


最近,由 Anthropic 推出的 Computer Use 利用基于多模态大模型的智能体操控电脑完成各种任务,让人们为之兴奋,也带动了学术界与工业界在 OS Agents 相关领域的研究与发展。
浙江大学联合 OPPO、零一万物等十个机构共同梳理了 OS Agents 的发展现状以及未来可能,并形成了一篇综述,旨在推动该领域的持续发展。如下是我们对论文的中文解读,更多细节欢迎访问我们的论文以及开源仓库!

论文标题:
OS Agents: A Survey on MLLM-based Agents for Computer, Phone and Browser Use
论文链接:
https://os-agent-survey.github.io/paper.pdf
仓库链接:
https://github.com/OS-Agent-Survey/OS-Agent-Survey
项目主页:
https://os-agent-survey.github.io/

引言
《钢铁侠》中的贾维斯(J.A.R.V.I.S.)能够帮助托尼·斯塔克控制各种系统并自动完成任务,构建一个像这样的超级 AI 助手一直是人类长期以来的梦想。我们把这一类实体称为 OS Agents,它们能够通过操作系统(OS)提供的环境和接口(如图形用户界面,GUI)在诸如电脑或者手机等计算设备上自动化的完成各类任务。
OS Agents 有巨大的潜力改善全球数十亿用户的生活,想象一个世界:在线购物、预订差旅等日常活动都可以由这些智能体无缝完成,这将大幅提高人们的生活效率和生产力。过去,诸如 Siri [1]、Cortana [2] 和 Google Assistant [3] 等 AI 助手,已经展示了这一潜力。
然而,由于模型能力在过去较为有限,导致这些产品只能完成有限的任务。幸运的是,随着多模态大语言模型的不断发展,如 Gemini [4]、GPT [5]、Grok [6]、Yi [7] 和 Claude [8] 系列模型(排名根据 2024 年 12 月 22 日更新的 Chatbot Arena LLM Leaderboard [9]),这一领域迎来了新的可能性。
(M)LLMs 展现出令人瞩目的能力,使得 OS Agents 能够更好地理解复杂任务并在计算设备上执行。
