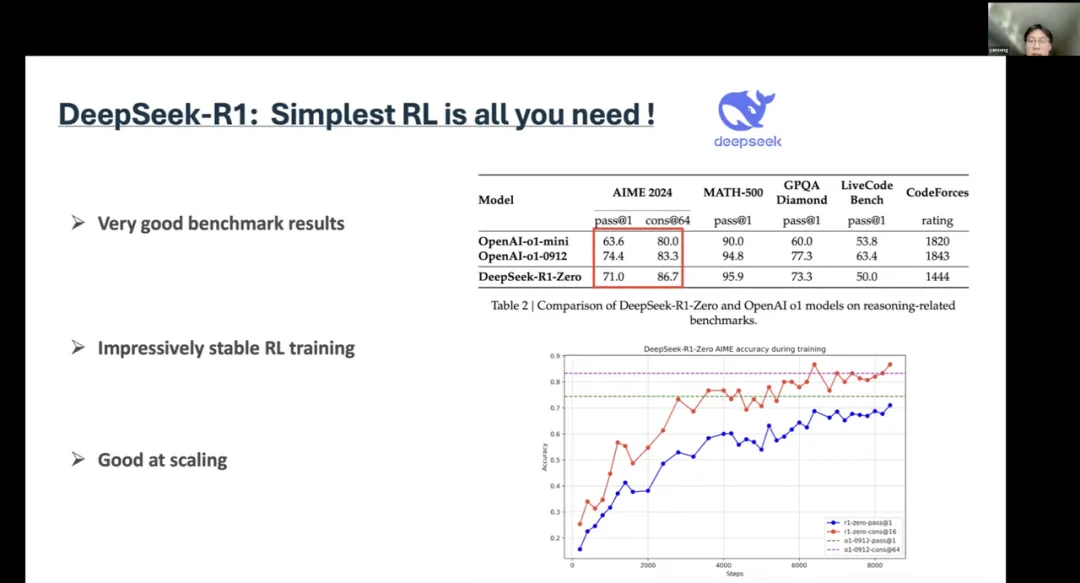
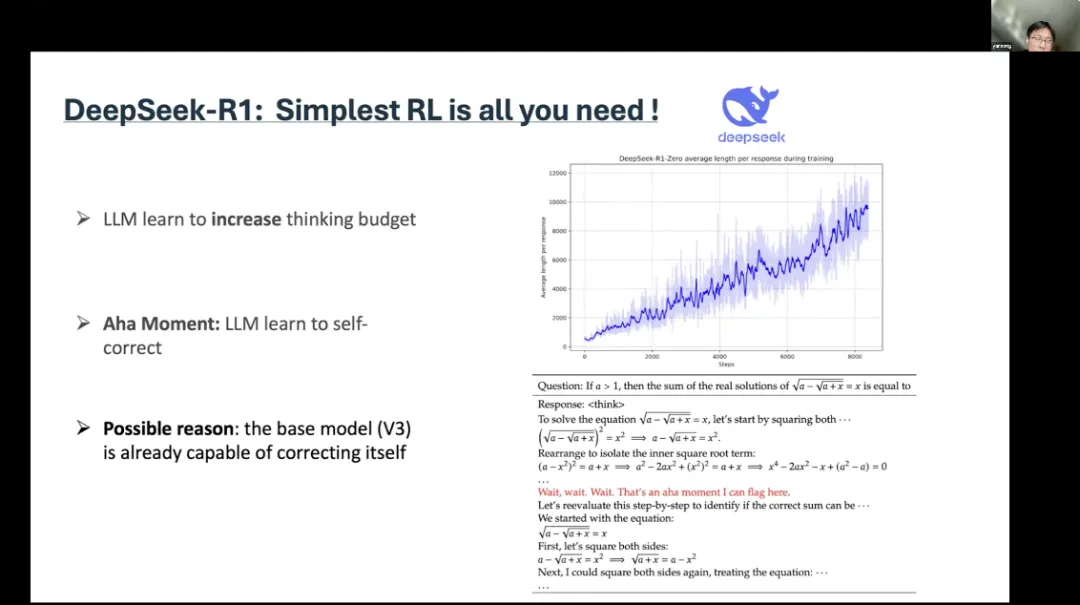
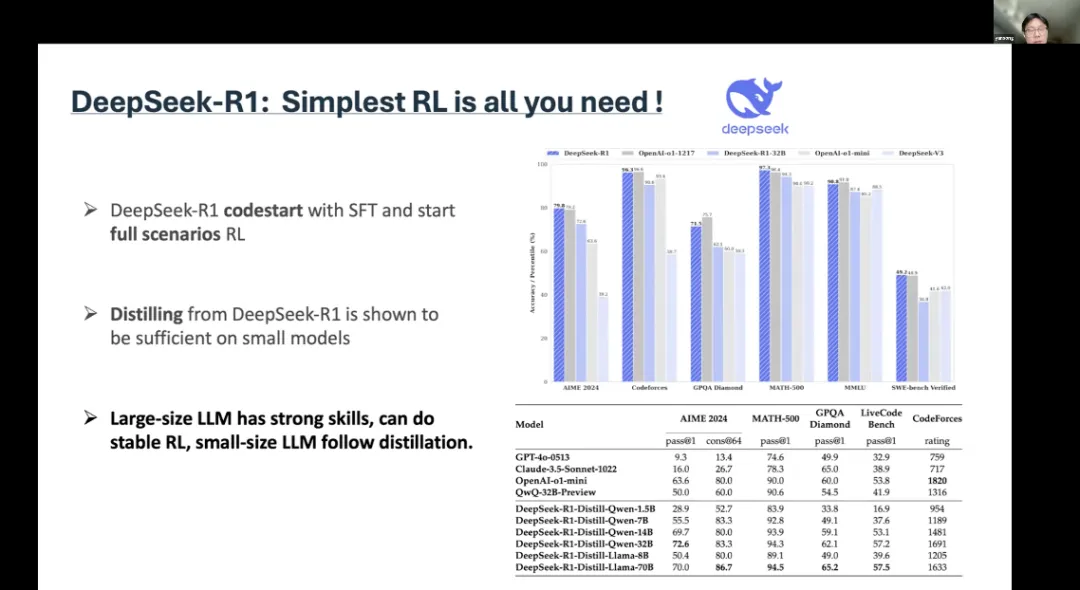
来自伦敦大学学院的宋研从 DeepSeek 切入,讨论了强化学习在大型语言模型推理中的作用,并指出 DS 又一个“Aha时刻”,即在强化学习阶段,大型语言模型学会了自我纠正,这可能是由于其基础模型已经具备自我纠正的能力。基于此进一步发现,当 Agent 使用某些关键词时,它们会进行各种回溯、自我报告和复杂推理。
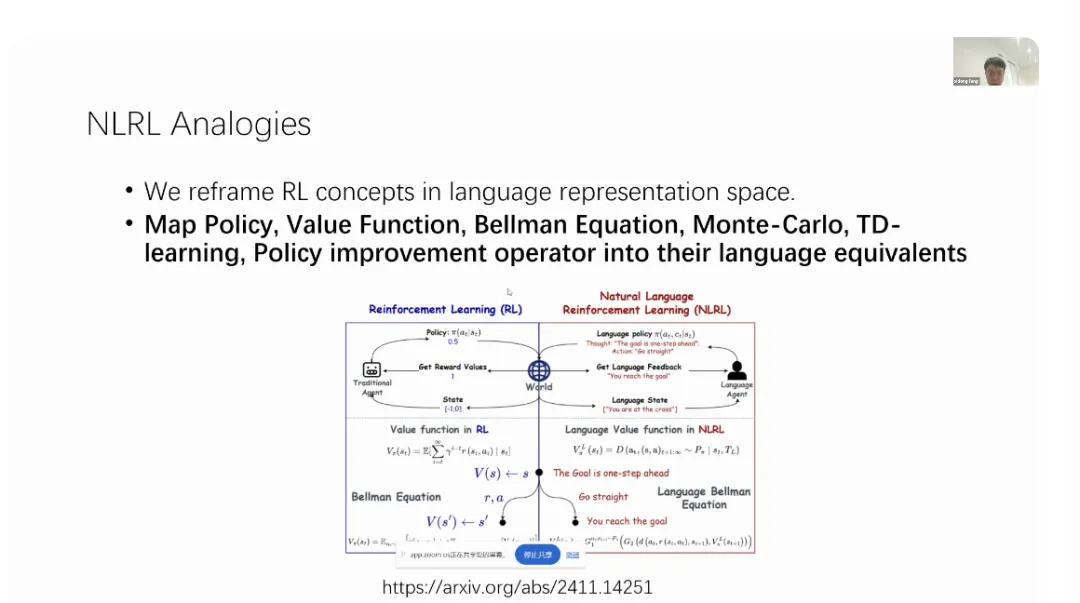
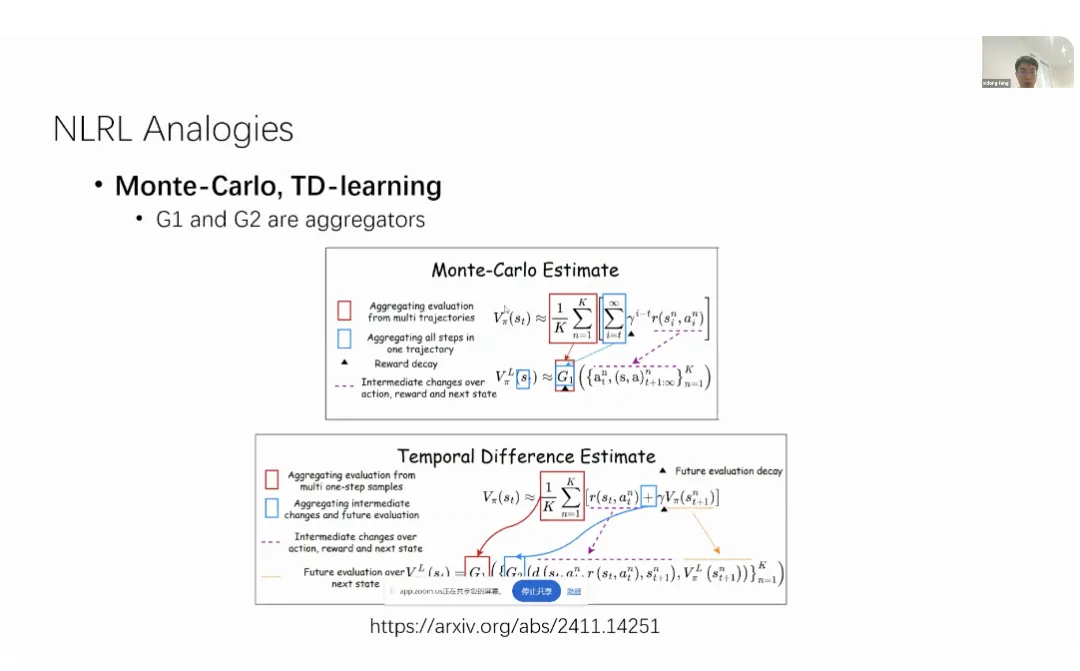
谷歌 Deepmind 研究员冯熙栋初步阐述了将强化学习的组成部分用自然语言描述出来的理念,将会把所有强化学习的概念重新定义为自然语言表示的内容,尝试将策略、值函数、贝尔曼方程、蒙特卡洛采样、时间差分学习以及策略改进操作符等,映射到它们的自然语言对应中。
AIR2025 由伦敦大学学院汪军、Meta GenAI 田渊栋等教授联合主办,致力于推动智能系统的发展,使其能够自主、适应性强且负责任地运行(会议详情及注册可访问官网:https://ai-agent-reasoning.com)。本次会议特别鸣谢来自加州大学伯克利分校的博士后研究员顾尚定。
AI 科技评论截取会议部分精彩内进行编译,以下为核心内容的演讲实录:
新加坡南洋理工大学的安波教授做了主题为《From RL-based to LLM-powered Agents》的演讲,揭示了近年来从基于强化学习的智能体到由大型语言模型驱动的智能体的演变,分享了多项关于 Agent 的工作进展。

