
ICCV’25 视觉Token跳起来!上交大×蚂蚁联手推出多模态通用加速框架
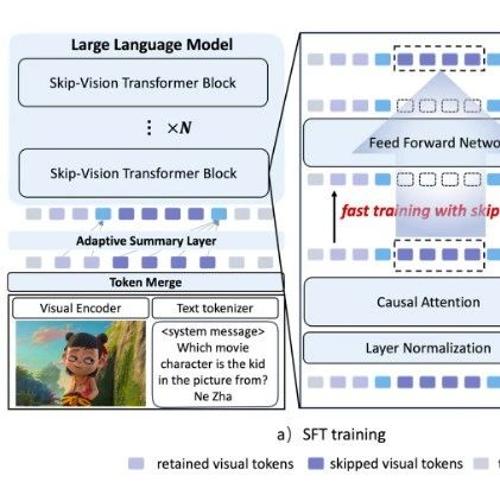
近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,该框架通过训练阶段的Skip-FFN和推理阶段的Skip KV-Cache机制减少视觉Token的冗余计算与保留关键信息,实现多模态模型在精度和效率上的双重优化。
近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,该框架通过训练阶段的Skip-FFN和推理阶段的Skip KV-Cache机制减少视觉Token的冗余计算与保留关键信息,实现多模态模型在精度和效率上的双重优化。

近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,无需额外预训练或重新训练大模型,在SFT流程中插入即可加速视觉-语言模型。该框架通过跳过冗余视觉Token和使用Summary Token机制在保留理解能力的同时显著降低计算开销和延迟。
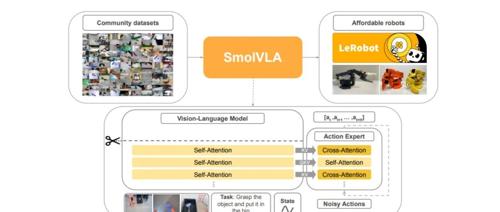
SmolVLA 是 Hugging Face 开源的一个轻量级视觉-语言-行动模型,专为经济高效的机器人设计。它拥有4.5亿参数,能够在消费级GPU甚至CPU上运行,支持在MacBook等设备上部署。通过多模态输入处理、高效推理和异步执行特性,在物体抓取与放置、家务劳动和货物搬运等多种应用场景中表现出色。

文章讨论了自变量机器人如何通过统一模态架构,实现具身多模态推理能力。该架构消除视觉、语言和行动之间的人为边界,并采用生成模型进行跨模态学习,最终让机器人具备符号-空间推理、物理空间推理及自主探索与协作的能力,接近人类的直觉操作方式。
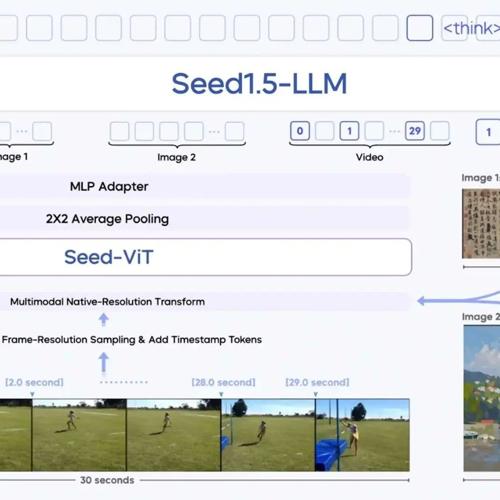
Seed1.5-VL是专为通用多模态理解和推理设计的视觉-语言基础模型,仅用5.32亿视觉编码器和200亿参数的MoE LLM实现顶尖性能,在60个公共基准测试中有38项达到最佳水平。

CMU 和 Google DeepMind 的研究提出了一种名为 ICAL 的方法,通过使用低质量数据和反馈来生成有效的提示词,改善 VLM 和 LLM 从经验中提取见解的能力,从而解决高质量数据不足的问题。

本文介绍了上海科技大学 YesAI Lab 在 NeurIPS 2024 发表的工作《Federated Learning from Vision-Language Foundation Models: Theoretical Analysis and Method》。研究针对视觉-语言模型在联邦学习中的提示词微调提出理论分析框架,引入特征动力学理论并设计了PromptFolio机制,在平衡全局与个性化提示词的同时提升性能。
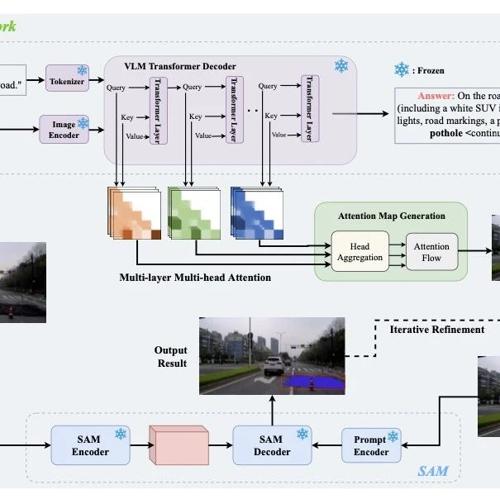
北大团队提出VL-SAM,结合视觉-语言模型和Segment-Anything模型,通过注意力图作为提示解决开放式物体检测与分割任务,性能在LVIS和CODA数据集上良好。