基础模型公司和手机厂商近期在这一领域动作频频,例如最近由 Anthropic 推出的 Computer Use [10]、由苹果公司推出的 Apple Intelligence [11]、由智谱 AI 推出的 AutoGLM [12] 和由 Google DeepMind 推出的 Project Mariner [13]。例如,Computer Use 利用 Claude [14] 与用户的计算机直接互动,旨在实现无缝的任务自动化。
与此同时,学术界已经提出了各种方法来构建基于(M)LLM 的 OS Agents。例如,OS-Atlas [15] 提出一种 GUI 基础模型,通过跨多个平台综合 GUI 操作数据,大幅改进了模型对 GUI 的操作能力,提升 OOD 任务的表现。
而 OS-Copilot [16] 则是一种 OS Agents 框架,能够使智能体在少监督情况下实现广泛的计算机任务自动化,并展示了其在多种应用中的泛化能力和自我改进能力。
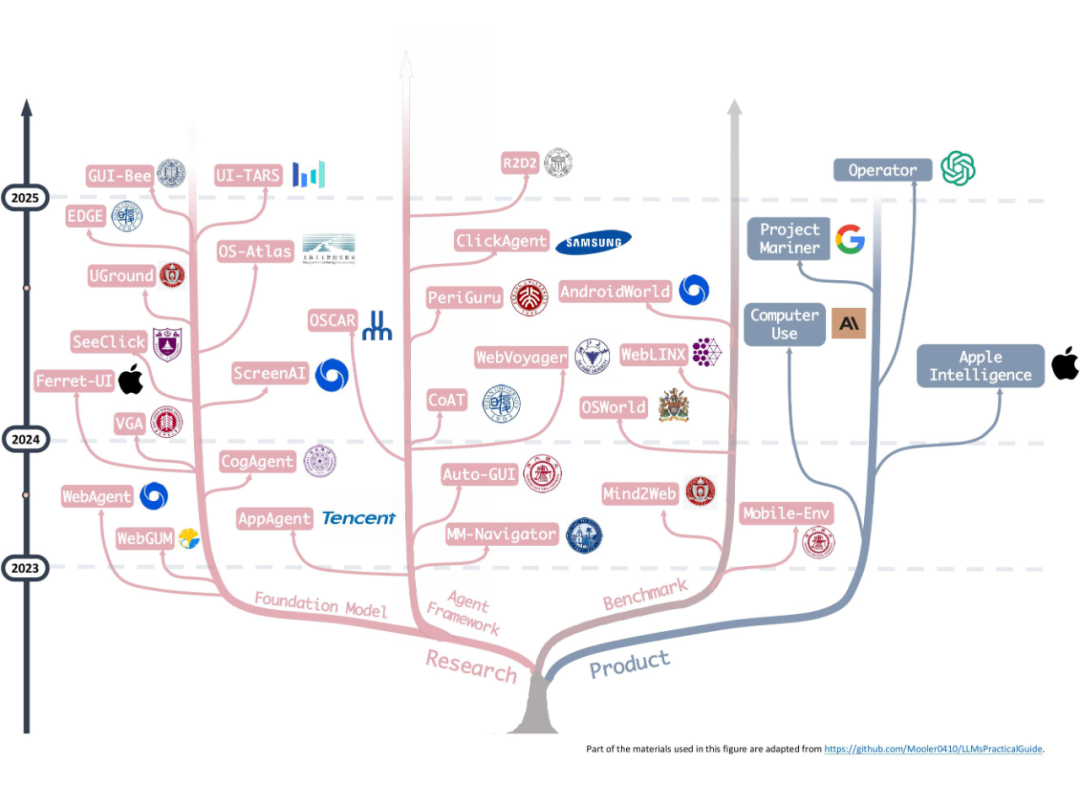
▲ OS Agents 的部分代表性商业产品与学术研究
本文对 OS Agents 进行了全面的综述。首先阐明了 OS Agents 的基础,探讨了其关键要素,包括环境、观察空间和动作空间,并概述了理解、规划和执行操作等核心能力。接着,我们审视了构建 OS Agents 的方法,重点关注 OS Agents 领域特定的基础模型和智能体框架的开发。
随后,本文详细回顾了评估协议和基准测试,展示了 OS Agents 在多种任务中的评估方式。紧接着,本文探讨了 OS Agents 衍生的商业化产品。最后,我们讨论了当前的挑战并指出未来研究的潜在方向,包括安全与隐私、个性化与自我进化。
本文旨在梳理 OS Agents 研究的现状,为学术研究和工业开发提供帮助。为了进一步推动该领域的创新,我们维护了一个开源的 GitHub 仓库,包含 250+ 有关 OS Agents 的论文以及其他相关资源,并且仍在持续更新中,欢迎大家关注。
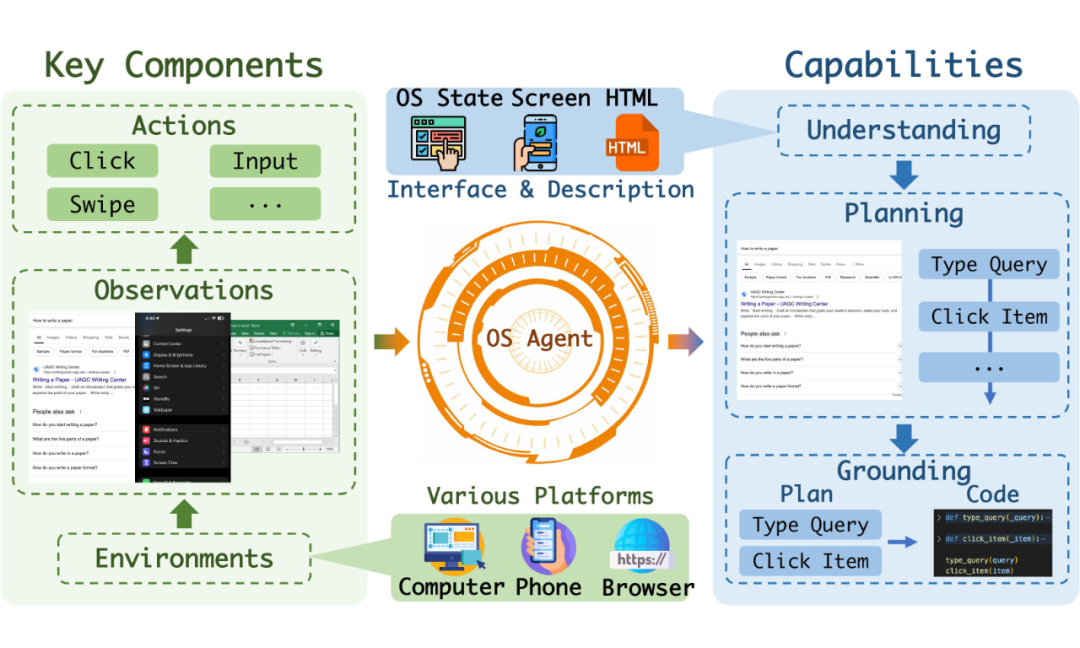
▲ OS Agents 基础:关键要素和核心能力

OS Agents 基础
2.1 关键要素(Key Component)
要实现 OS Agents 对计算设备的通用控制,需要通过与操作系统提供的环境、输入和输出接口进行交互来完成目标。为满足这种交互需求,现有的 OS Agents 依赖三个关键要素:
-
环境(Environment):智能体操作的系统或平台,例如电脑、手机和浏览器。环境是智能体完成任务的舞台,支持从简单的信息检索到复杂的多步骤操作。
-