去年,我们做了一些工作,结合了一个临时模型,以提高其在某些基准问题中的性能。我们的方法是尝试从与环境的交互中学习策略,因此它具有很强的落地能力,所以我想我们在这里尝试结合先验知识的优势,从模型和落地能力中汲取优势,以提高性能。
因为对于这项工作,我们发现利用知识模型可以提高其在某些实际工作场景中的性能。
推理和推断非常重要,尤其是在 OpenAI-o1 和 DeepSeek R1 发布之后,我们有一个纯粹基于自己研究的版本,这确实非常困难。
但事实上,我们在 OpenAI 发布相关模型之前就发布了关于 Q* 的第一篇论文。我们需要一个 G 函数,用于估算从初始状态到当前节点的成本。在我们的工作中,我们使用的 G 函数是通过利用文献中的数据来训练模型的。对于启发式函数(h 值),我们实际上是自己进行了修正。
所以,基于我们的数据,训练这样一个强大的模型有很多方法。最终,我们将这两者结合起来,并应用 A* 搜索算法,以提升大型语言模型的推理能力。

所以,我们早期做了些实验。你可以降低那些数值,因为那时候基础模型还不够强大。我想关键点是,如果你应用这种推理方法,它可以提升基础模型的性能。
然后我们以某种方式训练它们的 Q 值函数。所以,我们还在考虑是否能够克服困难,例如,将这种方法应用于改进最近的 DeepSeek 模型以及其他模型。

