
今天是2025年3月26日,星期三,北京,天气阴。
今天我们来看多模态的话题,围绕视觉领域RAG技术总结和多模态R1用于目标检测方案Vision-R1。
对了,GPT-4o发布原生图像生成功能。技术特点方面,模型直接从文本提示生成图像,不再调用独立的DALL-E文生图模型。风险方面,OpenAI承认,也存在一些局限性,例如也会受到模型幻觉影响,同时在密集文字和非拉丁语文字【也就是中文这些】的图像生成方面,也更容易出现问题。评测可看,https://mp.weixin.qq.com/s/O1Rrv4ua5CYBSn4HpjJ0qw
其中比较有冲击力的对文字方面的建模,以及其技术架构到底是啥,有的说不是基于扩散模型做的,而是基于全模态,具体是什么,我们后续跟进。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、视觉领域多模态RAG技术总结
视觉领域RAG,可以针对性的看一个技术总结,《Retrieval Augmented Generation and Understanding in Vision: A Survey and New Outlook》(https://arxiv.org/pdf/2503.18016),关注视觉理解和视觉生成两个子领域。
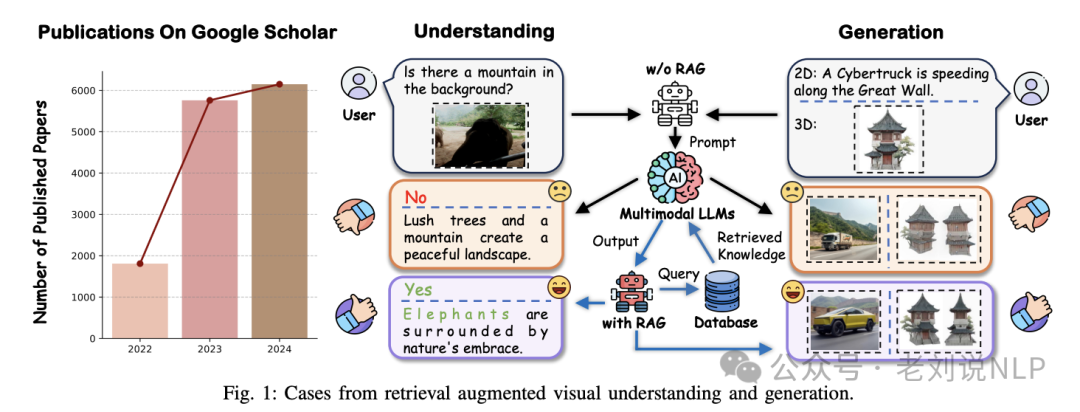
在视觉理解领域,RAG被应用于从基本图像识别到复杂应用如医学报告生成和多模态问答等任务。例如:
目标检测任务,通过检索相关类别和概念来丰富视觉特征,从而提高目标检测的准确性;
图像分割任务,利用检索到的相似样本来增强分割模型的训练数据,从而提高分割的准确性