观察空间(Observation Space):智能体可获取的所有信息范围。这些信息诸如屏幕截图、文本描述或 GUI 界面结构,是智能体理解环境和任务的基础。例如,网页的 HTML 代码或手机的屏幕截图。
-
动作空间(Action Space):智能体与环境交互的动作集合。它定义了可执行的操作,如点击、输入文本、导航操作甚至调用外部工具。这使得智能体能够自动化完成任务并优化工作流。
2.2 核心能力(Capability)
在 OS Agents 的这些关键要素后,如何与操作系统正确、有效的交互,这就需要考验 OS Agents 自身各方面的能力。我们将 OS Agents 必须掌握的核心能力总结为如下三点:
-
理解(Understanding):OS Agents 首先需要理解复杂的操作环境。无论是 HTML 代码、屏幕截图,还是屏幕界面中密集的图标和文本信息,智能体都需要通过理解能力提取关键内容,构建对任务和环境的全面认知。这种理解能力是处理信息检索等任务的前提。
-
规划(Planning):在任务执行中,OS Agents 的规划能力至关重要。规划能力要求 OS Agents 将复杂任务拆解为多个子任务,并制定操作序列来实现目标。同时,它们最好还要能够据环境变化动态调整计划,以适应复杂的操作系统环境,例如动态网页和实时更新的用户屏幕界面。
-
操作(Grounding):OS Agents 最终需要将规划转化为具体的、可执行的操作,例如点击按钮、输入文本或调用 API。这种将规划“落地”的能力使得它们能够在真实环境中高效完成任务,并实现从文字描述到操作执行的精准转换。

OS Agents 的构建
3.1 基础模型(Foundation Model)
要构建能够高效执行任务的 OS Agents ,其核心在于开发适配的基础模型。这些模型不仅需要理解复杂的屏幕界面,还要在多模态场景下执行任务。我们在这部分对基础模型的架构与训练策略做了详细归纳与总结:
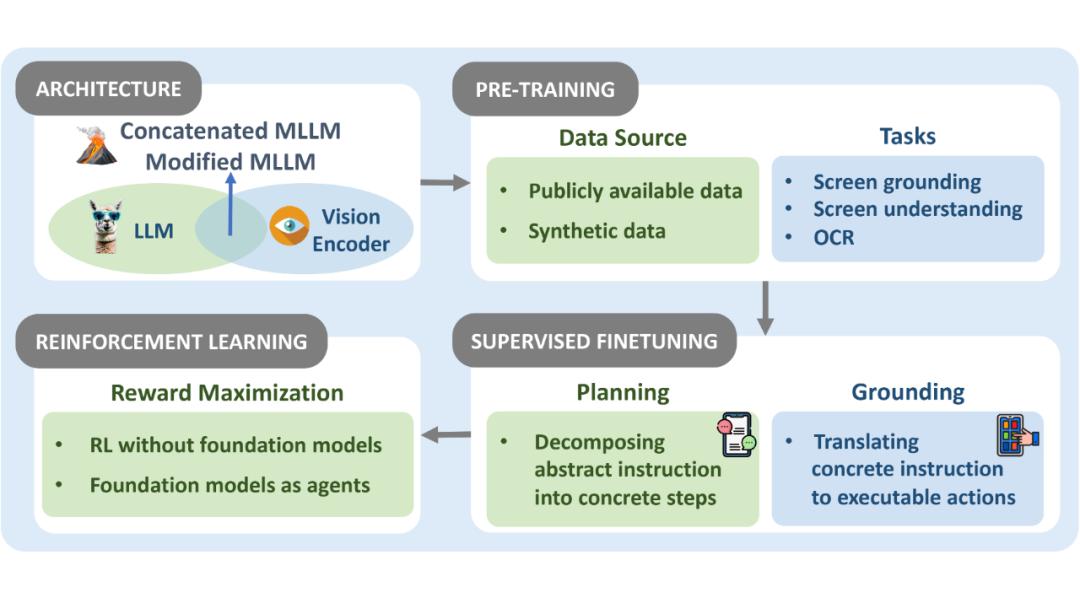
▲ OS Agents 基础模型:架构、预训练、监督微调和强化学习
架构(Architecture):我们将主要的模型架构分为四个类别:
1. Existing LLMs:直接采用开源的大语言模型架构,将结构化的屏幕界面信息以文本形式输入给 LLMs,从而使得模型可以感知环境;
2. Existing MLLMs:直接采用开源的多模态大语言模型架构,整合文本和视觉处理能力,提升对 GUI 的理解能力,减少文本化视觉信息而造成的特征损失;
