

极市导读
基于连续 token 的模型比基于离散 token 的模型实现更好的视觉质量。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 Fluid:MAR 连续 token 自回归范式的文生图版本
(来自 MIT,Kaiming 团队)
1.1 自回归图像生成
1.2 Fluid 方法介绍
1.3 实验设置
1.4 缩放性能
太长不看版
本文可以看做是 MAR (Autoregressive Image Generation without Vector QuantizationAutoregressive Image Generation without Vector Quantization) 的文生图版本。
本文研究两个问题:在 scaling 模型的时候,1) 是应该使用连续 token 还是离散 token?2) 在自回归生成时候,是该使用 raster-order 还是 random-order?
本文实证结果表明:
-
基于连续 token 的模型比基于离散 token 的模型实现了更好的视觉质量。
-
生成顺序和注意力机制显着影响 GenEval 分数。与 raster-order 的模型相比,random-order 的模型实现了明显更好的 GenEval 分数。
基于这两个发现,本文训练了 Fluid,一种基于连续 token 的 random-order 自回归模型。Fluid 10.5B 模型在 MS-COCO 30K 上实现了 6.16 的 zero-shot FID,在 GenEval 上实现了 0.69 的分数。
1 Fluid:MAR 连续 token 自回归范式的文生图版本
论文名称:Fluid: Scaling Autoregressive Text-to-image Generative Models with Continuous Tokens (ICLR 2025)
论文地址:
http://arxiv.org/pdf/2410.13863
1.1 自回归图像生成
缩放定律帮助 LLM 取得了前所未有的成功。受这一成功的启发,计算机视觉领域中也涌现了一批缩放自回归模型的工作,尤其在文生图领域。然而,与扩散模型相比,这些模型生成的内容视觉质量不高。尚不清楚类似的缩放定律是否适用于视觉领域。
给定一个 token 序列 ,其中上标 为顺序。
自回归模型将生成问题建模为 “next-token prediction”:
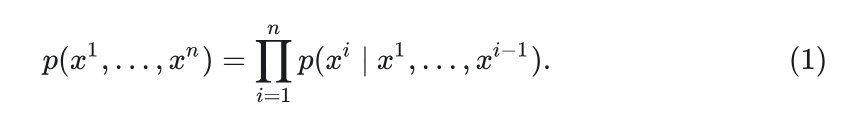
按照链式法则,训练网络来建模 ,并迭代地生成新的 token。
在自回归模型的设计中,有 2 个问题很关键:
-
token :离散或连续的。 -
生成的顺序:raster-order 还是 random-order 的。
离散或连续的 token
自回归模型的目标是估计 。当 token 是离散的,那么图像会被转化为一组离散 image token,然后有一个词汇表,每个 token 对应为词汇表中的一个 id。在训练的时候有 GT 的 id,目标就是最小化模型预测的词汇表 id 与 GT 的 id 之间的 Cross-entropy Loss。大多数自回归图像生成模型,比如 VQGAN,MaskGIT 都依赖这种形式的离散 token。
但是,这种离散化往往会导致图像信息损失。MAR 使用一个小扩散模型来估计每个 image token 的分布,使得 image token 不再需要是离散的,可以以连续的方式建模。这种方法使得我们不再需要 VQ,允许使用连续的 tokenizer 对图像进行建模,产生更好的重建视觉质量。
Raster Order + GPT vs. Random Order + BERT