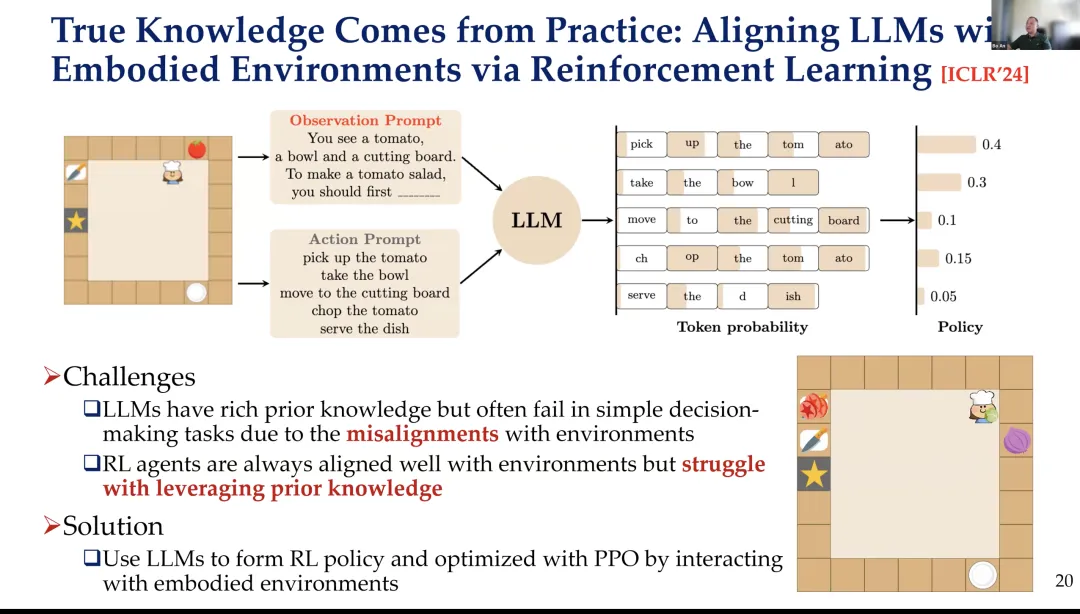
所以,我们在比较控制方面也做了一些关于 Synapse 的工作,是我们去年年初发表的成果之一。这些工作涉及一些想法,比如状态抽象训练、从演示中学习,以及使用记忆等方法,来改进计算机控制任务。