3. Concatenated MLLMs:由 LLM 与视觉编码器桥接而成,灵活性更高,可以根据任务需求选择不同的语言模型和视觉模型进行组合;
4. Modified MLLMs:对现有 MLLM 架构进行优化调整,以解决特定场景的挑战,如:添加额外模块(高分辨率视觉编码器或图像分割模块等),以更细致地感知和理解屏幕界面细节。
预训练(Pre-training):预训练为模型构建打下基础,通过海量数据提升对屏幕界面的理解能力。数据源包括公共数据集、合成数据集;预训练任务覆盖屏幕定位(Screen Grounding)、屏幕理解(Screen Understanding)与光学字符识别(OCR)等。
监督微调(Supervised Fine-tuning):监督微调让模型更贴合 GUI 场景,是提升 OS Agents 规划能力和执行能力的重要手段。例如,通过记录任务执行轨迹生成训练数据,或利用 HTML 渲染屏幕界面细节,提升模型对不同 GUI 的泛化能力。
强化学习(Reinforcement Learning):现阶段的强化学习实现了用(M)LLMs 作为特征提取到(M)LLM-as-Agent 的范式转变,帮助了 OS Agents 在动态环境中交互,根据奖励反馈,不断优化决策。这种方法不仅提升了智能体的对齐程度,还为视觉和多模态智能体提供了更强的泛化能力与任务适配性。
我们将近期的 OS Agents 基础模型相关论文总结如下:
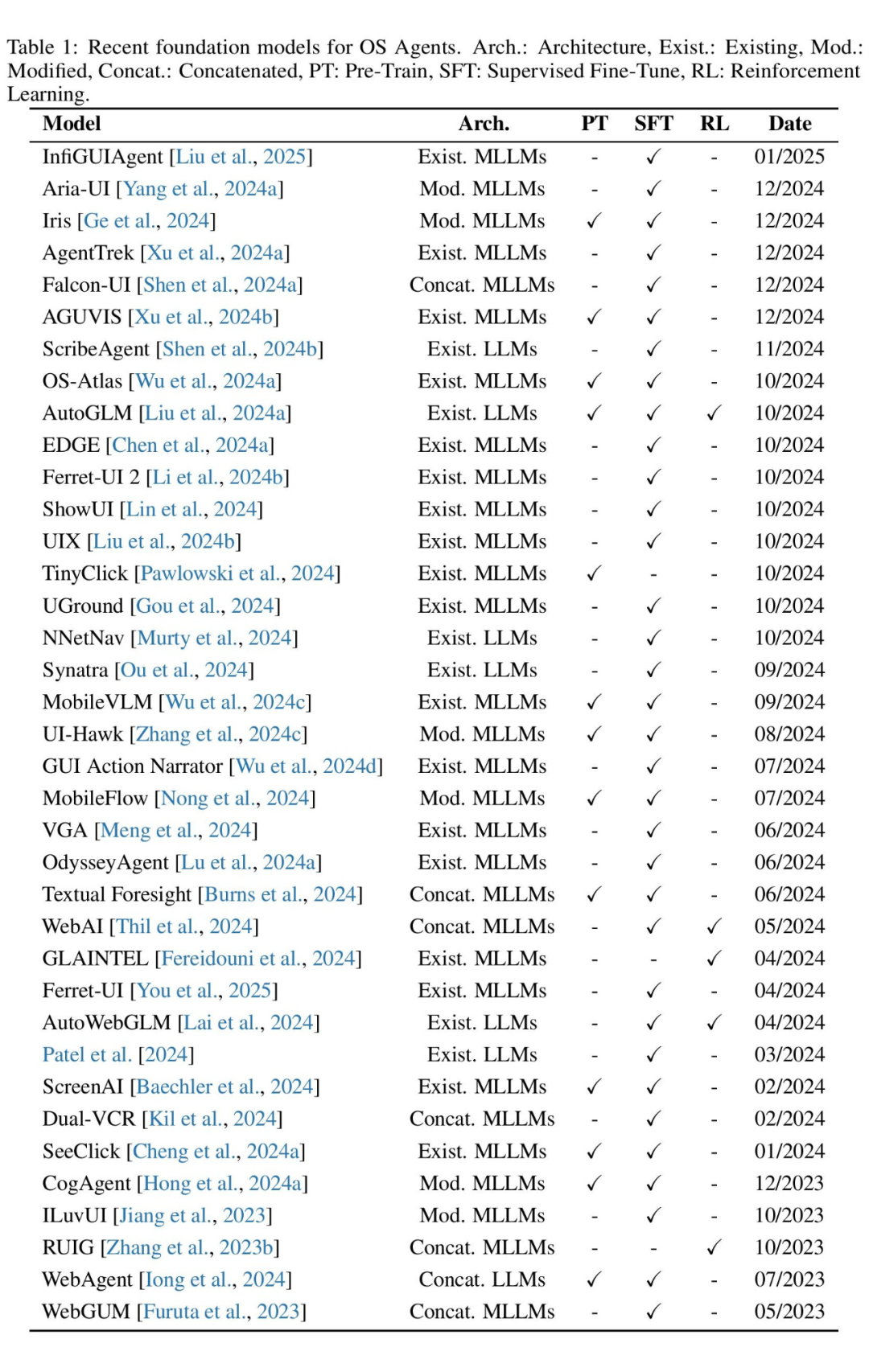
▲ OS Agents 基础模型近期研究工作总结
3.2 智能体框架(Agent Framework)
OS Agents 除了需要强大的基础模型,还需要搭配上 Agent 框架来增强感知、规划、记忆和行动能力。这些模块协同工作,使 OS Agents 能够高效应对复杂的任务和环境。以下是我们对 OS Agents 框架的四大关键模块的总结归纳:
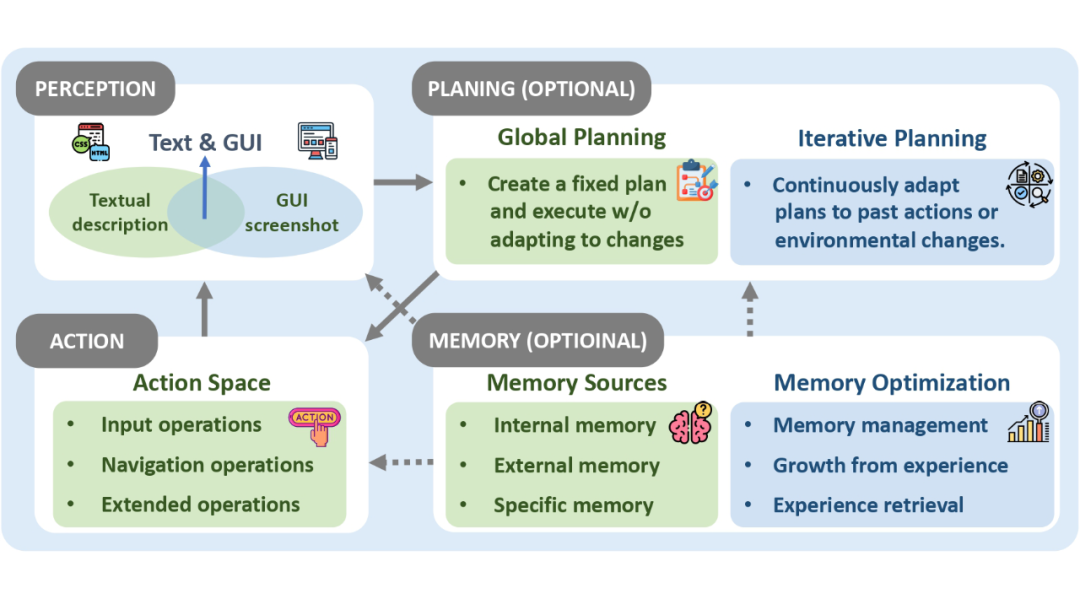
▲ OS Agents 框架:感知、规划、记忆和行动
感知(Perception):感知作为OS Agents 的“眼睛”,通过输入的多模态数据(如屏幕截图、HTML 文档)观察环境。我们将感知细分为:
1)文本感知:将操作系统的状态转化为结构化文本描述,如 DOM 树或 HTML 文件;
2)屏幕界面感知:使用视觉编码器对屏幕界面截图进行理解,通过视觉定位(如按钮、菜单)和语义连接(如 HTML 标记)精准识别关键元素。
