

极市导读
北京通用人工智能研究院BIGAI联合中科大、北大提出In Context Editing,这是一种突破传统微调,从自诱导分布中学习知识的知识编辑新范式!该方法通过优化模型在上下文学习中的分布对其,而非依赖one-hot目标,创新性地将附加知识内化于原始参数空间,保持模型完整性的同时有效地增强知识编辑的鲁棒性。相关成果已被ICLR2025接收。>>加入极市CV技术交流群,走在计算机视觉的最前沿
在不断发展的世界中,更新大型语言模型 (LLM) 以纠正过时的信息并整合新知识至关重要。此外,随着个性化设备和应用程序变得越来越普遍,不断编辑和更新模型的能力是必不可少的。这些设备需要能够调整个人用户的偏好、行为和新获得的知识的模型,确保其响应的相关性和准确性。更新大型语言模型 (LLM) 提出了一个重大挑战,因为它通常需要从头开始重新训练——这个过程在计算上既令人望而却步又不切实际。与人类可以快速且增量地适应不同,现有的 LLM 微调范式并非旨在促进高效、增量更新,从而追求这些模型的适应性特别困难。
为了解决这些限制,引入了 Consistent In-Context Editing (ICE),这是一种新方法,它学习上下文分布来有效地内化新知识。具体来说,ICE 引导模型的输出分布 p_θ (x|q) 与由包含目标知识的上下文 c 引起的上下文分布 p_θ (x|[c,q]) 对齐。ICE最小化了这两个分布之间的 KL 散度,鼓励模型内化新知识。
然而,初始上下文分布可能并不总是与所需的更新目标完美对齐,因此需要在优化过程中动态调整它。通过将上下文损失与原始微调损失相结合来实现这一点。由于微调损失最小化,输出分布和上下文输出分布都引导到所需的目标。上下文损失作为正则化项,限制了这些修改的程度,从而保证了模型的完整性并防止意外退化。这种方法允许模型在保持其原始行为的同时适应所需的更新,如下图所示。
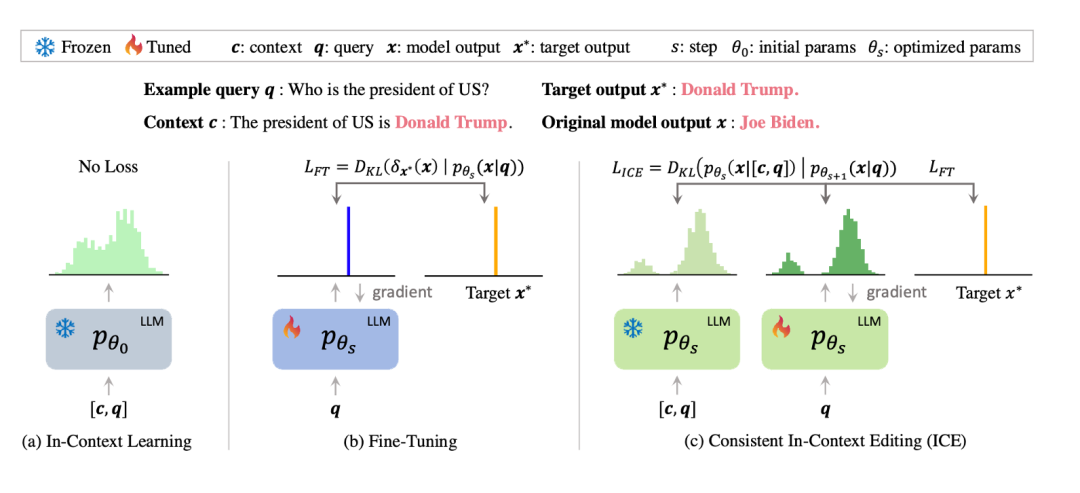
论文题目:In-Context Editing: Learning Knowledge from Self-Induced Distributions