图像字幕生成任务,通过检索相似风格图像、检索相关字幕、以及同时检索图像和字幕嵌入。
图像识别任务,通过检索模块增强标准的图像分类管道,以提高识别准确性。

在视频理解领域,RAG技术被应用于视频分类、目标检测和问答等任务。
对于视频分类任务,使用检索增强生成模型来提高视频分类的准确性;
对于目标检测任务,在目标检测中通过检索相关视频片段来增强检测模型的性能;
对于视频问答任务,通过检索相关视频片段和文本信息来提高视频问答的准确性。
但是,对于长视频理解任务,存在平衡计算效率与全面理解以及实时处理和内容一致性的挑战。
在图像生成领域,RAG技术应用于从文本描述生成真实图像的任务。
在文本引导生成任务上,使用检索模块来增强文本到图像的生成过程。
在多模态框架上,利用多模态数据库中的多样数据来源来改进视觉生成。
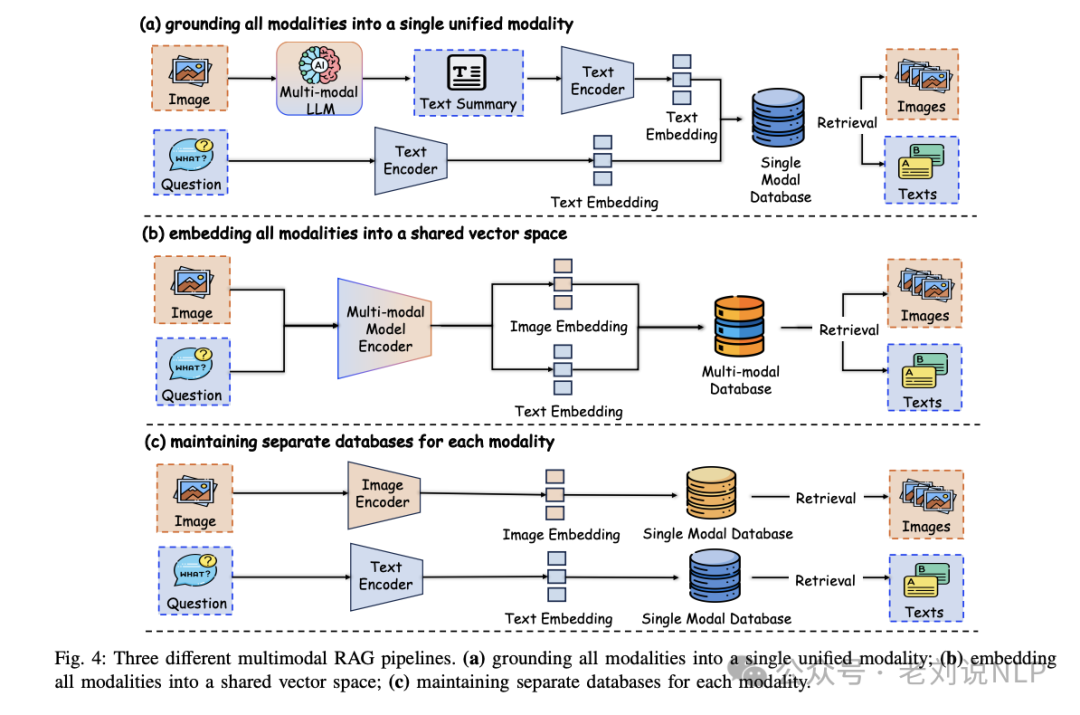
但是,其中存在一个较大的问题,如何更好地平衡不同模态的贡献,避免过度依赖某一模态(如文本),也是一个重要的挑战。
二、多模态R1用于目标检测方案Vision-R1
继续看这方面的工作,《Vision-R1: Evolving Human-Free Alignment in Large Vision-Language Models via Vision-Guided Reinforcement Learning》,https://arxiv.org/pdf/2503.18013,https://github.com/jefferyZhan/Griffon/tree/master/Vision-R1,主要用在目标定位任务,创新点在于训练时动态调整奖励,可以细看其中的奖励函数。
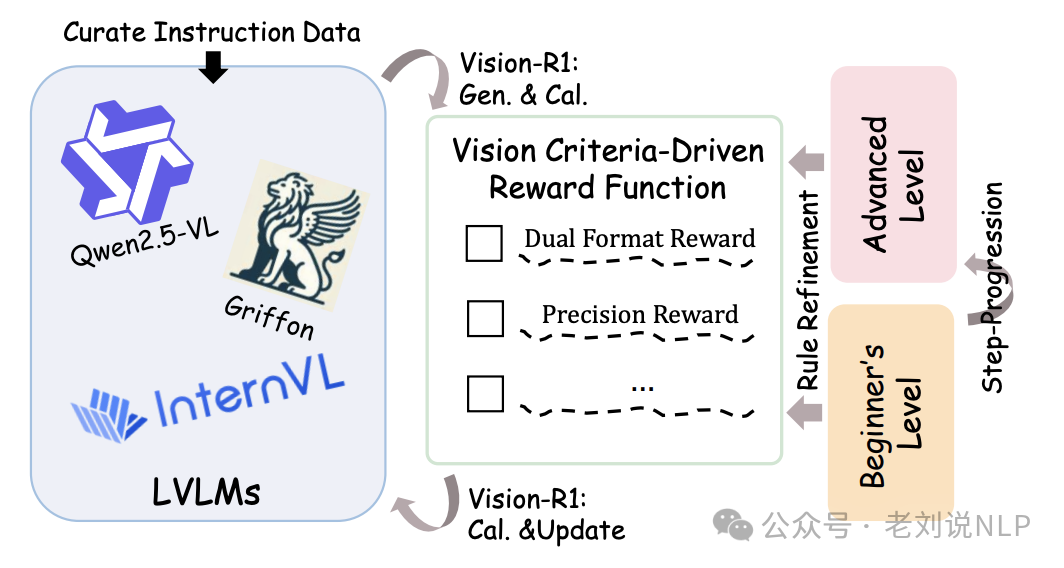