规划(Planning):规划作为 OS Agents 的“大脑”,负责制定任务的执行策略,可以分为:1)全局规划:一次生成完整计划并执行;2)迭代规划:随着环境变化动态调整计划,使智能体能够适应实时更新的屏幕界面和任务需求。
记忆(Memory):OS Agents 框架的“记忆”部分可以帮助存储任务数据、操作历史和环境状态。记忆分为三个类型:
1. 内部记忆(Internal Memory):存储操作历史、屏幕截图、状态数据和动态环境信息,支持任务执行的上下文理解和轨迹优化。例如,借助截图解析屏幕界面布局或根据历史操作生成决策;
2. 外部记忆(External Memory):提供长期知识支持,例如通过调用外部工具(如 API)或知识库获取领域背景知识,辅助复杂任务的决策;
3. 特定记忆(Specific Memory):聚焦于特定任务的知识和用户需求,例如存储子任务分解方法、用户偏好或屏幕界面交互功能,提供高度针对性的操作支持。此外,我们还总结了多种记忆优化策略。
行动(Action):我们将 OS Agents 的行动范围定义为动作空间,这包含操作系统交互的方式,我们将其细分为三个类别:
1. 输入操作:输入是 OS Agents 与数字屏幕界面交互的基础,主要包括鼠标操作、触控操作和键盘操作;
2. 导航操作:使 OS Agents 能够探索和移动于目标平台,获取执行任务所需的信息;
3. 扩展操作突破了传统屏幕界面交互的限制,为智能体提供更灵活的任务执行能力,例如:代码执行与API 调用。
同时,我们总结了近期有关 OS Agents 框架的论文:
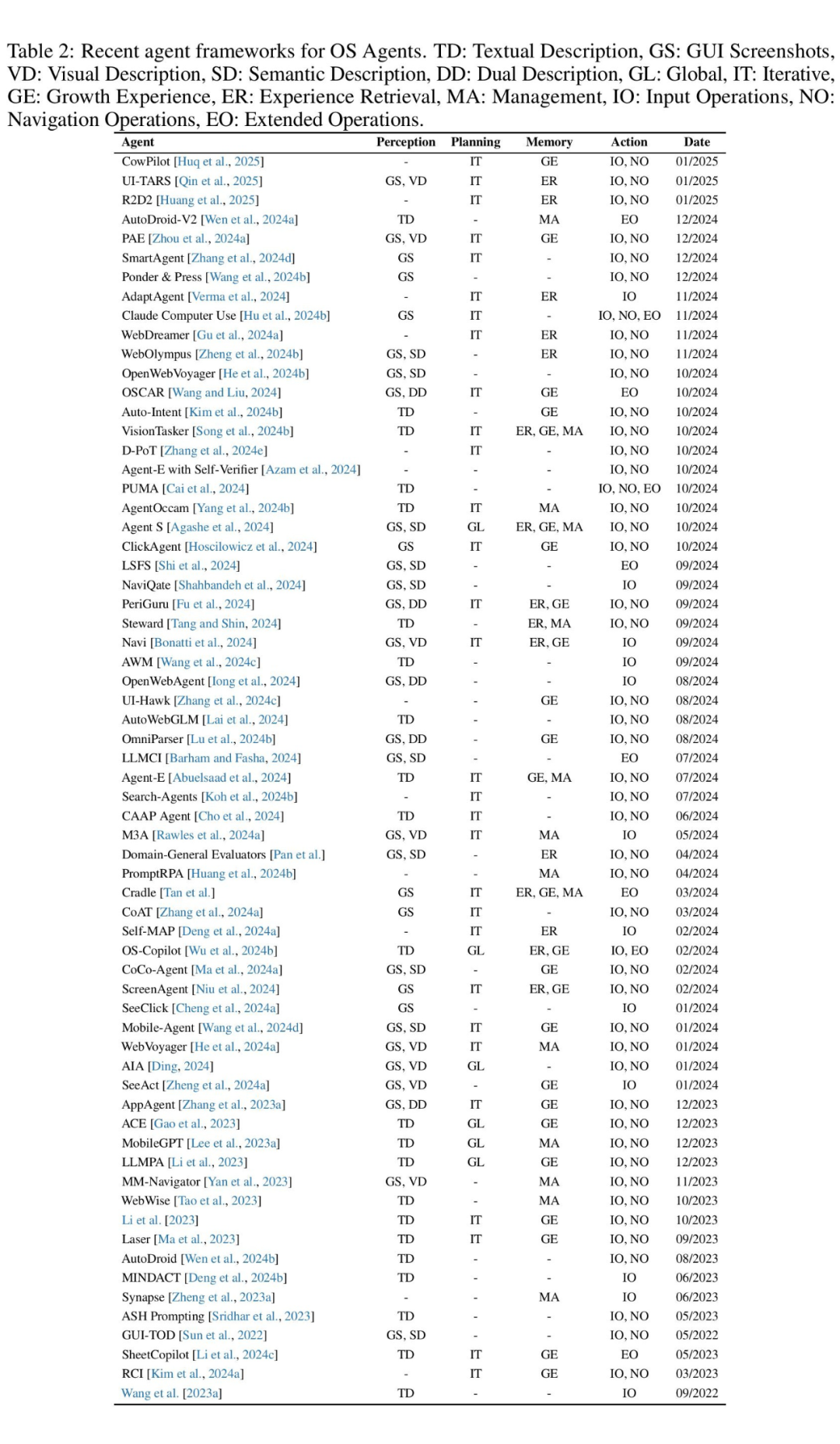
▲ OS Agents 框架近期研究工作总结

OS Agents 的评估
在 OS Agents 的发展中,科学的评估起到了关键作用,帮助开发者衡量智能体在各种场景中的性能。如下表格包含我们对近期有关 OS Agents 评估基准论文的总结:
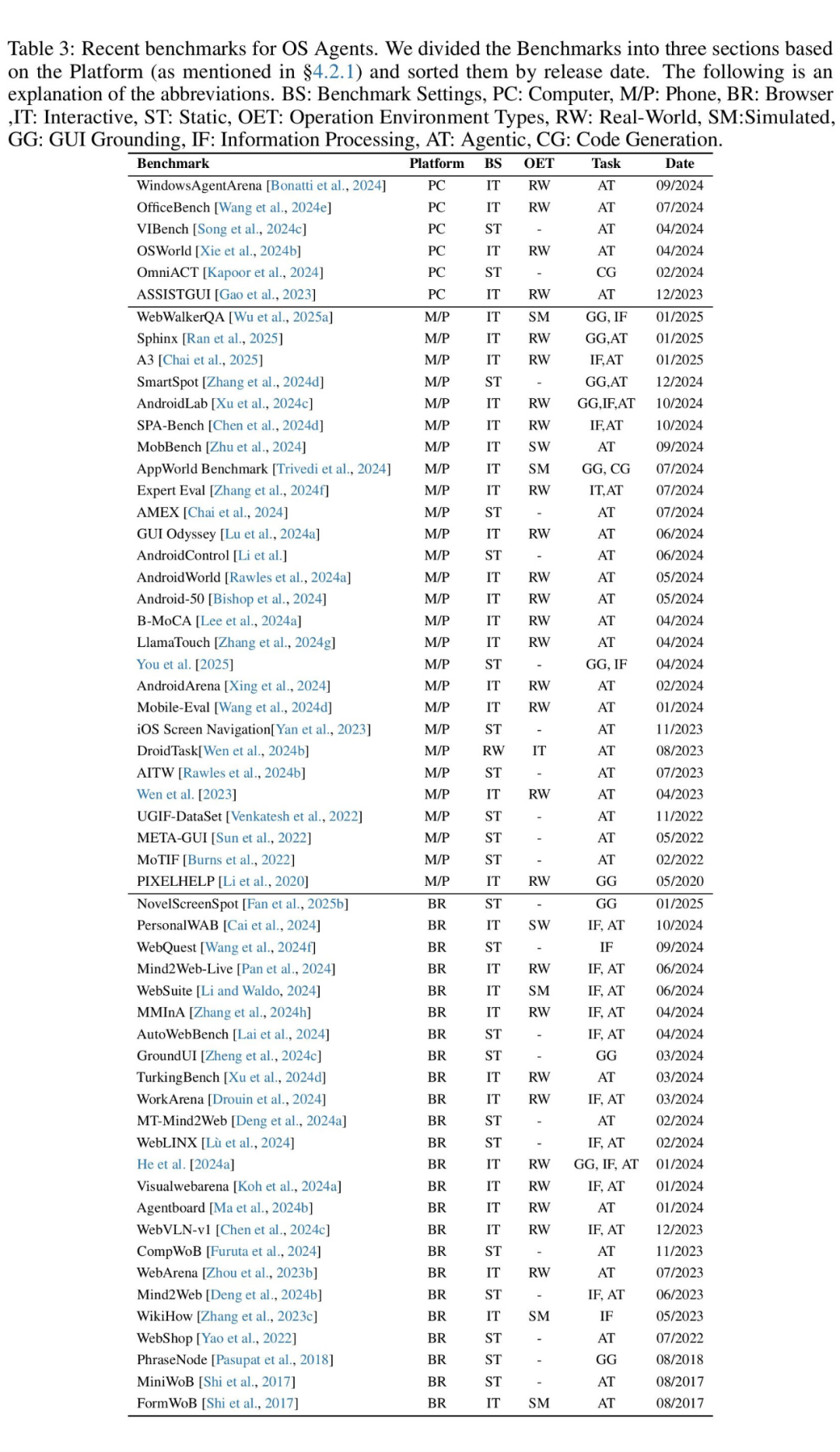
▲ OS Agents Benchmark 近期研究工作总结
4.1 评估协议(Evaluation Protocol)
OS Agents 评估的核心可总结为两个关键问题:评估过程应如何进行与需要对哪些方面进行评估。下面我们将围绕这两个问题,阐述 OS Agents 的评估原则和指标。
评估原则(Evaluation Principle):OS Agents 的评估结合了多维度的技术方法,提供对其能力与局限性的全面洞察,主要分为两种类型:
