

随着人工智能技术的飞速发展,多模态模型在视频理解、问答等领域取得了显著进展。然而,大多数研究依赖于大规模模型,这对计算资源有限的研究者来说存在较高门槛。此外,高质量的推理数据稀缺,也限制了模型推理能力的提升。为了打破这些限制,北京航空航天大学的研究团队推出了一款名为TinyLLaVA-Video-R1 的小尺寸视频推理模型。该模型不仅开源了模型权重、代码和训练数据,还通过强化学习显著提升了小尺寸模型的推理能力。

一、项目概述
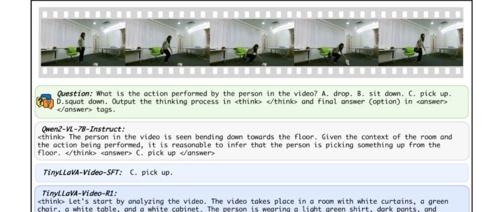
TinyLLaVA-Video-R1是一款基于 TinyLLaVA-Video 框架的小尺寸视频推理模型,由北京航空航天大学的研究团队开发。该模型通过强化学习提升推理能力,同时保持了模型参数量不超过 4B。与使用相同数据进行监督微调的模型相比,TinyLLaVA-Video-R1 在多个基准测试中表现出显著的性能提升,并且能够生成有意义的推理过程。这一项目的开源性质为资源有限的研究者提供了一个高效、可靠的多模态研究平台。
二、技术特点
(一)小尺寸模型的高效推理
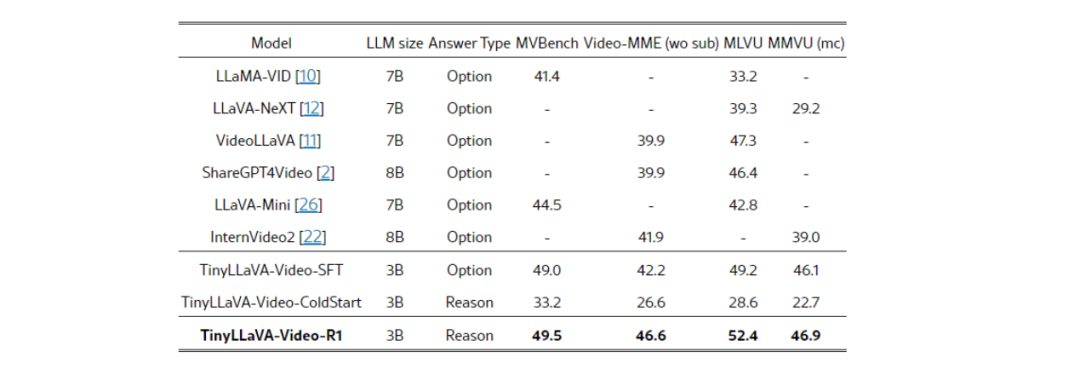
1. 参数量优化:TinyLLaVA-Video-R1 的参数量仅为 3.6B,与常见的 7B + 模型相比,体量小巧许多,但其在多个视频理解基准测试里的表现却毫不逊色,成绩斐然。
2. 强化学习的应用:模型创新性地引入强化学习机制,推理能力得以显著增强。与单纯依赖监督微调的模型相比,TinyLLaVA-Video-R1 在推理任务中优势尽显,表现更为亮眼。
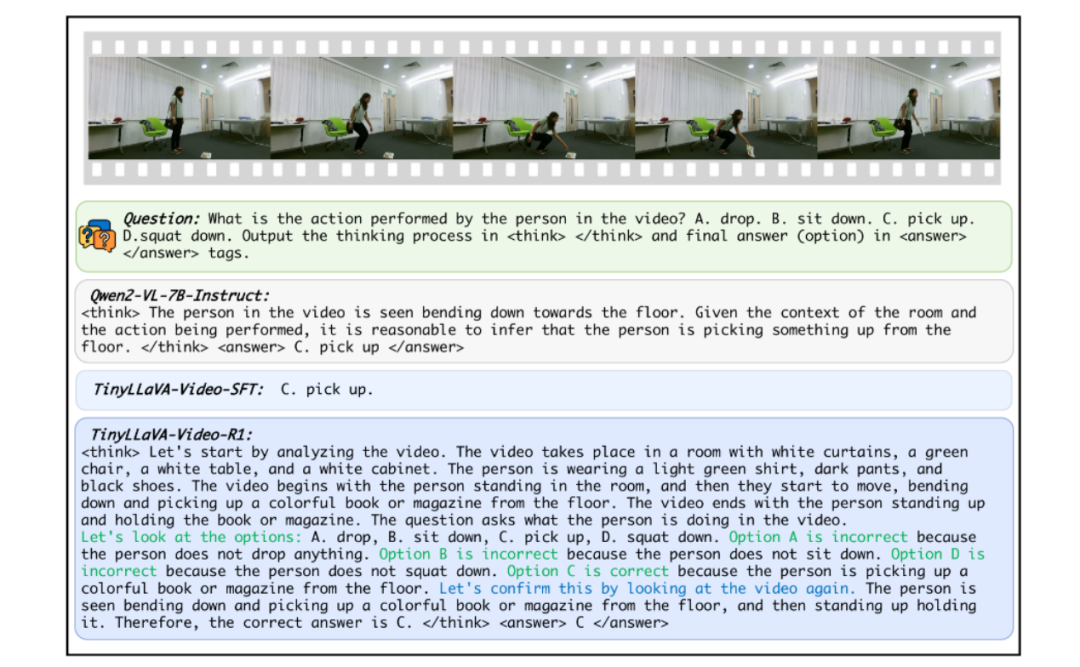
3. 推理过程的可解释性:该模型一大突出优势在于,不仅能够精准输出最终答案,还能够详细生成推理过程,这一特性使其在视频问答任务中脱颖而出,大大提升了回答的可信度与可解释性 。
(二)开源与可扩展性
1. 全面开源:TinyLLaVA-Video-R1 践行开源理念,将模型权重、代码以及训练数据毫无保留地开源,研究者能够轻松依照开源内容复现实验,极大地推动了相关研究的发展。
