

本文第一作者为邓慧琳,中国科学技术大学硕博连读四年级,研究方向为多模态模型视觉理解、推理增强(R1强化学习)、异常检测。在TAI、TASE、ICCV等期刊和顶会发表论文。
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。
然而,这些成就主要依赖于大规模模型扩展(>32B 参数),这在资源受限的环境中造成了显著的部署障碍。因此,如何通过有效的后训练(post-training)范式来缩小小规模多模态模型与大规模模型之间的性能差距,是亟待解决的问题。
目前,VLM 的主流训练方法是监督微调(SFT),即使用人工标注或 AI 生成的高质量数据对模型进行有监督训练。但这种方法在小模型上存在两个关键问题:
-
域外泛化能力不足(Out-of-Domain generalization collapse):容易过拟合训练数据,在未见过的场景时性能显著下降。
-
推理能力有限(shallow reasoning abilities):倾向于浅层模式匹配,而非真正的理解和推理。这导致模型虽能应对相似问题,但难以处理需要深度思考的复杂问题。
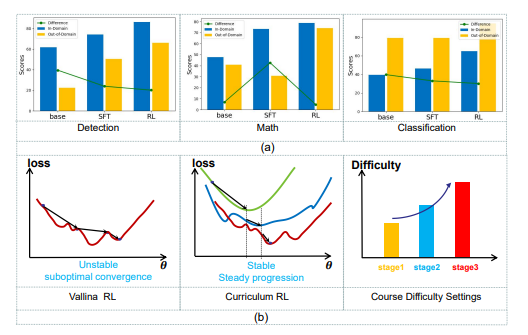
图 1. 实验结果分析。 (a) SFT 与 RL 方法性能对比:通过对比域内和域外性能,实验证实了强化学习方法在各类视觉任务中具有更强的 OOD 泛化能力。 (b) “砖墙”现象分析:在小规模 VLMs 中观察到:面对复杂样本时出现训练不稳定性,模型最终收敛到次优解。我们提出的课程强化学习方法采用难度感知的奖励设计,确保模型能力从基础任务到复杂推理任务的稳步提升。
通过系统实验,我们发现基于强化学习的训练方法在提升模型域外泛化性方面具有独特优势。
然而,在实践中我们观察到一个显著的「砖墙」(Brick Wall)现象:小规模模型在简单任务上快速进步,但在复杂任务上遇到瓶颈,甚至导致已掌握能力的退化。这种现象表现为训练过程的剧烈震荡,最终导致模型收敛到次优解。
为突破这一瓶颈,我们从课程学习(Curriculum Learning, CL)中汲取灵感。课程学习是一种将模型逐步暴露于递增复杂任务的训练策略。我们提出了课程式强化学习后训练范式(Curr-ReFT),确保模型能力从基础任务到复杂推理任务的稳步提升。
这一创新方法能够帮助小型 VLMs 突破性能瓶颈,在保持部署友好性的同时,实现与大规模模型相媲美的推理能力。

-
论文标题: Boosting the Generalization and Reasoning of Vision Language Models with Curriculum Reinforcement Learning
-
论文链接:https://arxiv.org/pdf/2503.07065
-
开源链接:
-
https://github.com/ding523/Curr_REFT(代码)https://huggingface.co/datasets/ZTE-AIM/Curr-ReFT-data(数据)https://huggingface.co/ZTE-AIM/3B-Curr-ReFT(模型权重)https://huggingface.co/ZTE-AIM/7B-Curr-ReFT(模型权重)
工作概述