1. 客观评估(Objective Evaluation):通过标准化的数值指标,评估智能体在特定任务中的性能。例如,操作的准确性、任务的成功率以及语义匹配的精准度。这样的评估方法能快速且标准化地衡量智能体的性能;
2. 主观评估(Subjective Evaluation):基于人类用户的主观感受,评估智能体的输出质量,包括其相关性、自然性、连贯性和整体效果。越来越多的研究也利用(M)LLM-as-Judge 来进行评估,从而提高效率和一致性。
评估指标(Evaluation Metric):评估指标聚焦于 OS Agents 的理解、规划和操作能力,衡量其在不同任务中的表现。主要包括以下两个方面:
1. 步骤级指标:评估智能体在每一步操作中的准确性,如任务执行中动作的语义匹配程度、操作准确性等;
2. 任务级指标:聚焦于整个任务完成情况,包括任务的成功率和完成任务的效率。
4.2 评估基准(Evaluation Benchmark)
为了全面评估 OS Agents 的性能,研究者开发了多种评估基准,涵盖不同平台、环境设置和任务类别。这些基准测试为衡量智能体的跨平台适应性、动态任务执行能力提供了科学依据。
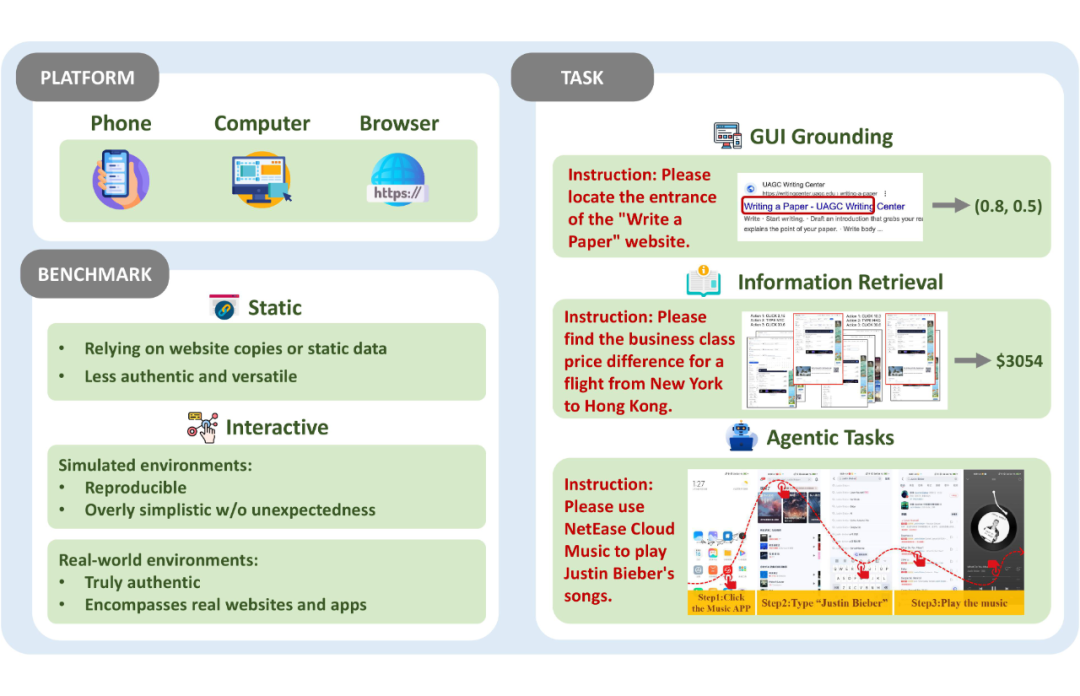
▲ OS Agents 平台、基准与任务分类
评估平台(Evaluation Platform):评估平台构建了集成的评估环境,不同平台具有独特的挑战和评估重点,我们将其主要分为三类:移动平台(Mobile)、桌面平台(Desktop)与网页平台(Web)。
基准设置(Benchmark Setting):该部分将 OS Agents 的评估环境分为两大类:静态(Static)环境和交互式(Interactive)环境,并进一步将交互式环境细分为模拟(Simulated)环境和真实世界(Real-World)环境。
静态环境适用于基础任务的离线评估,而交互式环境(尤其是真实世界环境)更能全面测试 OS Agents在复杂动态场景中的实际能力。真实世界环境强调泛化能力和动态适应性,是未来评估的重要方向。
任务(Task):为了全面评估 OS Agents 的能力,当前的基准测试整合了各种专业化任务,涵盖从系统级任务(如安装和卸载应用程序)到日常应用任务(如发送电子邮件和在线购物)。主要可以分为以下三类:
1. GUI 定位(GUI Grounding):评估 OS Agents 将指令转换为屏幕界面操作的能力,即如何在操作系统中与指定的可操作元素交互;
