

极市导读
通过设计具有平滑特性的常微分方程作为神经元核心结构,构建平滑神经网络作为强化学习策略网络,显著提高了输出动作的平滑性,且无需额外滤波器和动作变化率惩罚。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

本文介绍清华大学智能驾驶课题组(iDLab)在 ICLR 2025 (Spotlight) 发表的最新研究成果《ODE-based Smoothing Neural Network for Reinforcement Learning Tasks》。
该算法创新性地设计了一种具有平滑特性的常微分方程,可以作为神经元的核心结构实现平滑控制。基于这种特殊性质的神经元,我们构建了平滑神经网络(Smooth Ordinary Differential Equations, SmODE)作为强化学习的策略网络,在保证强化学习任务性能的同时,显著提高了输出动作的平滑性。该研究工作由清华大学2023级研究生王以诺在李升波教授指导下完成。
论文地址:https://openreview.net/pdf?id=S5Yo6w3n3f
一.背景
深度强化学习(Deep Reinforcement Learning, DRL) 已经成为解决物理世界中最优控制问题的有效方法,在无人机控制[1]、自动驾驶控制[2]等任务中均取得了显著成果。然而,控制动作的平滑性是深度强化学习技术在解决最优控制问题时面临的一个重大挑战。导致深度强化学习生成动作不平滑的原因主要有两个方面,分别是输入的状态中含有高频噪声干扰,神经网络的Lipschitz常数没有受到任何约束。
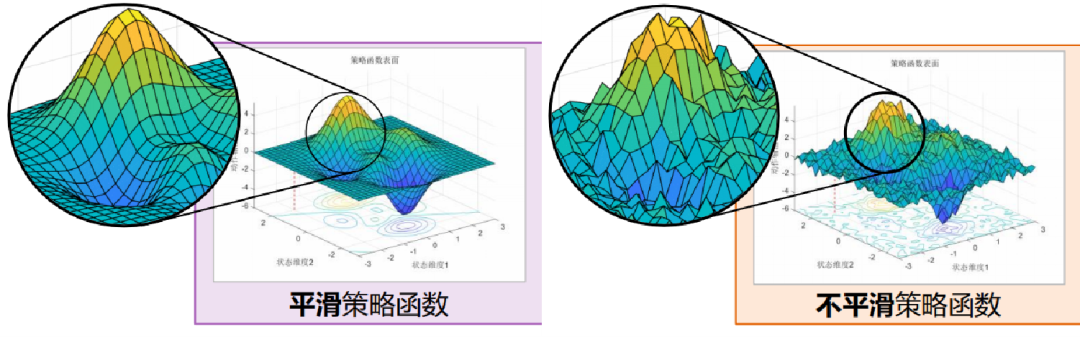
神经常微分网络作为一种连续深度学习模型[3],因其通过神经网络参数化常微分方程来建模连续时间动力学而广为人知。它通过数值求解器沿连续路径积分微分方程,从而高效处理时序数据,在物理系统建模、连续控制和动态系统预测中表现出色。注意到在传统控制理论中,控制系统建模与常微分方程紧密相关,因此我们期望从这个角度出发,将控制系统所具有的低通、平滑的特性嵌入神经元中。那么接下来问题就可以分解为:
1.如何设计常微分方程,能够实现自适应低通滤波以及对Lipschitz常数的控制?
2.如何设计一种使用平滑神经元的策略网络结构,让策略网络天然具有平滑能力,无需添加滤波器和动作变化率惩罚?
