
高效推理



爆!三大热门大型模型服务方案实测:VLLM、LLaMA.cpp、SGLang 谁才是你的最强生产力引擎?

文章介绍了三种当前流行的大型语言模型(LLM)和服务方案:VLLM、LLaMA.cpp HTTP Server 和 SGLang。VLLM 以其高性能和快速响应著称;LLaMA.cpp 是一个轻量级的本地部署选项,适合没有高端 GPU 的用户;SGLang 则是一个智能框架,支持多步骤推理和函数调用,适合需要自定义 DSL 的场景。文章详细比较了每种方案的特点、优点及适用场景,并提醒了各自可能遇到的问题。
3.6B参数逆袭7B巨头!北航开源TinyLLaVA-Video-R1:小模型竟靠强化学习吊打大模型?
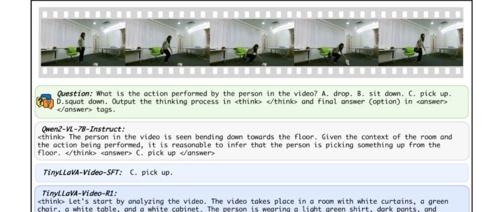
北京航空航天大学推出的小尺寸视频推理模型TinyLLaVA-Video-R1通过强化学习显著提升了小规模模型的性能,并开源了权重、代码和训练数据。该模型参数量不超过4B,在多个基准测试中表现优异,具备强大的多模态理解能力和可解释性生成能力。

停止过度思考!一篇关于高效Reasoning的综述来了~
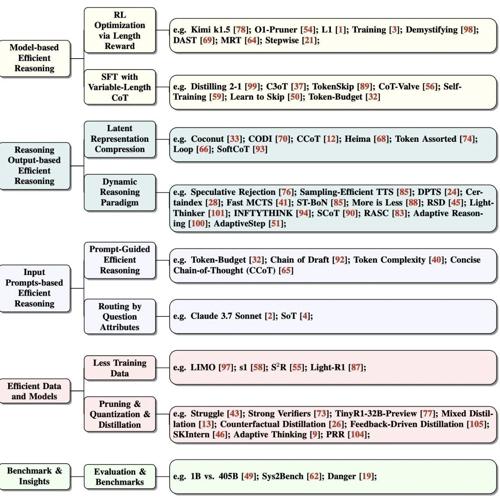
MLNLP社区是国内外知名的人工智能学术社区,其愿景是促进机器学习与自然语言处理领域内的交流合作。论文《Stop Overthinking》探讨了高效推理的方法及其在自动驾驶和医疗诊断等领域的应用挑战,提出模型优化、动态压缩和提示工程三大方向的研究进展及未来展望。

DeepSeek V3 引发AI路径之辩:从“鹦鹉学舌”到“乌鸦喝水”?

DeepSeek V3 是一款6710亿参数的开源模型,在训练成本上仅需278.8万GPU小时。其技术创新包括多头潜在注意力(MLA)和混合专家架构(MoE),展示了在推理效率和成本控制上的潜力,引发了业界对于更经济实惠AI路径的关注与讨论。