论文链接:https://arxiv.org/abs/2406.11194
数据&代码:https://github.com/bigai-ai/ICE
In Context Editing的亮点:
-
引入了上下文编辑(ICE),这是一种新颖的知识编辑方法,它学习上下文分布而不是 one-hot 目标,为传统的微调提供了更稳健的替代方案。 -
开发了一个优化框架,它使用基于梯度的算法细化目标上下文分布,从而能够动态适应模型以正确合并新知识。 -
提供了经验证据,证明了ICE的有效性,展示了它在保持现有知识完整性的同时无缝集成新信息,展示了其在持续编辑方面的潜力。
知识编辑问题定义
知识编辑的目标是通过查询-响应对 将新事实合并到语言模型 中。这里 是触发从 检索事实知识的查询,例如"美国总统是", 是编辑后的预期响应,例如"唐纳德特朗普"。这种集成通常是通过最大化概率 来完成的。传统上,知识编辑算法在四个关键维度上进行评估。
Edit Success 衡量模型为查询 生成编辑响应 的能力。令 表示查询-响应对, 为指示函数,度量定义为:
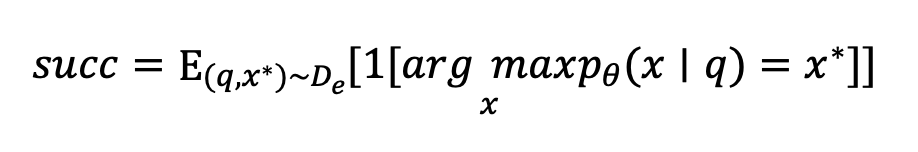
Portability评估模型在多大程度上概括了编辑范围 中改写或逻辑相关查询的知识。对于上述示例,相关查询可以是“美国的第一位女士是”,目标是“Melania Trump”而不是“Jill Biden”。
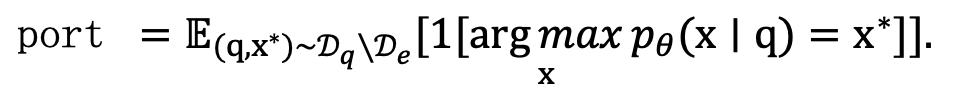
Locality评估模型是否为编辑范围之外的查询维护原始预测:
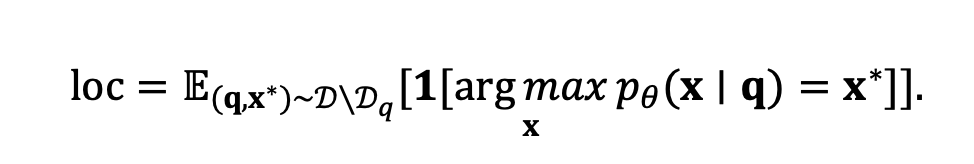
Fluency 估计后期编辑模型输出的语言质量,由 bi- 和 tri-gram 熵的加权和给出,给定 作为 n-gram 分布:
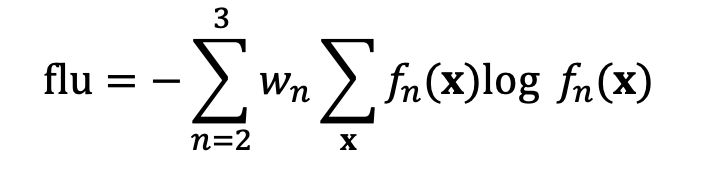
Consistent In-Context Editing (ICE)方法
我们引入了一个一致性条件,即更新后的模型参数 θ 应该满足:
