


近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队创新性地提出一种通用的视觉-语言模型加速框架 Skip-Vision。
该框架不需要额外的预训练,也不需要重新训练大模型,只需在现有 SFT 流程中插入即可,并能轻松适配 LLaVA、LLaVA-HD、CoS 等多种多模态架构。

项目主页:
https://zwl666666.github.io/Skip-Vision/
论文链接:
https://arxiv.org/abs/2503.21817

技术背景:视觉Token——性能与算力的双刃剑
近年来,视觉-语言模型(Vision-Language Models)在多模态智能领域大放异彩,从图像描述、视觉问答到复杂的多模态推理,都表现出惊人的能力。然而,这种能力背后隐藏着一个日益严峻的算力困境——视觉 Token 过载。
现有 VLM 通常会将一张图像分割成数百甚至上千个视觉 Token,送入多层 Transformer 进行细粒度的特征分析。这种做法在精度上带来了好处,模型能捕捉到细微的纹理、局部结构甚至微小的物体。但与此同时,它也带来了巨大的代价:
-
训练阶段:每一个视觉 Token 都需要在每层 Transformer 的前馈网络(Feed-Forward Network, FFN)与自注意力网络(Self-Attention, SA)中进行运算。这种重复计算让训练的时间与能耗都水涨船高,动辄需要数百小时的 GPU 时间。
-
推理阶段:在生成回答或描述的过程中,模型需要持续维护所有 Token 在各层的 Key-Value 缓存(KV-Cache)。这种全量保留不仅造成了显存的暴涨,也显著增加了每次推理的延迟。以 LLaVA 这类模型为例,处理一张图像的单次推理 FLOPs 可高达 2 千亿,延迟超过 150 毫秒,对实时应用来说代价高昂。
简而言之,视觉 Token 是一把双刃剑——它提升了多模态理解的上限,但也把大模型推向了算力消耗的极限。如何保留理解能力,又能大幅降低训练与推理的开销?这正是 Skip-Vision 要解决的问题。