我们还提供了一个用于构建通用虚拟Agent的开发者工具包。我们提供了更好的界面,还提供了更强大的前端支持,并且提供了大量的基准测试,用于设计适用于PC控制、计算机控制等场景的通用虚拟Agent,也适用于移动设备的控制。
接下来的这项工作涉及利用语言模型驱动的智能体来玩具有挑战性的电子游戏。
因此,我们构建了一个智能体架构,包括不同的组件,例如我们需要理解环境。它包含一个反思模型、记忆模型、检索模型等,用于应对许多具有挑战性的电子游戏和不同的软件。这个项目是开源的,对于感兴趣的人非常有吸引力。

我们最近做了一些尚未发表的工作,是关于使用强化学习(RL)对语言模型进行微调的。
我想这在某种程度上与一些早期工作有所不同,在我们过去看到的大多数工作中,强化学习并没有涉及智能体。你知道的,人们只是构建不同的组件,使用语言模型作为大脑,并结合其他组件来处理复杂任务。
但在这里,我认为在未来,对于许多现实世界的问题,我们需要强化学习的能力。然而,如果我们想将强化学习应用于这些场景,会面临许多挑战,其中最显著的是探索空间的指数级增长。因为开放和实际动作技能的采样空间会随着矩形的大小和厚度呈指数级增长,因为探索空间是在token级别上的,所以token空间非常庞大。因此,我们需要解决探索问题。同时,我们注意到并非所有token在最终决策动作中都发挥有意义的作用。
所以,我认为我们在这里得到的启示是,我们必须设计一些机制来决定如何进行更有效的探索,以便提高强化学习微调的效率,从而提升语言模型的性能。因此,我们设计了一个名为“CoSo”的方法,它包含几个关键思想。首先,我们使用事实推理来识别对动作至关重要的token。
不是每个token都对智能体最终采取的动作产生影响,或者产生相同的影响。因此,我们使用因果推理来找出这些token,然后利用这些信息来决定如何进行探索。其次,我们可以中断优化过程,将我们的探索集中在那些有影响的token上。
这是利用我们在第一步中学到的结果。然后我们尝试进行了许多实验,可以看到这种方法显著提高了视觉语言模型(VLM)在一些非常具有挑战性的任务中的性能。我认为这还是一项正在进行的工作,例如我刚才提到的创造性工作。

初创公司 Weco Al 的 CTO Yuxiang 做了题为《AlDE: Searching Intelligence in the Space of Solutions》的分享,阐述在解空间中寻找智能的新思考,介绍了一种由人工智能驱动的强大的 Agent—— AIDE。
我们之所以称之为 AIDE 是因为,它就像一种由人工智能驱动的强大的 Agent,能够处理完整的机器和工程任务。所以,如果将机器学习和工程视为一个代码优化问题,那么它就会将整个搜索或代码优化的过程形式化为在解空间中的树搜索。在这个被形式化的解空间中,它只是一个任何大语言模型都可以编写的代码空间。
你可能见过其他更具体的Agent,比如那些提示 APIAgent 或反应式 Agent,它们将所有历史解决方案组织成树状结构。然后,将所有这些历史解决方案纳入上下文中,但这个过程实际上是递增的。因此,它会迅速积累上下文信息,所以在长期的代码优化过程中,它可能不会表现得很好。

所以,这个问题被重新定义为一个优化问题。机器学习可以在机器中完成,然后我们可以定义所有相关的评估指标。这与我们提出的机器学习工程 Agent 非常契合,其定义的奖励或优化目标也非常简单。我们只是在这个代码空间中进行搜索,目标是优化机器学习代码和机器学习工程任务中的目标函数。这个目标函数可以是验证精度、损失,或者是任何与你的机器学习成本相关的指标。
而代码空间在本例中被非常具体地定义为用于解决该问题的Python脚本空间。好处是我们现在可以在一个公平的指标上比较解决方案,并且使这些依赖于单一标准已知评估的研究方法更加统一,整个搜索过程也会更加稳健。