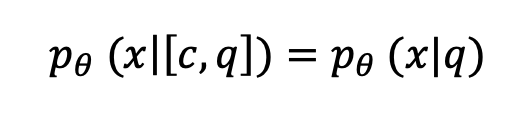
这个条件意味着,在更新后,模型的预测是否应该与上下文 相同,这表明来自 的知识已被内化。为了实现这一点,我们将上下文编辑损失 定义为:
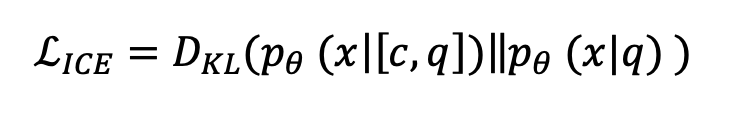
为了确保模型生成正确的目标序列 ,我们还包括微调损失:

其中 是平衡两个损失项的超参数。
优化 :上下文编辑损失 涉及两个依赖于模型参数 的分布,使得直接优化具有挑战性。直接通过两个分布传播损失是不可取的,因为我们的目标是单向优化:我们不打算向 绘制 。为了解决这个问题,我们采用了一种迭代的,基于梯度的方法。在每个优化步骤 中,我们将 视为固定的目标分布(使用当前参数 ),并更新模型参数以最小化到 的散度。这个过程形式化为:
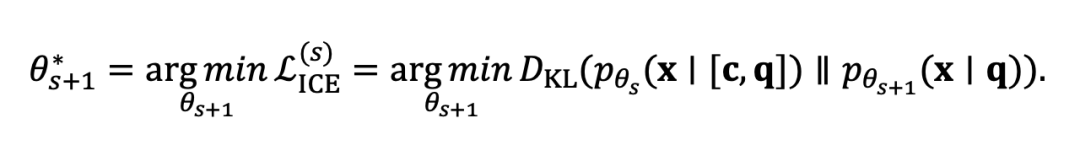
通过迭代更新 ,我们确保模型的预测有和没有上下文收玫,满足等式 中的一致性条件。
优化组合损失 :为了优化等式 中定义的总损失,我们从以 为条件的模型中对序列 进行采样,并最大化组合序列 的可能性。这个过程相当于优化组合损失 。如果采样不以目标为条件,我们将仅优化 。这种方法在算法上很方便,为了防止模型偏离初始参数太远(从而保留不相关的知识),我们采用了受约束微调方法启发的梯度裁剪技术。详细算法如算法 1 所示。

实验与结果
实验数据集
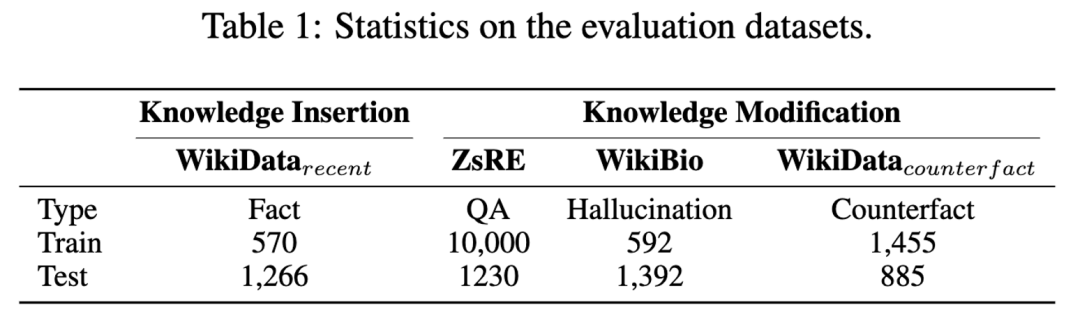
我们使用来自 KnowEdit的四个数据集评估 ICE 的性能,这些数据集通常用于知识插入和修改。所选数据集的详细统计数据见表1。在数据集中,WikiBio数据集不包括评估可移植性度量所需的相关跳跃问题数据。
实验结果
Accuracy: ICE 在所有数据集上始终达到近乎完美的编辑精度,优于大多数基线并匹配最强基线 FT-M 的性能。
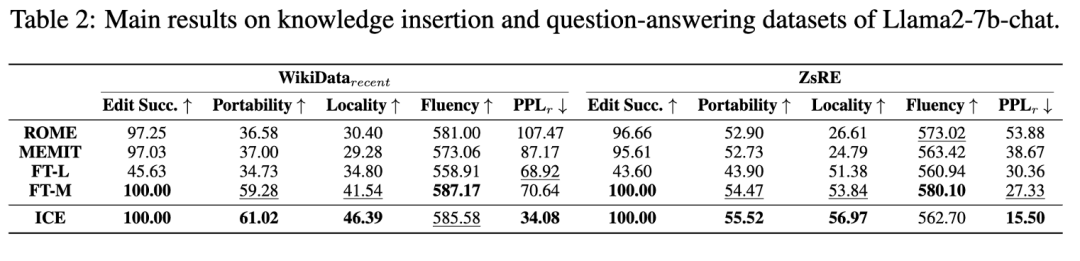
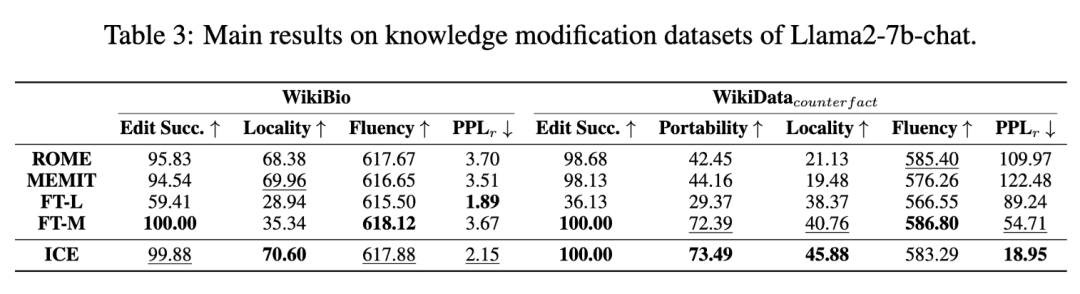
