
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
全球AI领导者英伟达在“GTC 2025”开发者大会上宣布,开源人形机器人通用大模型GR00T N1。
该模型能够处理多模态数据,包括语言、图像、视频,可在家务、工厂等多样化环境中执行复杂操作任务。
值得一提的是,GR00T N1的核心架构采用了模拟人类思维的“快慢思考”模式,可以让机器人的做法、思维更像人类,从而提升动作指令准确率。
开源地址:https://huggingface.co/nvidia/GR00T-N1-2B
GR00T
N1的核架构的设计灵感来源于人类的快慢思维处理方式,使用了扩散变换器模块(System 1)和视觉-语言模块(System
2),能将复杂的任务分解为两大块实现高效处理。
视觉-语言模块是 GR00T N1 的“大脑”,负责处理和理解输入的图像与语言指令。这是一个在互联网规模数据上预训练的模型,具备强大的视觉和语言处理能力。
当机器人接收到任务指令时,例如“拿起红色苹果并将其放入篮子”,视觉-语言模块会首先对输入的图像进行编码,将场景中的物体、背景等视觉信息转化为一系列的图像tokens。
还会对语言指令进行处理,将指令中的关键词、语义结构等转化为文本标记(text tokens)。这些图像和文本标记随后被送入Eagle-2 VLM 的中间层进行联合编码,生成包含任务语义和视觉上下文信息的特征表示。
这些特征表示不仅包含了对任务目标的理解,还融合了对环境的感知,为后续的动作生成提供了丰富的语义信息。
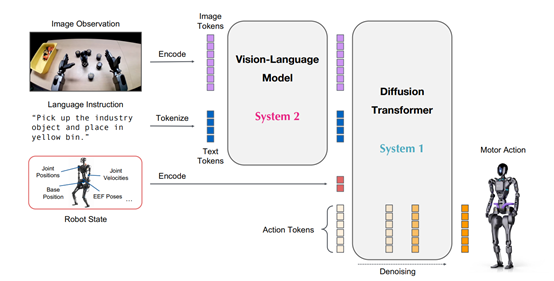
扩散变换器模块(System 1)则相当于 GR00T N1 的“四肢”,负责根据视觉-语言模块提供的信息生成具体的动作指令。它基于扩散变换器(DiT)架构,通过动作流匹配技术进行训练。该模块接收来自视觉-语言模块的特征表示,以及机器人自身的状态信息(如关节位置、末端执行器姿态等),并将其与动作标记(action tokens)结合。
在训练过程中,模型会学习如何从带有噪声的动作标记中逐步去除噪声,最终生成符合任务要求的动作序列。这一过程类似于人类在执行任务时的快速反应机制,能够根据当前的感知信息和任务目标,迅速做出相应的动作调整。
扩散变换器模块在生成动作时,会考虑机器人的物理特性,如关节的运动范围、末端执行器的抓取能力等,确保生成的动作在物理上是可行的,并且能够高效地完成任务。
在实际运行中,这两个模块紧密协作。视觉-语言模块通过深度理解任务指令和环境信息,为扩散变换器模块提供清晰的任务目标和环境上下文;扩散变换器模块则根据这些信息,快速生成精确的动作指令,驱动机器人完成各种高难度任务。
训练数据方面,GR00T
N1采用了新颖的“数据金字塔”结构,能将不同来源的数据按照规模和实体特异性进行分层,能充分利用大规模数据的泛化能力,同时确保模型在真实机器人执行任务时的准确性和适应性。
在数据金字塔的底层,是大规模的网络数据和人类视频数据。这些数据提供了广泛的视觉和行为先验知识,帮助模型学习人类的自然动作模式和任务语义。例如,Ego4D 数据集包含了大量日常活动的第一人称视角视频,涵盖了各种人类与物体的交互场景。
这些视频数据虽然没有直接的动作标签,但通过其中的视觉信息和语言描述,模型可以学习到丰富的任务语义和自然的动作模式。
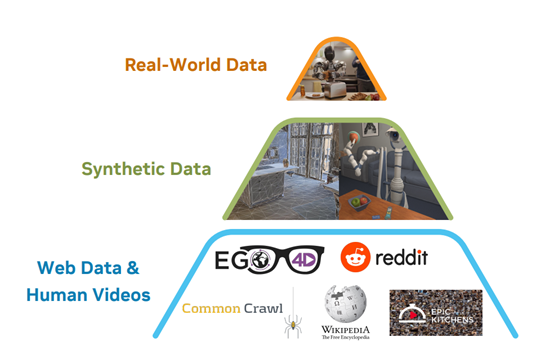
中间层是通过物理仿真和神经生成模型产生的合成数据。这些数据的生成方式多样,能够显著增加训练数据的多样性和规模。而DexMimicGen是一个重要的合成数据生成工具,可以从少量人类演示中自动生成大规模的机器人操作轨迹。通过将人类演示分解为对象中心的片段,然后对这些片段进行转换和组合,DexMimicGen 能够生成新的演示数据,从而为模型提供丰富的训练样本。
数据金字塔的顶层则是真实机器人硬件收集的数据。虽然这些数据的规模相对较小,但它们提供了模型在实际执行任务时的关键反馈。真实机器人数据的收集通常需要大量的时间和人力,但它们对于模型的训练至关重要。这些数据确保了模型能够适应真实机器人的物理特性和执行环境,从而在实际应用中表现出色。
例如,GR00T N1 的研发团队收集了大量 Fourier GR-1 人形机器人的操作数据,这些数据涵盖了各种桌面操作任务,为模型提供了丰富的实际操作样本。
(文:AIGC开放社区)