在自回归图像生成中,有 2 种生成顺序:Raster Order 和 Random Order。如图 2 所示,Raster Order 从左到右依次生成 token,从上到下。这种固定顺序生成非常适合类似 GPT 的架构,它以因果方式预测下一个 token。而 Random Order 允许在每一步生成多个 token。这些 token 的选择可以是完全随机的,也可以是基于一种采样机制,该机制优先考虑具有更高预测置信度分数的 token。
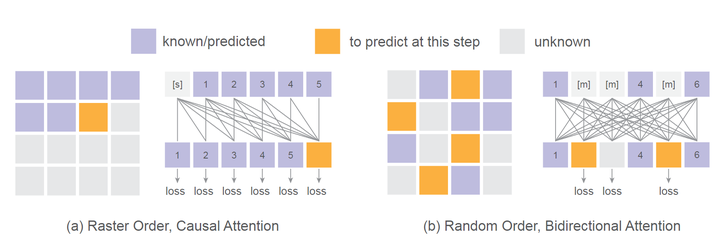
每个生成顺序都有其优缺点。
类似 GPT 的 Transformer 架构,采用 Raster-Order 的模型通过 KV-Cache 支持快速推理。然而,这种因果结构也可以引入性能下降。
Random-Order 生成通常是通过类似 BERT 的 Bi-directional attention 实现的。虽然这种方法没法使用 KV-Cache,但可使模型能够在每个自回归 step 中一次性解码多个 token。
尽管它们具有各自的优势,但仍不清楚哪种生成顺序更适合文本到图像生成任务。本文比较了 Raster-Order 和Random-Order 自回归模型的性能和缩放行为。
1.2 Fluid 方法介绍
针对文本和视觉领域 scaling 模型的性能差距,作者提出了几个假设。
-
大多数视觉自回归模型所需的 vector quantization (VQ) 步骤可能会引入显着的信息丢失,最终限制了模型性能。 -
与语言固有的顺序性质不同,生成视觉内容可能更多地受益于不同的自回归预测顺序。 -
在评估视觉模型中的缩放定律时,通常存在泛化级别之间的混淆:a) 在新数据上使用与训练损失相同的度量 (通常称为计算 Validation loss)。b) 使用不同于训练目标的新度量,比如计算 FID,GenEval,或者视觉质量。
作者假设 power-law scaling 在 “视觉数据 + 自回归模型” 条件下可以适用于 Validation loss,但是不适用于新的指标,比如 FID 等。
为了研究这些假设,作者对自回归模型在文生图背景下的 scaling behavior 进行了全面的实证研究。包括:
1) 模型应该对连续 token 还是离散 token 操作。
2) token 是该以 random-order 生成,还是 raster-order 生成。
为了研究这两个问题,本文使用 Diffusion Loss 使自回归模型与连续 token 兼容。本文将视觉模型 MaskGIT 推广为随机顺序自回归,因为它在概念上以随机顺序预测输出 token,同时保留 “基于已知 token 预测下一个 token 的自回归性质”。
连续 token or 离散 token,random-order 生成 or raster-order 生成,两两组合,一共四种情况,本文分析了四种组合的性能,本文将其参数从 150M 扩展到 3B,并使用 3 个指标评估它们的性能:Validation Loss、FID 和 GenEval 分数。作者还检查了生成图像的视觉质量。
本文的文生图框架如下图 3 所示。
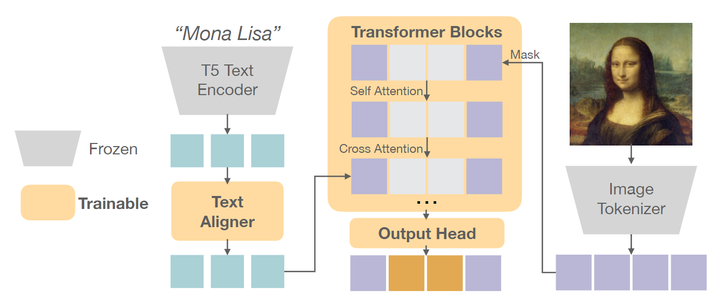
预训练的 image tokenizer 将图像转换为转换为离散或连续 token。然后对这些 token 进行部分 mask,并训练 Transformer 以文本为条件重建 masked token。
Image Tokenizer
作者使用预训练的 Image Tokenizer 将 256×256 的图像编码为 token。Tokenizer 可以是离散的或连续的,便于自回归模型的不同训练目标。
-
离散 Tokenizer:本文用的是在 WebLI 数据集上预训练的 VQGAN。本文遵循 Muse 的做法将每个 image 编码为 16×16 个离散 token,词汇量为 8192。 -