为了解决上述的问题,清华大学研究团队提出了一种具有平滑性质的神经常微分网络,SmODE(Smooth Ordinary Differential Equations)。我们首先设计了一个具有一阶低通滤波表达式的平滑常微分神经元,它通过一个可学习的基于状态的系统时间常数,来动态地滤除高频噪声。接着,我们构造了一个基于状态的映射函数g,并从理论上证明了其具有控制常微分神经元Lipschitz常数的能力。以常微分方程作为桥梁,我们实现了将传统控制理论中动态系统低通平滑的性质嵌入神经元当中。最后,在上述神经元结构设计的基础上,我们进一步提出了作为深度强化学习策略近似器的SmODE网络,训练过程中无需加入动作变化惩罚系数,推理过程中也无需额外添加滤波器。
二.SmODE的关键技术
2.1平滑常微分方程设计
为了有效解决高频噪声问题,我们设计了具有低通特性的常微分方程(ODE)。在系统时间常数固定的情况下,虽然较大的时间常数能够保证较好的平滑性,但也会引入额外的延时。当系统需要快速响应时,这些延迟可能会显著影响控制性能。因此,我们提出了一种可学习的方程,将输入信号和神经元状态映射到时间常数的倒数上,从而实现了自适应滤波,公式如下所示:
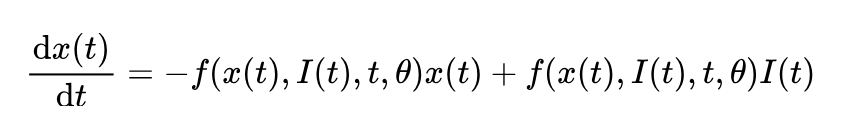
仔细观察上面的公式,Lipschitz 常数的大小可以通过限制等式左侧项的大小来进行控制。需要注意的是,这种控制也必须是与输入信号和神经元隐状态相关的,这样才能减少对控制性能的负面影响。在这篇论文中,我们将上式最右侧的 替换为一个可学习的映射函数 可以得到:
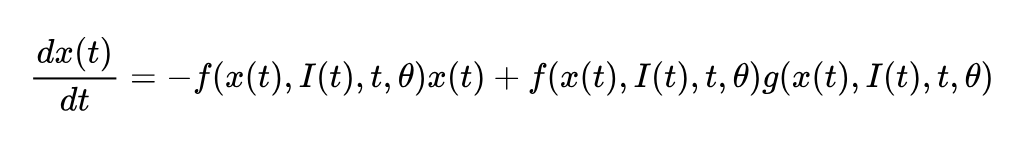
基于上式我们可以证明:
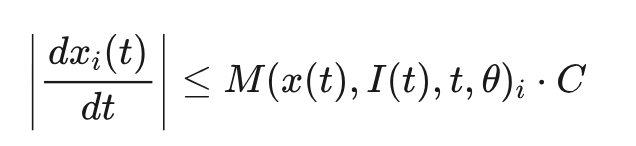
并进行如下分析:
是有界的正常数。这个公式表明,一个平滑常微分神经元的隐状态对时间的导数的绝对值有一个上界,这个上界受到 所控制。因此,我可以通过限制 来限制 大小,从而实现对 Lipschitz 常数的约束。
受到 Lechner et al. [4] 研究的启发,我们使用仿生建模的方式给出了平滑常微分神经元的具体表达式。
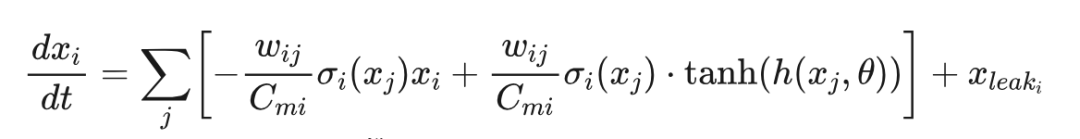
其中 被表示为 被表示为 被表示为 。其余参数的含义详见论文。
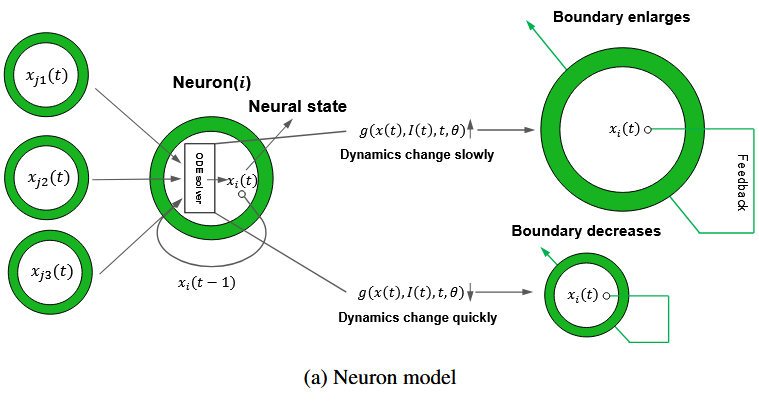
2.2平滑网络结构设计
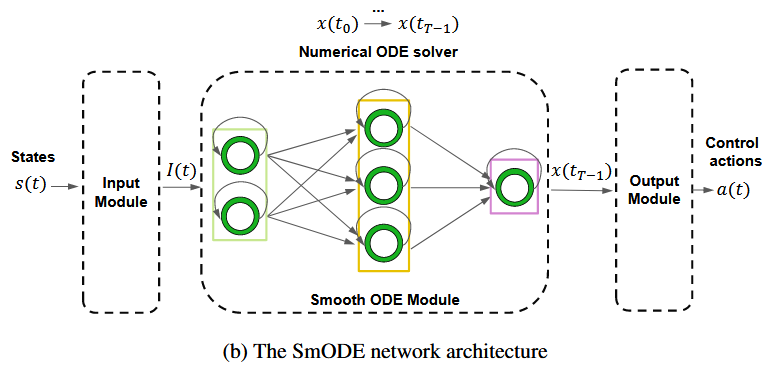
为了提高控制输出的平滑性,我们进一步引入了SmODE网络。该网络可广泛应用于各种强化学习框架中作为策略网络。SmODE的架构如下图所示,结构包括输入模块、平滑常微分模块和输出模块(可以根据任务复杂性判断是否需要)。输入模块是一个多层感知器(MLP)网络,输出模块是一个线性变换层,并应用了谱归一化。平滑ODE模块由三层组成,每层中的平滑常微分神经元数量可根据任务的复杂度进行选择。