因此,我们开发了这种算法,它本质上是一个树搜索问题。你从一棵空树开始,首先会生成一个初始节点,实际上是一组基础解决方案。然后,它通过查看现有的代码和现有的解决方案,迭代地提出新的解决方案。这些解决方案已经生成了,然后它会提出你的解决方案,并且基于这个想法,它会生成那段代码,然后运行代码以评估解决方案,并记录新的节点。
这里的评估指标是滚动(scroll),通常在机器学习任务中,这个指标可以是精度(accuracy)、损失(loss)或者随便你怎么称呼它。然后它会根据这个指标选择下一个节点,以便进一步优化。所以,它涉及了所有这些搜索策略、总结操作符以及编码操作符。这些操作符不再完全由算法定义,而是部分由大型语言模型定义。

所以,为了更直观地展示,我们从 S0 开始,这是一个初始的空解决方案,也就是我们的数据状态。我们还没有任何现有的机器学习任务的解决方案,然后它开始起草三个。例如,起草三个方向不同的解决方案。所以在提示中,有一个技巧是我们会明确要求它探索不同的方向,以确保 S01、 S2 和 S3 之间有足够的多样性。然后在下一步,它会选择一个节点开始优化。
例如,尝试不同的步骤来修复问题,如果成功修复了,它就成为一个有效的解决方案。然后这个解决方案就被存储为一个有效的解决方案,此时你有了一个当前最佳节点,比如 S5,然后它开始探索下一个要优化的节点。它会保证每个草拟的解决方案至少被探索一次,并且会从 S2 等节点分别生成另一个改进方案,然后评估为解决方案6或7,这个过程会不断持续,直到用尽所有的优化步骤。
所以最终,选择最优解其实相当简单,因为所有这些解决方案都是用相同的评估指标来评估的。所以,基于评估指标,你就能得到那个最优解。

是什么定义了整个过程呢?有几个关键组件。首先是搜索策略。在这个案例中,我们实际上采用了一个非常简单的热编码策略。
在起草阶段,当它起草多个解决方案时,由于它还没有一棵树,也就是说我们还没有分配初始解决方案,它会创建多个解决方案来探索不同的方法。而在调试阶段,当它进入调试阶段后,它会有一个最大调试步数限制,它会在那个节点停留,直到达到允许的最大调试步数。
通常我们会将这个最大调试步数设置为10到20步,以避免这个Agent花费过多时间在调试上,从而陷入几乎无限循环,浪费大量时间和计算资源。当然,最重要也最有趣的部分并不是什么时候选择一个节点来进行改进。
所以当它完成调试或起草后,就会进入一个阶段,来改进一个桶节点。这只是一个贪婪算法,它会选择树中当前表现最好的解决方案,然后决定进一步优化树中表现最高的那个节点。

所以在编码操作符中,我们也会根据不同的阶段采用不同的提示策略。比如在起草阶段,我们会鼓励它为模型架构和特征工程制定一个计划,并要求它生成一个单文件Python程序来实现这个计划。在底层阶段,Agent会收到错误日志和堆栈跟踪,以识别问题所在。
然后,它会通过保留整体先前的方法来纠正问题。因此,我们确保调试实际上不会改变解决方案本身。在改进模式或改进阶段,我们会提示Agent提出一个原子级别的改变。这是另一个我们希望纳入这个框架的观察结果,即每一步实际上都是可解释的。行动本身是可解释的,并且是原子性的。
因此,我们不允许Agent或大型语言模型一次提出多个改进。相反,我们会提示它逐步、增量地进行改进。在这个过程中,我们不会跳过任何中间步骤的优化想法,这使得它能够进行更细致的探索,并且在整体上更具可解释性。
也就是说,它能够更好地展示出达到最优解的最佳路径是什么。例如,切换优化器、添加一层、使网络变得更深,或者从一种架构转换到另一种架构、添加正则化等。如果你检查它最终生成的树轨迹或树结构,你会发现很多这样的原子优化步骤,而且很多时候这些步骤是非常有洞察力的。