连续 Tokenizer:本文用的来自 Stable Diffusion 的,将图像编码为 32×32 连续 token,每个标记包含 4 个 channel。
为了与离散 Tokenizer 在序列长度上保持一致,进一步把 2×2 连续 token 分组成单个 token,对齐最终序列长度 256,每个标记包含 16 个 channel。如图 4 所示,连续 Tokenizer 可以实现明显高于离散 Tokenizer 的重建质量。

文本编码器
原始文本 (最大长度为 128) 由 SentencePiece 做 tokenization,并通过预训练的 T5-XXL 编码器转化为 text embedding,该编码器有 4.7B 参数且在训练期间冻结。为进一步对齐文本嵌入以生成图像,在 T5 embedding 之上添加了一个由 6 个可训练的 Transformer Block 组成的小型 Text Aligner,获得最终 text embedding。
Transformer
在将原始 image 编码为一系列 token 后,使用标准的 Decoder-only Transformer 进行自回归生成。每个 Transformer Block 由 3 个连续的层组成:Self-Attention, Cross-Attention, 和 MLP。self-attention 和 MLP 层仅应用于视觉 token,而 Cross-Attention 层分别将视觉和文本 token 作为 Q 和 K。如图 2 所示,对于 raster-order 的模型,Transformer 使用 Causal self-attention 根据先前的 token 预测下一个 token,类似于 GPT。对于 random-order 的模型,masked token 是可学习的,使用 Bi-directional self-attention 预测这些 masked token,类似于 BERT。
输出 head
-
离散 token:遵循自回归模型的常见做法。输出被一个 “Linear 层+ Softmax” 转换为分类分布。 -
连续 token:应用 6 层轻量级 MLP 作为 Diffusion head 来建模每个 token 的分布。该头部的嵌入维度与 Transformer Backbone 相同。每个 token 扩散过程遵循 MAR。噪声 schedule 余弦形状,训练时 1000 步。推理时被重新采样到 100 步。
1.3 实验设置
数据集
使用 WebLI (Web Language Image) 数据集,由来自网络的图像-文本对组成,图像质量和文本的相关性得分很高。默认情况下,图像中心裁剪,调整为 256×256 分辨率。
训练细节
作者使用 2048 的 batch size 训练了 1M iteration,粗略计算了一下,使用的数据集大约有不到 700M。
为了训练 Random-Order 模型,作者按照余弦调度从 [0, 1] 中随机采样 mask ratio,对 image token 进行 mask,类似于 MaskGIT 的做法。
推理细节
遵循 Imagen、Muse 和 Parti 的做法,从文本提示生成图像。对于 Random-Order 模型,使用 64 步来生成余弦 schedule。为了进一步增强生成性能,应用了温度和 CFG。
评价指标
MS-COCO 2014 训练集随机采样 30K 图像上的 Validation Loss,MS-COCO 2014 训练集中的 30K 随机选择的图文对的 FID,以及 GenEval。FID 提供了一个评估生成图像保真度和多样性的指标。另一方面,GenEval 衡量了模型生成准确反映给定提示的图像的能力。对于定性评估,使用模型从多个提示生成图像,并比较生成图像的视觉质量。