看两点:
1、强化学习奖励函数设计
强化这块,核心就是这个,奖励函数。
标准驱动的奖励函数设计上,以视觉反馈为基础对每个完成情况进行定量评估,结合了多维反馈,包括:双重格式奖励,确保预测结果符合预定义的模板格式和内容约束;召回奖励,反映模型能否全面预测所有感兴趣的目标;精度奖励,关注每个完成实例的预测质量,鼓励模型生成高质量的边界框。
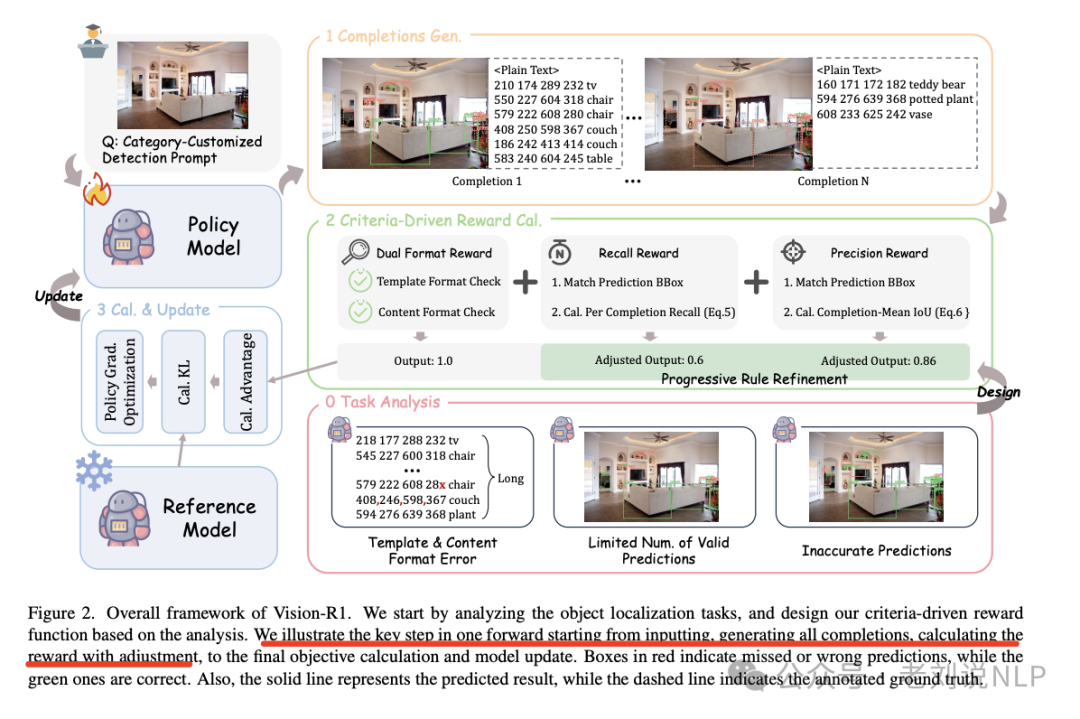
公式可形式化为:
reward=reward_DF+reward_recall+reward_prec。
其中,reward_DF、reward_recall和reward_prec分别表示双重格式奖励、召回奖励和精度奖励。
此外,引入渐进规则细化策略,在训练过程中动态调整奖励标准,以促进模型的持续改进并防止奖励攻击。
具体实现也很有趣,通过惩罚低召回率和平均IoU的预测,而给予高召回率和IoU的预测全额奖励,增加预测与实际奖励之间的对比度。训练过程分为初始学习和高级学习两个阶段,逐步提高奖励标准,以防止奖励攻击并确保持续进步。
2、训练数据集及模型选型
构建了一个包含49K样本的强化学习数据集,包括30K对象检测样本、9K视觉定位样本和10K指代表达理解样本,数据来源包括MS COCO、ODINW和V3Det等开源数据集。
模型方面,在Qwen2.5-VL-7B和Griffin-G-7B模型上实现Vision-R1,使用Open-R1及其多模态变体框架进行训练。
参考文献
1、https://arxiv.org/pdf/2503.18016
2、https://arxiv.org/pdf/2503.18013
(文:老刘说NLP)