最后,因为一个最大的问题是你需要管理上下文,比如可能需要运行8个步骤。例如,OpenAI运行了500个步骤,即使是Gemini,也没有办法真正处理那么长的上下文。所以,必须有一种方法来管理上下文。这就是我们所说的总结操作符,它会提取相关信息,以避免上下文过载。
总结操作符会包含性能指标,比如当前的准确率、高参数设置和调试阶段的信息。这是非常重要的,尤其是在调试阶段。好处是我们可以截断它之前可以处理的节点数量。
我们可以将总结后的信息放入大型语言模型的上下文中,以生成调试节点或改进节点。这将保持一个几乎恒定的窗口大小,供Agent使用,这使我们能够真正扩展到很长的时间范围,比如对比步骤。
而且,因为我们将其定义为逐步改进,这也使得整个优化操作符变得无状态。它不再依赖于整个轨迹,而是无状态的,不会像提示或上下文大小那样呈爆炸式增长。

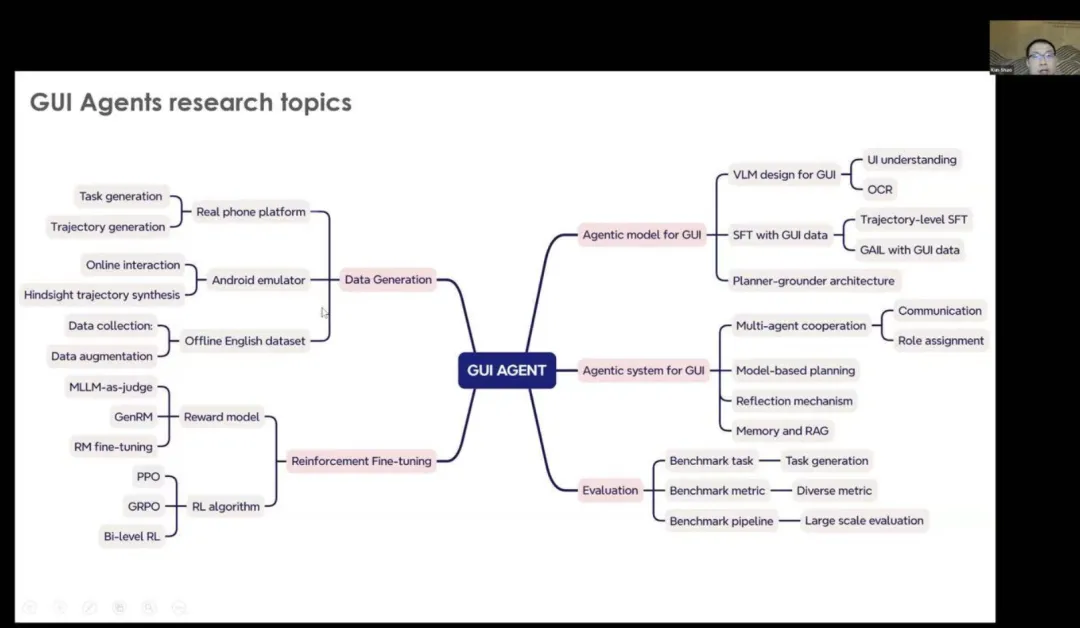
来自 Huawei London 的邵坤做了主题为《Towards generalist GUl Agents: model and optimization》的演讲,介绍了面向通用型 GUI Agent 的模型和优化。
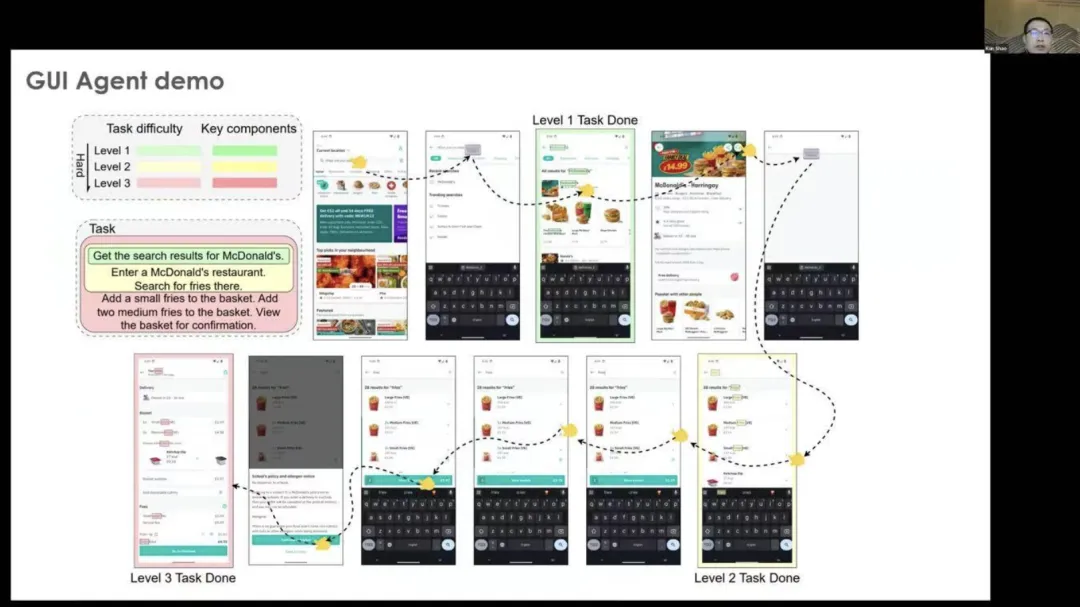
以下是GUI Agent的演示,他们有不同的任务,比如我们有三个不同的平台。第一个是获取关于美元的研究结果,我们可以从主用户界面页面开始。然后,我们可以执行一些步骤前往麦当劳,进入麦当劳餐厅并搜索那里的薯条,我们还可以设置多个步骤并提高目标。这就是GUI Agent可以帮助我们的地方。

