
ICCV 2025 视觉Token跳起来!上交大×蚂蚁联手推出多模态通用加速框架

近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,无需额外预训练或重新训练大模型,在SFT流程中插入即可加速视觉-语言模型。该框架通过跳过冗余视觉Token和使用Summary Token机制在保留理解能力的同时显著降低计算开销和延迟。
近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,无需额外预训练或重新训练大模型,在SFT流程中插入即可加速视觉-语言模型。该框架通过跳过冗余视觉Token和使用Summary Token机制在保留理解能力的同时显著降低计算开销和延迟。
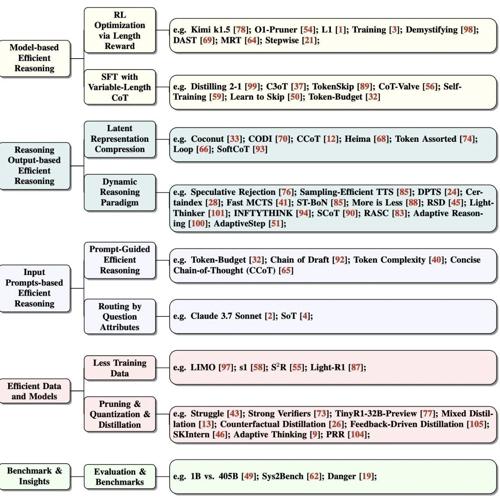
MLNLP社区是国内外知名的人工智能学术社区,其愿景是促进机器学习与自然语言处理领域内的交流合作。论文《Stop Overthinking》探讨了高效推理的方法及其在自动驾驶和医疗诊断等领域的应用挑战,提出模型优化、动态压缩和提示工程三大方向的研究进展及未来展望。

DeepSeek提出NSA稀疏注意力机制,显著降低大模型训练成本。实验表明,在64k上下文时,NSA前向传播速度最高提升9倍,反向传播速度提升6倍,解码速度提升11.6倍。论文已在arXiv上发布,梁文锋等DeepSeek原班人马参与。

MLNLP是国内外知名的人工智能社区,致力于推动自然语言处理与机器学习领域的交流与发展。2025年出现的DeepSeek模型通过技术革新颠覆了行业现状,展示了技术实力和成本优势。
免费用户也可使用o3 mini推理模型了!
作者|赵健
北京时间2月1日凌晨,OpenAI正式发布o

AI巨头OpenAI进军广告市场,《金融时报》报道指出,该公司正积极招募广告领域人才以推动收入增长。此举可能彻底改变AI商业模式。Sabine Hossenfelder担忧这会损害创新。用户更愿意支付订阅费而非看广告。