2.3 基于SmODE的强化学习算法
SmODE 作为一种通用策略网络可以很方便的与各类经典深度强化学习算法相结合,本工作将其与课题组提出的DSAC[5]算法相结合。相较于基本的策略损失函数,本工作需要额外添加限制时间常数和Lipschitz常数的损失项,因此最终的策略损失函数如下所示:
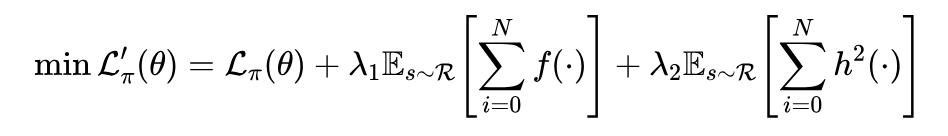
其中 和 是可以调节的超参数, 是 SmODE 网络的平滑常微分神经元的数量。
算法最终的伪代码如下所示

三.实验结果
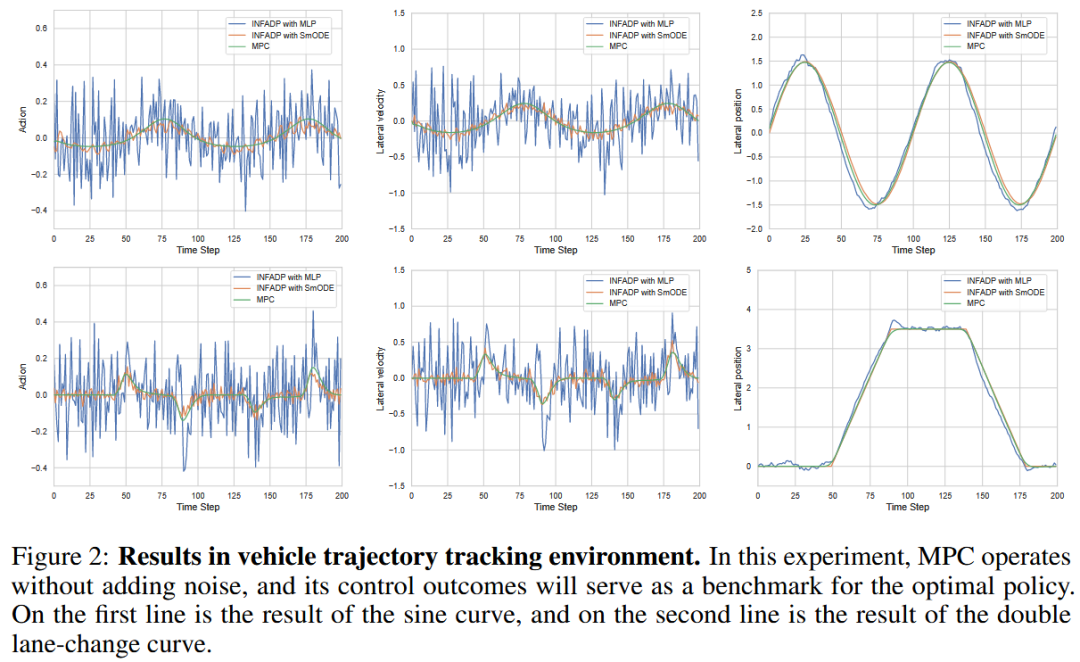
在高斯噪声方差为0.05的条件下,我们对使用MLP和SmODE作为策略网络进行正弦曲线和双车道变换曲线跟踪的实验结果进行了分析,显示出明显的差异。我们使用MPC算法作为无噪声环境下的对比基准。如下图所示,SmODE不仅表现出比MLP更低的动作波动率,还在横向速度变化方面具有更小的波动,从而提高了车辆的舒适性和安全性。
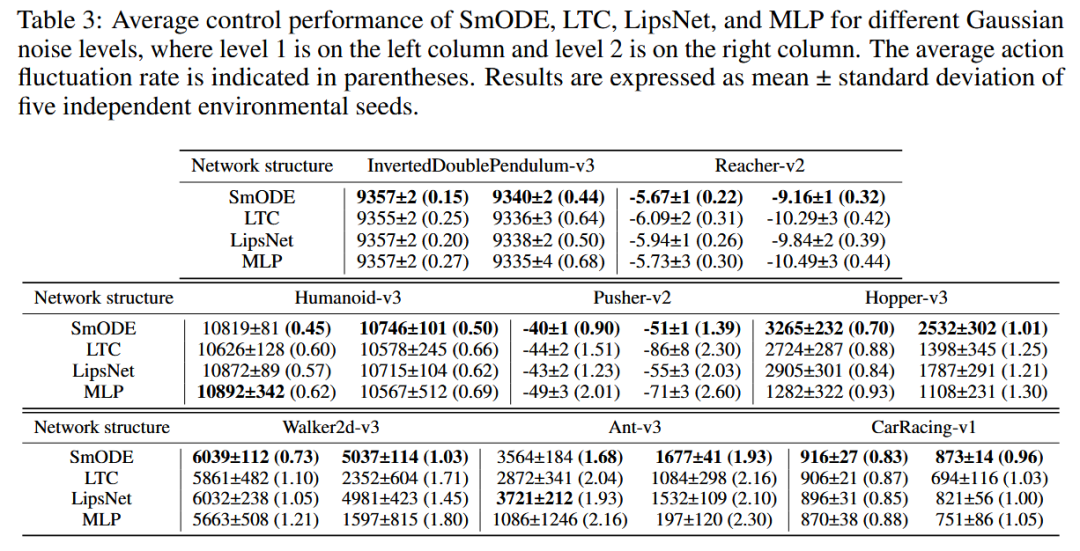
此外,我们在MuJoCo[6]基准中也进行了测试。我们采用了DSAC作为基础的强化学习算法,并将策略网络配置为MLP、LipsNet[7]、LTC[8]和SmODE。在评估过程中,我们在两种高斯噪声水平下进行实验,以模拟不同的现实世界条件。由于不同Mujoco任务的状态值差异较大,我们为八个任务设置了两种高斯噪声水平,如下表所示

在不同高斯噪声水平下,作为策略网络的SmODE相比于LTC、Lips Net和MLP获得了最低的平均动作波动。此外,SmODE在大多数MuJoCo任务中表现出最好的性能。考虑到对动作平滑性和高性能的追求可能存在一定的矛盾,因此并非在所有的实验设置中都能获得最佳的表现是可以理解的。
四.总结
在本研究中,我们提出了一种基于神经常微分网络的方法,用于解决深度强化学习中非平滑动作输出的问题。该网络将常微分方程作为神经元的核心组成部分,赋予神经元低通平滑特性。这种设计不仅能够实现自适应的低通滤波,还具备对Lipschitz常数的有效控制,从而增强了神经元对输入扰动的抑制能力,并实现了更为平滑的输出。作为一种策略网络,与传统的多层感知机和LipsNet相比,SmODE在控制动作输出的平滑性方面表现出色,显著提升了各种强化学习任务中的平均回报。我们期望我们的工作能够为现实世界中的强化学习应用提供新的思路,并推动该领域的进一步发展。
参考文献
[1] Kaufmann E, Bauersfeld L, Loquercio A, et al. Champion-level drone racing using deep reinforcement learning[J]. Nature, 2023, 620(7976): 982-987.