1.4 缩放性能
Validation Loss 始终随 model size 呈现出缩放性质。
在图 5 中,作者检查了四个自回归变体在 Validation Loss 方面的缩放行为。可以观察到对数空间中 Validation Loss 和模型大小之间的线性关系。这表明模型大小增加导致 Validation Loss 的改进可以很好地推广到与训练数据不同的数据的验证损失。
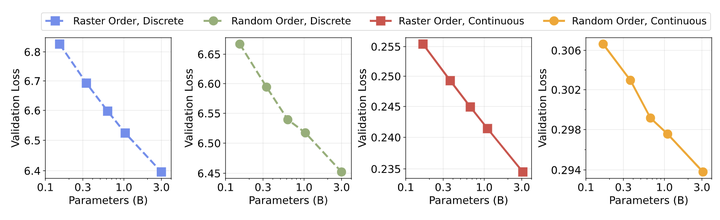
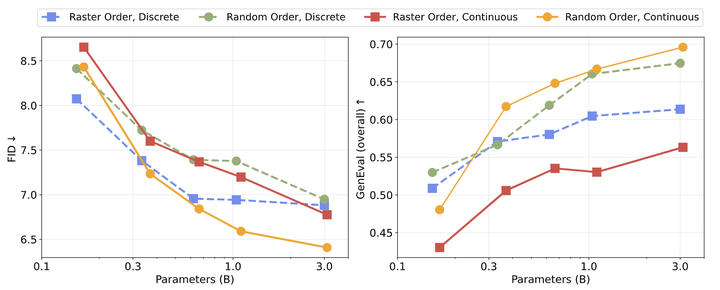
使用连续 token 的 Random-Order 模型在 FID 和 GenEval 分数中表现最佳。
图 6 中作者分析了四个自回归变体在 FID 和 GenEval 方面的缩放行为。作者发现:Validation loss 上观察到的幂律缩放行为没法直接转化为 FID 和 GenEval 的缩放,说明这两个指标和模型大小之间暂时没观察到严格的幂律关系。那么就这四种设置本身,使用离散 token 的 Raster-Order 模型在 FID 和 GenEval 上表示出了平台 (1B 参数左右)。而且,使用连续 token 的 Random-Order 模型实现了最佳的整体性能。
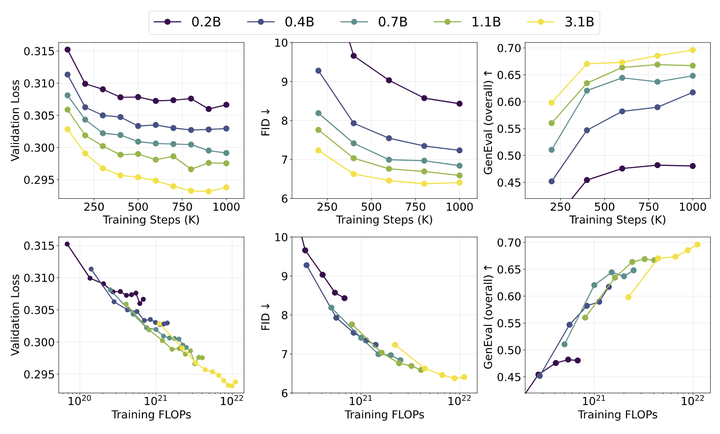
使用离散 token 的 Raster-Order 模型随 training compute 缩放。
图 7 将 Validation Loss、FID 和 GenEval 分数绘制为 Training Steps 和 Training FLOPs 的函数。作者观察到随着 Training Steps 和 Training FLOPs 的增加,Validation Loss 和评估性能都有一致的改进。然而,额外的 Training Steps 的好处在 1M 步左右饱和,表明为小模型训练更多步的计算效率,相比于大模型较低。
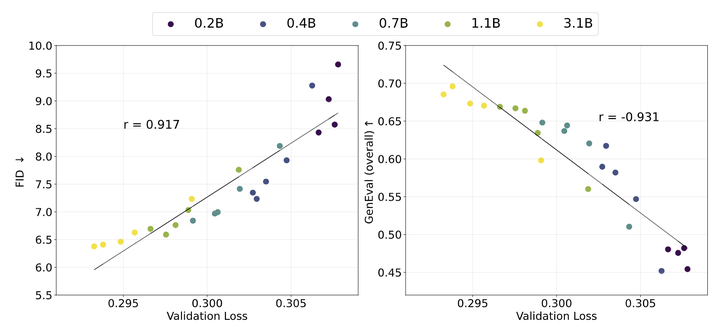
Validation loss 和评估指标之间的强相关性。
图 8 绘制了针对流体不同模型大小的验证损失的 FID 和 GenEval 分数,并观察到强相关性。FID 和 GenEval 分数的 Pearson 相关系数分别为 0.917 和 -0.931,表明 Validation loss 与这些评估指标在模型尺寸为 150M 到 3B 之间几乎呈现线性关系。基于这个现象,作者训练了一个 10.5B 参数的模型,使用 4096 的 batch size,训练了 1M 步。
连续 token 和大模型对视觉质量至关重要。
图 9 比较了四种自回归变体生成的图像的视觉质量。使用离散 token 的模型的视觉质量明显低于使用连续 token 的模型,且放大并不能解决这个问题。这种限制主要是由于离散 tokenizer 引入了大量的信息丢失。相比之下,具有连续 token 的模型会产生更高质量的图像。
此外,较大的模型在视觉质量和图像-文本对齐方面都显示出一致的改进。

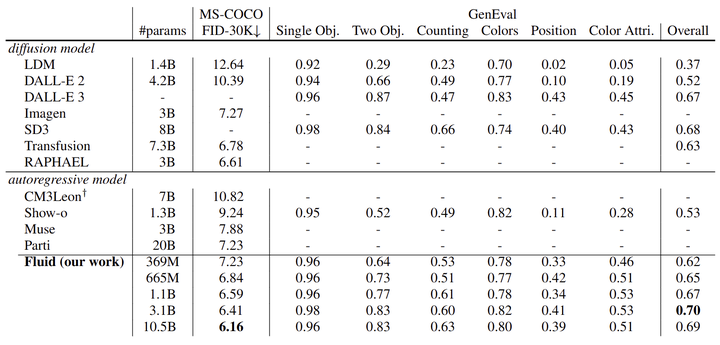
图 10 对比了 Fluid 与领先文生图像模型,是一个系统级的比较。Fluid 的最小模型有 369M 参数,在 MS-COCO 上实现了 7.23 的 zero-shot FID 和 0.62 的 GenEval 分数。Fluid 的最大模型参数为 10.5B,进一步将 MS-COCO 上的 zero-shot FID 提高到 6.16,并将 GenEval 分数提高到 0.692。这里一个有意思的观察是,随着模型从 3.1B 增加到 10.5B,GenEval 分数没继续提高,但是 FID 和视觉质量更好了。
(文:极市干货)