

射学影像是现代医疗诊断的关键,每年全球约有 80 亿次影像检查。随着 AI 技术的快速发展,医学视觉语言模型 (VLM) 在放射学任务中显示出良好的前景,但大多数现有的 VLM 仅产生最终答案而不展示底层推理。
然而,医学推理在临床应用中扮演着至关重要的角色。一方面,医生对于 AI 诊断结果的「可理解、可追溯」有着强烈需求;另一方面,监管部门也往往更关注模型输出的透明度,以确保临床安全性和合规性。
然而,当前大多数医学视觉语言模型往往只输出最终答案或「伪解释」,缺少完整推理链条,难以获得信任。因此,如何既保持高准确率,又能为医生和监管部门提供透明可信的推理过程,一直是摆在医疗 AI 面前的重大挑战。
为了弥补这一差距,慕尼黑工业大学(Technische Universität München,TUM)、牛津大学(University of Oxford)、帝国理工学院(Imperial College London)、麻省总医院(Massachusetts General Hospital)、谢菲尔德大学(University of Sheffield)的合作团队推出了 MedVLM-R1,一款在关注提供高准确率的同时,具备明确自然语言推理能力的医学视觉语言模型。
通过采用 DeepSeek 的强化学习框架,激励模型在不使用任何推理参考的情况下发现人类可解释的推理路径。它在仅有 600 个视觉问答(VQA)样本、2B 参数规模的轻量级条件下,在 MRI、CT 和 X 射线基准测试中的准确率从 55.11% 提高到了 78.22% 准确率,远超在大规模数据上训练的同类大模型,为可解释的医学影像分析开辟了新思路。
通过将医学图像分析与显式推理相结合,MedVLM-R1 标志着迈向临床实践中值得信赖和可解释的 AI 的关键一步。
该研究以「MedVLM-R1: Incentivizing Medical Reasoning Capability of Vision-Language Models (VLMs) via Reinforcement Learning」为题,于 2025 年 2 月 26 日发布在 arXiv 预印平台。推理模型已开源在 huggingface 平台。

论文标题:
MedVLM-R1: Incentivizing Medical Reasoning Capability of Vision-Language Models (VLMs) via Reinforcement Learning
论文地址:
https://arxiv.org/abs/2502.19634
模型地址:
https://huggingface.co/JZPeterPan/MedVLM-R1

引言
放射学影像在现代医疗中至关重要,每年会进行超过 80 亿次扫描。随着诊断需求增长,AI 驱动的影像解读需求日益迫切。
医学视觉语言模型(VLMs)在 MRI、CT 和 X 射线影像的视觉问答(VQA)中展现出潜力,可辅助医生和患者,但现有模型多依赖监督微调(SFT),存在过拟合、捷径学习以及对分布外数据(OOD)表现不佳的问题,且仅提供最终答案或「伪解释」,缺乏逐步推理能力,难以满足临床对可解释性和可信度的需求。
强化学习(RL)通过奖励模型自主发现逻辑步骤,显示出优于 SFT 的泛化能力,但传统RL依赖神经奖励模型,资源消耗大。近日,DeepSeek 推出的群体相对策略优化(GRPO)通过规则化策略减少计算需求,在资源有限的医疗领域具有潜力,但尚未得到充分探索和应用。
在最新的研究中,研究人员提出了 MedVLM-R1,这是第一个能够通过使用 DeepSeek GRPO 技术进行训练来生成具有明确推理的答案的医学 视觉语言模型,可用于放射学 VQA 任务。
主要贡献如下:
具有明确推理的医学 VLM:他们推出了 MedVLM-R1,这是第一个轻量级医学 VLM,能够在最终答案的同时生成明确推理,而不仅仅是提供最终答案。
无需明确监督的新兴推理:与需要具有复杂推理步骤的数据的传统 SFT 方法不同,MedVLM R1 使用 GRPO 和仅包含最终答案的数据集进行训练,展示了无需明确监督的新兴推理能力。
卓越的泛化能力和效率:MedVLM-R1 实现了对分布外数据(例如 MRI → CT/X 射线)的稳健泛化,并且尽管是一个仅在 600 个样本上训练的紧凑型 2B 参数模型,但它的表现优于 Qwen2VL-72B 和 Huatuo-GPT-Vision-7B 等更大的模型。