在中小尺寸多模态大模型上,我们成功复现了 R1,并提出了一种创新的后训练范式 Curr-ReFT。通过结合课程强化学习和基于拒绝采样的自我改进方法,我们显著提升了视觉语言模型(VLM)的推理能力和泛化能力。
理论与实验分析
-
强化学习的重塑能力:我们证明了基于规则的强化学习能够有效重塑多模态/CV 任务的训练方案,从传统的精调转向强化精调。
-
提升推理与泛化能力:实验结果显示,强化学习方法显著提升了 VLM 在分布外数据上的表现。
创新框架
-
Curr-ReFT:我们提出了一种新型后训练范式,结合课程强化学习和自我改进策略。在 Qwen2.5-VL-3B 和 Qwen2.5-VL-7B 模型中验证了其有效性。
全面评估
在多个自建数据集和权威基准测试上进行对比实验,验证了模型的通用表现,结果表明 7B 模型甚至超越了最新的 InternVL2.5-26B 和 38B 模型。
具体方法
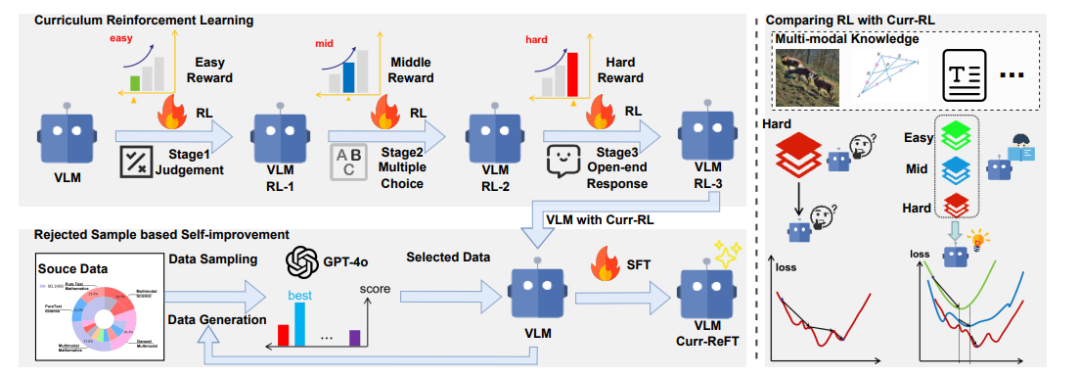
图 2. 所提出的 Curr-ReFT 后训练范式整体框架。Curr-ReFT 包含两个连续的训练阶段:1.课程强化学习:通过与任务复杂度匹配的奖励机制,逐步提升任务难度。2.基于拒绝采样的自我改进:维持 LLM 模型的基础能力。
Curr-ReFT 包含两个连续的训练阶段:
-
课程强化学习:通过难度感知的奖励设计确保模型能力的稳步提升,从基础的视觉感知逐步过渡到复杂的推理任务。
-
基于拒绝采样的自我改进:通过从高质量的多模态和语言样本中进行选择性学习,维持 VLMs 的基础能力。
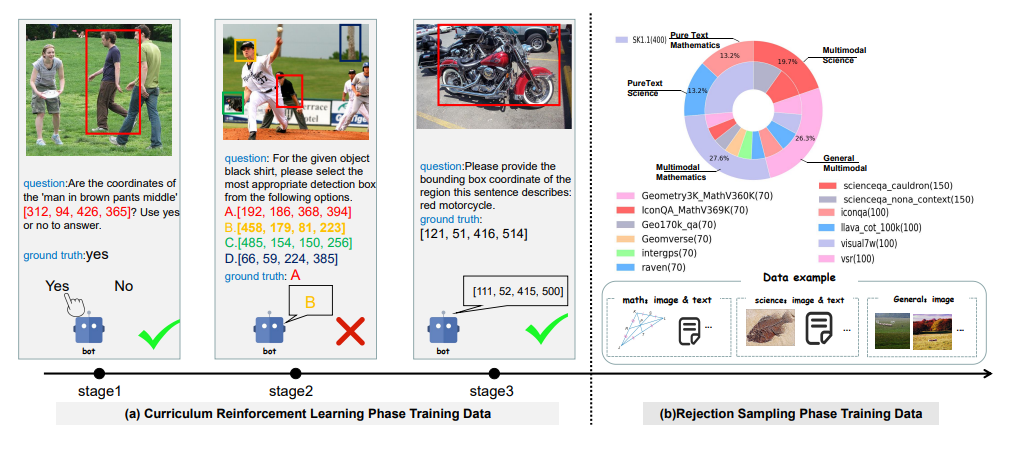
图 3. 训练数据组织架构图。 (a) 课程强化学习的三阶段渐进式响应格式示例。展示了任务从简单到困难的递进过程,呈现不同阶段的响应格式变化。 (b) 拒绝采样 SFT 阶段使用的数据来源分布。
Stage1:课程强化学习(Curriculum Reinforcement Learning)
课程学习(Curriculum Learning,CL)作为一种教学式训练策略,其核心思想是让模型循序渐进地接触复杂度递增的任务。
针对强化学习中普遍存在的训练不稳定性和收敛性问题,我们创新性地将课程学习与 GRPO 相结合,突破了传统基于样本难度评估的局限,转而关注任务层面的渐进式学习。
本研究的关键创新点在于设计了难度感知的奖励机制,该机制与任务的自然进阶路径相匹配,具体包括三个递进阶段:
-
二元决策阶段(Binary Decision) -
多项选择阶段(Multiple Choice) -
开放式回答阶段(Open-ended Response)
这一课程强化学习(Curr-RL)框架通过精确校准任务复杂度对应的奖励机制,成功实现了视觉感知和数学推理任务的稳定优化过程。
Stage2:拒绝采样自我增强(Rejected Sample based Self-improvement)
数据准备过程涉及对综合数据集的系统采样。我们使用 GPT-4-O 作为奖励模型,从多个维度评估生成的响应,评估标准包括:准确性、逻辑一致性、格式规范性、语言流畅度。
所有响应在 0-100 分范围内进行量化评估。得分超过 85 分的响应及其对应的问题会被纳入增强数据集。最终整理的数据集包含 1,520 个高质量样本,涵盖多个领域:数学、科学、通用场景的通用知识。数据分布如下:
-
多模态数据(300 条):