2. 信息处理(Information Processing):评估 OS Agents 高效处理和总结信息的能力,尤其在动态和复杂环境中,从大量数据中提取有用信息;
3. 智能体任务(Agentic Tasks):评估 OS Agents 的核心能力,如规划和执行复杂任务的能力。这类任务为智能体提供目标或指令,要求其在没有显式指导的情况下完成任务。

OS Agents 相关产品
OS Agent 研究的快速发展和日益增长的兴趣大大加速了该领域商业产品的开发。研究与产品开发之间的相互作用至关重要,因为前沿的学术突破通常是创新商业应用的基础,而现实世界的产品反馈则进一步完善和推动了研究方向。
这种共生关系不仅弥合了理论探索与实际实施之间的差距,而且还确保了 OS Agent 能够不断发展以满足技术和以用户为中心的需求。如下,我们列出了 OS Agent 的最新商业产品。
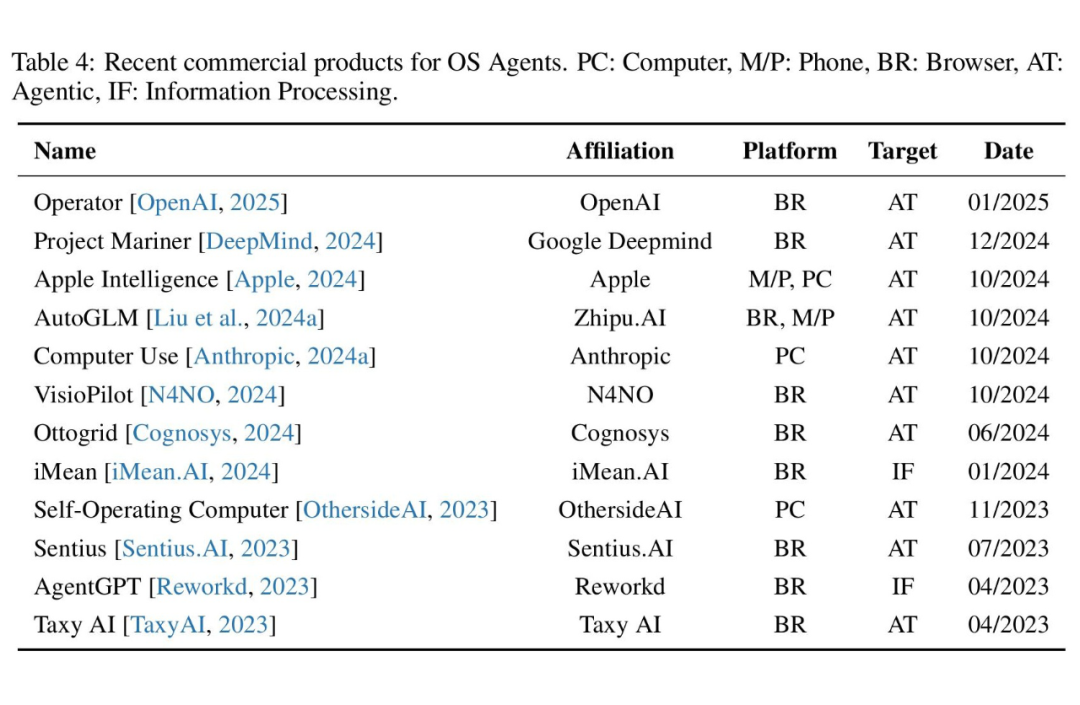
▲ OS Agents 相关商业化产品总结
在过去几年中,OS Agent 产品经历了显著的发展,呈现平台多样化和功能分层的趋势,反映了对更复杂、通用代理解决方案的需求增长。
目前,主流形态可分为三类:基于浏览器的(如 DeepMind 的 Project Mariner 、Taxy AI [20])、基于计算机控制的(如 Anthropic 的 Computer Use、Self-Operating Computer [21])和基于移动系统集成的(如 Apple Intelligence、智普的 AutoGLM [22])。
浏览器产品因其低侵入性而成为早期探索方向,而移动产品则凸显了深度融合趋势,如 Apple Intelligence 和 AutoGLM 通过访问联系人、协同多应用实现场景闭合。
功能上,产品逐渐分化为任务执行型 Agent 和信息处理型工具。前者注重跨平台运营(如 AutoGLM 管理淘宝、微信等,Computer Use 管理 PC 工作流),后者专注垂直信息整合(如 iMean [23] 专注机票比价)。
早期项目主要验证单一功能(如 Self-Operating Computer 的命令行实验),而 2024 年及之后的产品强调多模态交互和系统权限升级(如 Apple Intelligence 对 iOS 通知的深度访问)。
2023 年为技术验证期,初创公司通过浏览器插件或 CLI 工具探索交互框架;2024 年起,领先厂商将代理功能嵌入操作系统底层,标志着 OS Agent 由技术展示向实际生产力转化。