在另一个网站上,GUI Agent 也许可以找到一些更好的解决方案,帮助人类完成这类任务。这就是 GUI Agent 的意义。
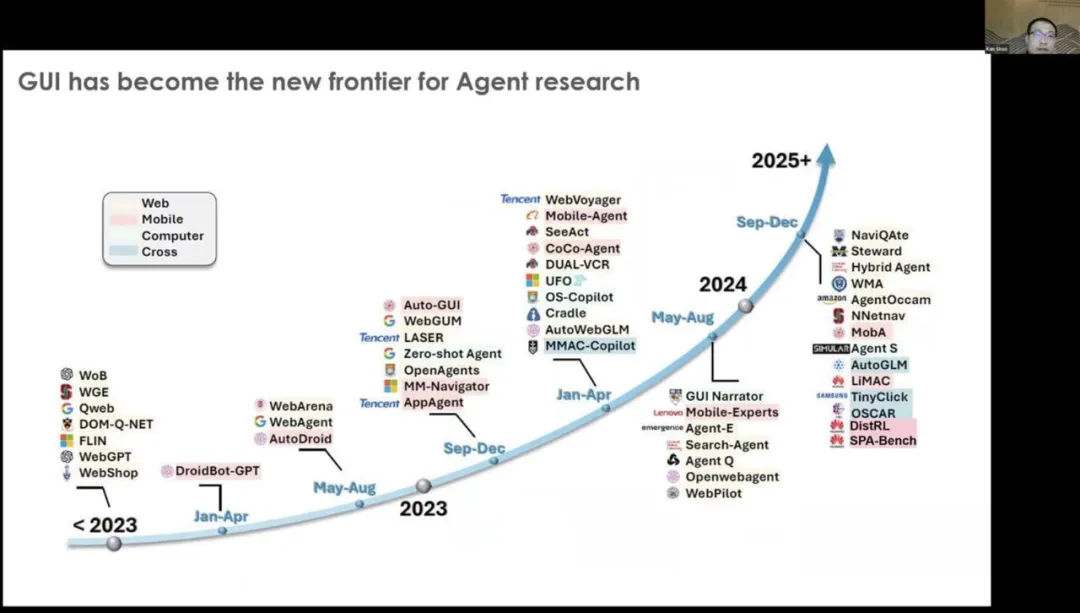
从2023年到2025年,你可以看到 GUI Agent 已经广泛流行起来。它重新引发了对Agent研究的关注,无论是学术界还是大型科技公司都在关注GUI Agent。这种关注不仅局限于移动设备,还涵盖了网站和计算领域。











(文:极市干货)