[2]Guan Y, Ren Y, Sun Q, et al. Integrated decision and control: Toward interpretable and computationally efficient driving intelligence[J]. IEEE transactions on cybernetics, 2022, 53(2): 859-873.
[3] Chen R T Q, Rubanova Y, Bettencourt J, et al. Neural ordinary differential equations[J]. Advances in neural information processing systems, 2018, 31.
[4] Lechner M, Hasani R, Amini A, et al. Neural circuit policies enabling auditable autonomy[J]. Nature Machine Intelligence, 2020, 2(10): 642-652.
[5] Jingliang Duan, Yang Guan, Shengbo Eben Li, Yangang Ren, Qi Sun, and Bo Cheng. Distributional soft actor-critic: Off-policy reinforcement learning for addressing value estimation errors. IEEE Transactions on Neural Networks and Learning Systems, 33(11):6584–6598, 2021.
[6] Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In Intelligent Robots and Systems, 2012.
[7] Song X, Duan J, Wang W, et al. LipsNet: A smooth and robust neural network with adaptive Lipschitz constant for high accuracy optimal control[C]//International Conference on Machine Learning. PMLR, 2023: 32253-32272.
[8] Hasani R, Lechner M, Amini A, et al. Liquid time-constant networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(9): 7657-7666.

(文:极市干货)