Skip-Vision核心方法:聪明地“跳过”,精准地“汇总”
Skip-Vision 的提出,就是要解决上述困境,核心理念可以用八个字概括:跳过冗余,汇总精华。它从训练和推理两个维度同时入手,构建了一个端到端的加速框架:
1. 训练阶段:Skip-FFN
Skip-Vision 在训练中最核心的创新,是对 FFN 层的跳过机制(Skip-FFN)。如图 1 所示,我们通过深入观察发现,大量视觉 Token 在 FFN 计算前后几乎没有显著变化。这意味着模型其实在对这些 Token 做重复、低收益的运算。
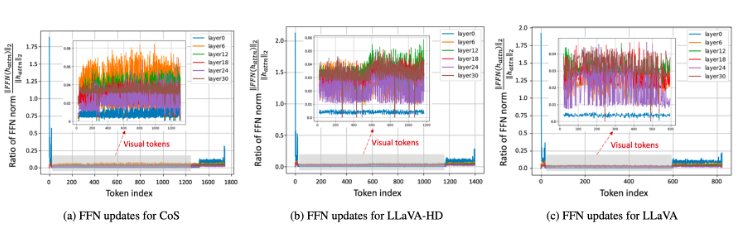
▲ 图1. 我们通过计算 FFN 之前 () 和 FFN 之后 () 的特征模量比来评估 FFN 的影响。与文本 token 相比,FFN 对视觉 token 的更新量明显较小。
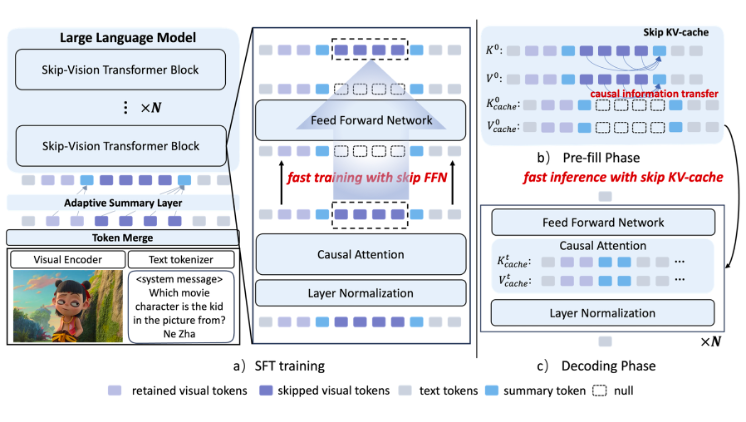
▲ 图2. Skip-Vision 框架图
如图 2 所示,Skip-Vision 会将视觉 token 分成 retained token 与 skipped token,retained token 数量很少,通常会通过 LLM 的所有解码器层,而大量的 skipped token 可以选择性地使用 token merge 进行处理,并被限制只在每个 Transformer 块的自注意层计算,跳过它们的前馈计算。
这不仅减少了训练所需的 FLOPs,还降低了显存占用。如图 3 所示,在实际实验中,这一机制可以帮助 LLaVA 等模型在训练时节省 22%~40% 的训练时间,而性能几乎无损。
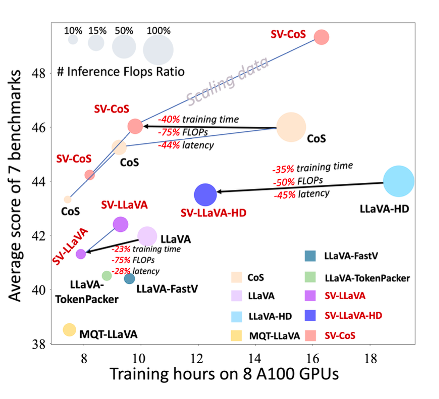
▲ 图3. 性能效率权衡曲线
训练阶段节省下算力只是第一步,Skip-Vision 在推理环节进一步提出 Skip KV-Cache 用于加速推理。
在多模态解码过程中,模型通常需要在 KV-Cache 中保留所有视觉 Token 的历史信息。然而,经过前几层的 Attention 计算后,大部分视觉信息已被整合到少数关键 Token(即 summary token)之中。许多原始 Token 对后续生成几乎不再贡献有效信息。
Skip-Vision 利用这一现象,将被 Skip-FFN 标记的冗余 Token,从 KV-Cache 中彻底剔除。这使得推理 FLOPs 可以降低 40%~75%,端到端延迟减少 18%~45%。
尤其值得注意的是,即便在这样大幅度的裁剪下,模型在诸如 MMBench、MMVet、MMStar 等多项多模态基准测试中,仍能维持与原始全量模型相当的性能。
3. 关键桥梁:Summary Token
仅仅“跳过”是不够的,关键还在于如何保留重要信息。Skip-Vision 提出了 “Summary Token” 机制:在跳过冗余 Token 之前,通过注意力机制先把它们的信息集中到少量 summary token 中,再让这些 summary token 继续参与后续的运算。
这种机制保证了信息流不被中断,避免了因大幅裁剪而带来的理解缺失。
4. 理论保障:误差上界分析
Skip-Vision 不仅是工程上的技巧,更有严格的理论支撑。论文中,我们通过对 transformer 的计算流进行分析,推导了 Skip-FFN 的误差上界。
分析表明,在对模型谱范数进行一定假设下,理论误差是可控的,与实际测量高度一致。这意味着,Skip-Vision 的加速不仅实用,而且可靠。
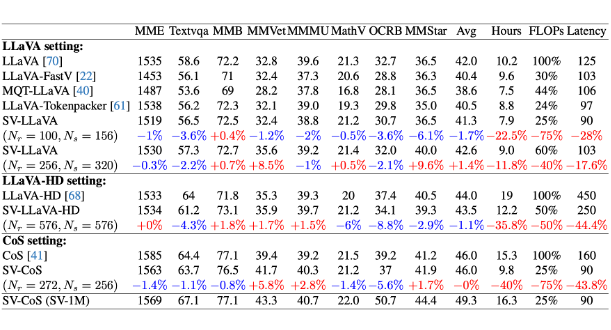
▲ 表1. 性能与效率评估(LLaMA3 8B 作为基座 LLM)
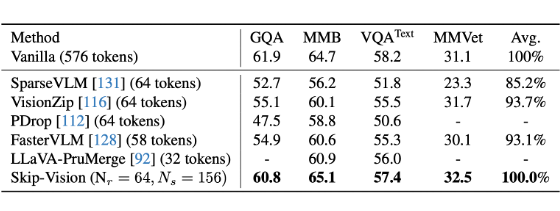
▲ 表2. 性能与效率评估(Vicuna-1.5 7B 作为基座 LLM)
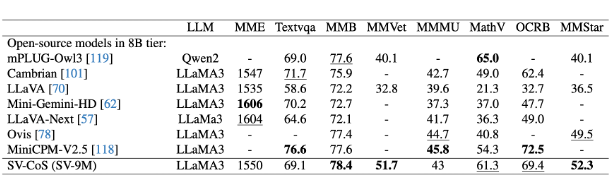
▲ 表3. 扩展 Skip-Vision 的性能评估
Skip-Vision 不仅是一个优化技巧,更是对多模态大模型设计范式的重新思考。论文已公开在 Arxiv(https://arxiv.org/abs/2503.21817),更多详情可访问项目主页(https://zwl666666.github.io/Skip-Vision/)。
(文:PaperWeekly)