总体表现
下表总结了各种 VLM 的域内 (ID) 和域外(OOD)性能。ID/OOD 专门指在 MRI 数据上微调的模型。
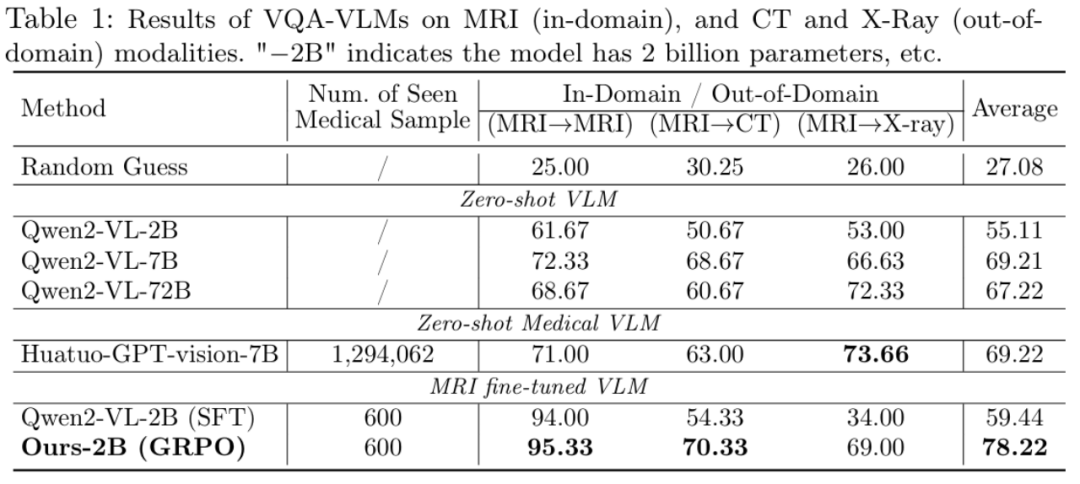
比较结果显示,使用 GRPO 和 SFT 微调的 VLM 在域内任务上的表现明显优于零样本通用 VLM。团队的 GRPO 训练模型表现出非常强大的 OOD 性能,与 SFT 同类模型相比,CT 图像提高了 16%,X 射线图像提高了 35%,凸显了 GRPO 卓越的通用性。
此外,尽管 MedVLM-R1 是一个仅使用 600 个样本进行训练的紧凑型 2B 参数模型,但它的表现优于 Qwen2-VL-72B 和 HuatuoGPT-Vision-7B 等大型模型,后者专门针对大规模医疗数据进行训练。这凸显了基于 RL 的训练方法在高效且可扩展的医疗 VLM 开发方面的巨大潜力。