-
Geometry3K_MathV360K(100 条) -
Geo170k_qa(100 条) -
Geomverse(100 条)
-
纯文本数据:
-
SK1.1 数学题(400 条)
-
多模态数据(220 条):
-
Scienceqa_cauldron(100 条) -
Scienceqa_nona_context(120 条)
-
纯文本数据:
-
SK1.1 科学题(100 条)
-
Illava_cot_100k(300 条) -
Visual7w(100 条) -
VSR(100 条)
实验结果
为了验证我们的模型在多模态数学推理任务中的表现,我们进行了广泛的实验,并在多个基准数据集上进行了测试。以下是实验部分的详细介绍:
实验设置
1、 Visual Datasets
我们构建了一个全面的评估框架,涵盖视觉检测、视觉分类和多模态数学推理三个主要任务,以评估强化学习对视觉语言模型的有效性和泛化能力。
-
视觉检测:使用 RefCOCO 和 RefGta 数据集。 -
视觉分类:采用 RefCOCO、RefCOCOg 和 Pascal-VOC 数据集。 -
多模态数学推理:结合 Math360K、Geo170K 和 CLEVER-70k-Counting 数据集。
2、Benchmarks
我们在多个权威基准数据集上评估了模型的表现,包括:
-
MathVisa:综合数学基准。 -
MATH:高中竞赛级别数学问题。 -
AI2D:小学科学图表及相关问题。 -
MMVet 和 MMBench:复杂推理和多模态能力评估。
实验结果
我们展示了使用课程强化微调(Curr-ReFT)训练的模型在多模态任务上的显著性能提升,特别是在跨领域泛化能力和复杂推理任务方面。
与传统的监督微调(SFT)方法相比,我们的方法不仅提高了准确率,还增强了模型处理未见过的数据的能力。以下表格展示了不同训练方法在域内和域外数据集上的性能对比。具体包括传统监督微调(SFT)和强化学习(RL)两种方法:
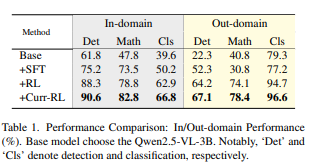
通过这些实验结果可以看出,强化学习训练(RL)方法在提高模型的域内和域外表现方面具有显著优势,尤其是在处理未见过的数据时,能够保持较高的准确率。
Visual Datasets 上不同方法模型的测试结果如下:
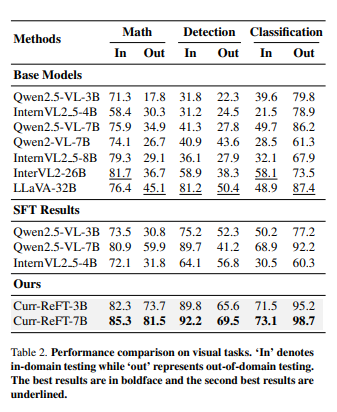
为了验证 Curr-ReFT 的泛化性以及使用后不会削弱模型在其他领域的推理能力,我们在多模态领域多个 Benchmark 数据集上进行验证。Benchmarks 上不同方法模型的测试结果如下(评测集裁判模型使用 GPT-3.5):
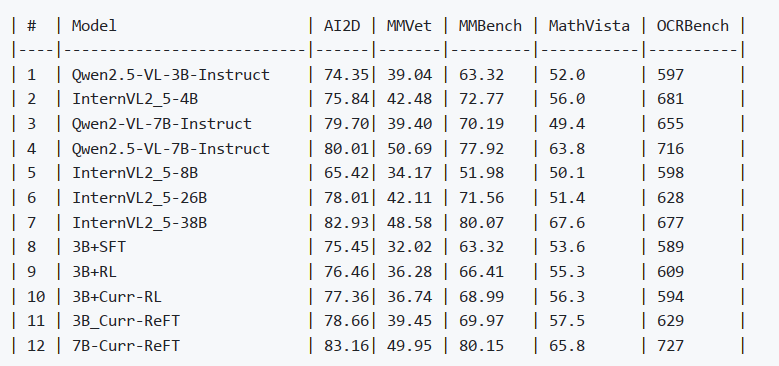
总结
本研究聚焦于提升小规模视觉-语言模型(VLMs)在推理能力和域外(OOD)泛化性能两个关键方面的表现。通过实证研究,我们发现强化学习不仅能有效提升模型的推理能力,更在视觉任务中展现出超出预期的泛化性能提升。
基于这一重要发现,我们提出了创新性的课程式强化学习微调(Curr-ReFT)后训练范式。该方法巧妙地融合了渐进式课程学习与拒绝采样策略。Curr-ReFT 通过两个关键机制:
-
任务复杂度的渐进式提升 -
高质量样本的选择性学习 成功实现了模型性能的显著提升。

©
(文:机器之心)