Locality and Portability:随着准确性的提高,由于引入的固有扰动,局部性往往会降低。此外,模型局部性和可移植性之间往往存在负相关关系;局部性意味着模型的变化最小,而可移植性要求模型泛化到相关知识的能力。尽管有这一趋势,ICE 不仅达到了与 FT-M 相当近乎完美的准确度,而且在局部性和可移植性方面也始终优于基线方法。虽然将近乎完美的准确度与 FT-M 匹配,但 ICE 显示出比基线方法更好的局部性和可移植性。与 ROME、MEMIT 和 FT-T 相比,ICE 在 WikiData 和 WikiData 数据集上表现出更高的可移植性大约 30%。这种差异强调,通过利用上下文学习来适应上下文分布,ICE 实现了更好的泛化。此外,ICE 在两个数据集上的局部性方面的表现优于 15% 以上,通过增强基于梯度的调整的鲁棒性来保留不相关的知识。WikiBio 数据集上观察到 99.88% 的轻微性能下降。这可以归因于跨数据集的多样性,这可以在可接受的范围内引入性能的轻微变化。
Fluency and :为了评估语言质量,我们计算了流利度和困惑度。ICE表现出相当好的流畅性,经常名列前茅。虽然其他方法可能在单次编辑中显示稍高的流畅性,但ICE在连续编辑情况下实现了明显更高的流畅性。此外,ICE始终表现出较低的困惑,表明更好和更自然的语言模型性能。它在编辑新知识的同时保持现有信息的完整性,从而在所有度量标准中保持健壮的性能。

消融实验
使用动态目标,我们发现困惑度显着降低,突出了动态目标在生成自然和有意义的句子中的重要性。在比较有和没有上下文的结果时,我们可以看到添加上下文通常可以提高泛化能力。这些消融结果证实了动态训练目标和包含 ICE 中的上下文信息的重要性。
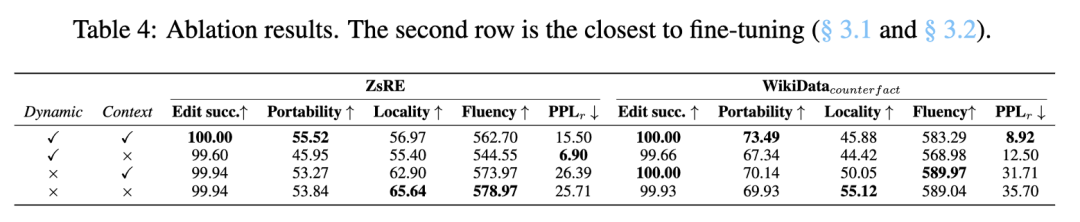
此外,我们检查了超参数 λ 的影响。表 5 中显示的结果表明,简单地设置 λ 到 1.0 会产生模型的最佳性能,这对应于直接最大化目标组合序列的可能性和采样序列。
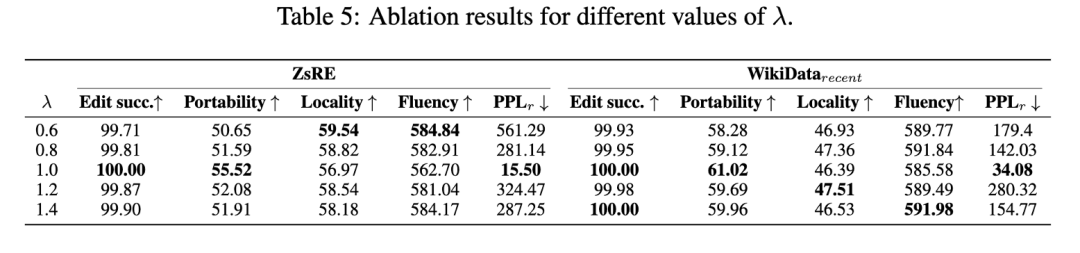