推理能力和可解释性
除了强大的泛化能力之外,MedVLM-R1 的核心优势在于它能够产生明确的推理能力——这是所有基线所不具备的能力。如下图所示,MedVLM-R1 在标签内呈现了一个逻辑思维过程,最终决策包含在标签中。
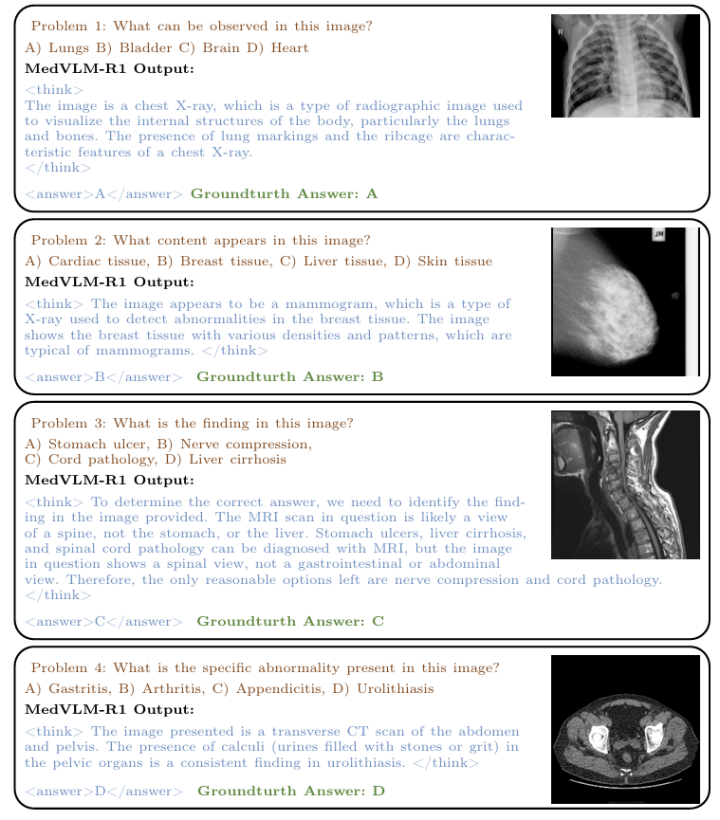
值得注意的是,对于相对较简单的问题(问题 1 和 2),推理似乎很有说服力,并且与医学知识相符。然而,更复杂的查询有时会显示启发式或只是部分推理。
例如,在第三个样本中,模型通过排除法而不是详细的医学分析得出了正确答案,这表明它利用了基于线索的推理,而不是领域专业知识。
同样,在某些情况下(例如问题 4),推理和结论之间的因果关系仍然不清楚,这引发了一个问题:模型是否只是在预测正确答案后编造了相对应的解释。尽管存在这些缺陷,但 MedVLM-R1 代表了放射学决策可解释性方面迈出的显著一步。

局限性
尽管 MedVLM-R1 在 MRI、CT 和 X 射线数据集中表现出色,但仍存在一些局限性:
1. 模式差距:在其他医学模式(例如病理学或 OCT 图像)上进行测试时,该模型无法收敛。研究人员假设这是由于基础模型在预训练期间对这些模式的接触不足造成的。
2. 封闭集依赖性:当前方法适用于多项选择(封闭集)VQA。在没有提供预定义选项的开放式问题设置中,模型的性能会大幅下降。这也是许多 VLM 面临的共同挑战。
3. 肤浅/幻觉推理:在难度较大的任务推理任务中,MedVLM-R1有时仍能 提供正确答案,但仅仅会提供肤浅的推理过程(例如,“思考:让我们来看一下这张核磁共振图片。 答案:A。”)。
此外在这些难度较大的任务中,模型推理得出的结论可能会与最终给出的答案自相矛盾。这种现象说明,即使是为可解释性而设计的模型有时也会出现肤浅/幻觉的论证,凸显了在生成始终透明且合乎逻辑的合理性方面仍然存在挑战。
关于所有这些问题,团队认为他们基础模型的当前 2B 参数规模构成了潜在的瓶颈,接下来计划在更大的 VLM 主干上评估 MedVLM-R1 以解决这些问题。

总结
总之,团队提出了 MedVLM-R1,一种集成了基于DeepSeek GRPO 的强化学习的医学 VLM,用于弥合放射学 VQA 中准确性、可解释性和稳健性能之间的差距。通过专注于显式推理,该模型提高了透明度和可信度——这些能力在高风险临床环境中必不可少。
他们的结果表明,基于 强化学习的方法比纯 SFT 方法具有更好的泛化能力,尤其是在 OOD 设置下。虽然基于 视觉语言模型 的医学推理仍处于起步阶段并面临相当大的挑战,但研究人员相信,它在提供更安全、更透明的医疗解决方案的潜力会受到行业的重视并应受行业的到鼓励。
(文:PaperWeekly)