挑战与未来
本部分讨论了 OS Agents 面临的主要挑战及未来发展的方向,我们重点聚焦于安全与隐私(Safety & Privacy)以及个性化与自我进化(Personalization & Self-Evolution)两个方面。
6.1 安全与隐私
安全与隐私是 OS Agents 开发中必须重视的领域。OS Agents 面临多种攻击方式,包括间接提示注入攻击、恶意弹出窗口和对抗性指令生成,这些威胁可能导致系统执行错误操作或泄露敏感信息。
尽管目前已有适用于 LLMs 的安全框架,但针对 OS Agents 的防御机制仍显不足。当前研究主要集中于设计专门应对注入攻击和后门攻击等特殊威胁的防御方案,急待开发全面的且可扩展防御框架,以提升 OS Agents 的整体安全性和可靠性。
为评估 OS Agents 在不同场景下的鲁棒性,还引入了一些智能体安全基准测试,用于全面测试和改进系统的安全表现,例如 ST-WebAgentBench [17] 和 MobileSafetyBench [18]。
6.2 个性化与自我进化
个性化 OS Agents 需要根据用户偏好不断调整行为和功能。多模态大语言模型正逐步支持理解用户历史记录和动态适应用户需求,OpenAI 的 Memory 功能 [19] 在这一方向上已经取得了一定进展。让智能体通过用户交互和任务执行过程持续学习和优化,从而提升个性化程度和性能。
未来将记忆机制扩展到更复杂的形式,如音频、视频、传感器数据等,从而提供更高级的预测能力和决策支持。同时,支持用户数据驱动的自我优化,增强用户体验。

总结
多模态大语言模型的发展为 OS Agents 创造了新的机遇,使得实现先进 AI 助手的想法更加接近现实。在本综述中,我们旨在概述 OS Agents 的基础,包括其关键组成部分和能力。
此外,我们还回顾了构建 OS Agents 的多种方法,特别关注领域特定的基础模型和智能体框架。在评估协议和基准测试中,我们细致分析了各类评估指标,并且将基准测试从环境、设定与任务进行分类。
展望未来,我们明确了需要持续研究和关注的挑战,例如安全与隐私、个性化与自我进化等。这些领域是进一步研究的重点。
本综述总结了该领域的当前状态,并指出了未来工作的潜在方向,旨在为 OS Agents 的持续发展贡献力量,并增强其在学术界和工业界的应用价值与实际意义。如有错误,欢迎大家批评指正,也期待各位同行与我们交流讨论!

(文:PaperWeekly)