持续编辑
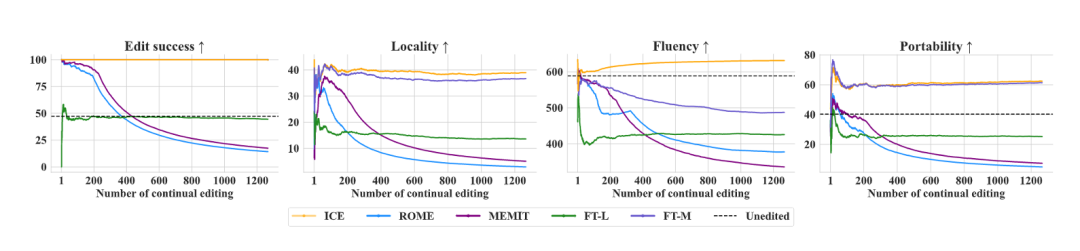
上图说明了模型在持续编辑期间的性能。大多数基线方法(例如 MEMIT、ROME、FT-L)随着时间的推移,准确性和一般性能都显着下降。这种趋势尤其明显,因为应用了更多的更新,导致模型响应中的灾难性遗忘和减少局部性等问题。
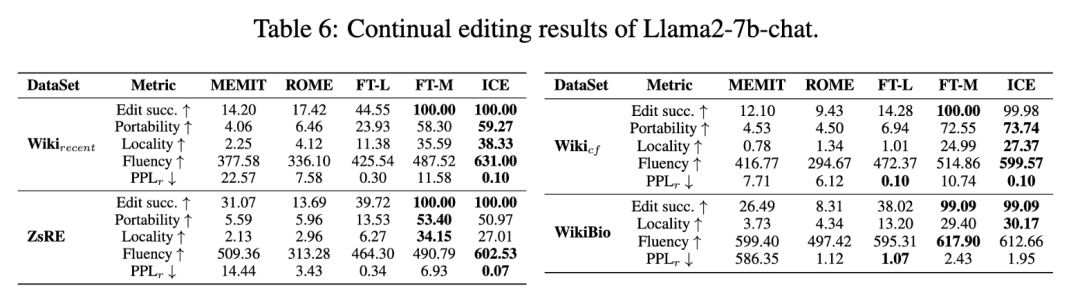
表6给出了所有四个数据集的ICE结果。结果表明,在对整个数据集进行处理后,ICE保持了较高的精度和较低的困惑度。模型的完整性得到了保留,正如流畅性和PPLr指标与基本知识编辑场景保持一致所表明的那样,这表明了对持续编辑的承诺。请注意,尽管FL-L实现了非常低的困惑,但这个结果没有意义,因为准确性非常低,这表明没有合并新的目标信息(这通常会增加困惑)。
收敛性
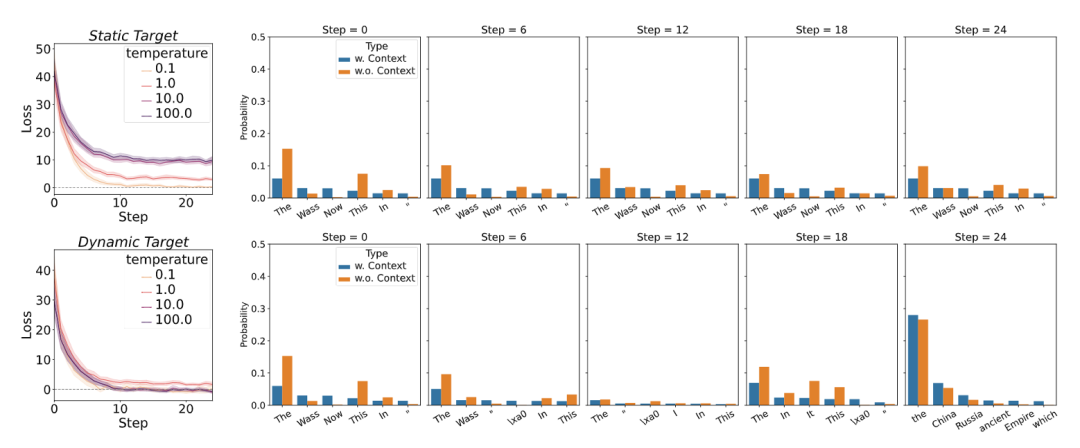
上图的左侧显示了在一定温度范围内优化步骤的损耗曲线。虽然两种优化方案都表现出收敛性,但静态目标始终表现出较高的平衡损失。这一结果可归因于高温环境中固有的方差增加,当采用静态目标时,这会使模型拟合复杂化。相比之下,动态目标促进了迭代改进过程,使模型预测和目标分布逐渐对齐,从而实现较低的平衡损失。
上图的右侧通过一个示例提供了进一步的见解,在这个示例中,与静态目标相比,动态目标促进了对令牌预测的更有效的自适应调整。具体来说,动态目标在优化步骤中减少了重复标记模式的频率,而静态目标保持了重复标记的更高概率。动态目标对重复的抑制对于提高生成文本的流畅性尤为重要。
总结
本文介绍了上下文编辑(In Context Editing, ICE),这是一种新颖的方法,通过针对上下文分布而不是单一热点目标来解决传统知识编辑微调的脆弱性。ICE增强了基于梯度的知识编辑调优,并在准确性、局部性、泛化和语言质量方面表现出色。在四个数据集上的实验证实了它在常识编辑和持续编辑设置中的有效性和效率。总的来说,ICE为语言模型的知识编辑提供了一个新的视角和一个简单的框架。

(文:极市干货)