2. 模块化设计:模型沿袭了 Vision Tower+Connector+LLM 的经典框架结构,具备高度的灵活性,支持研究者依据自身需求,灵活替换语言模型和视觉编码器,为个性化定制模型提供了便利 。
(三)训练策略的创新
1. 引入长度奖励与答案错误惩罚:为提升模型响应的质量与长度,TinyLLaVA-Video-R1 在训练进程中引入长度奖励机制,同时对错误答案予以惩罚,双管齐下,有效促使模型输出更优质的结果。
2. 优势计算中的噪声引入:针对优势消失难题,模型在优势计算环节巧妙引入高斯噪声,此举确保了样本的多样性,使得模型训练更加稳定、高效 。
三、核心功能
(一)视频问答
1. 多模态理解:TinyLLaVA-Video-R1 具备强大的多模态理解能力,能够精准剖析视频内容,并紧密结合所提问题,生成准确无误的答案,满足用户对视频信息的深度挖掘需求。
2. 推理过程生成:区别于普通模型,该模型在输出答案的同时,还能够完整生成详细的推理过程,每一个回答都有理有据,极大地增强了回答内容的可解释性,帮助用户更好地理解答案的推导逻辑 。
(二)强化学习提升
1. 性能提升:借助强化学习的强大助力,TinyLLaVA-Video-R1 在多个基准测试中均实现了性能的飞跃式提升,充分彰显了强化学习在优化模型性能方面的显著成效。
2. 自我反思与回溯:模型在推理过程中展现出独特的自我反思与回溯能力,能够对自身推理过程进行复盘,及时调整优化,进而输出更为精准、完善的答案 。
四、应用场景
(一)视频内容理解
1. 视频问答系统:TinyLLaVA-Video-R1 能够完美适配视频问答系统,凭借其高效的视频理解与问答能力,帮助用户迅速从视频中获取关键信息,提升信息获取效率。
2.视频分析工具:作为视频分析工具的核心组件,该模型能够深入解析视频中的复杂场景,为视频分析工作提供有力支持,广泛应用于安防监控、视频内容审核等诸多领域 。
(二)多模态研究
1. 小尺寸模型研究:TinyLLaVA-Video-R1 为小尺寸多模态模型的研究提供了坚实可靠的实验平台,助力研究者深入探索小尺寸模型在多模态任务中的潜力与应用。
2. 推理能力提升:模型所采用的强化学习策略,为提升多模态模型的推理能力开辟了全新路径,为后续相关研究提供了宝贵的思路与借鉴 。
五、性能表现
TinyLLaVA-Video-R1 在模型架构上大胆简化,同时严格把控训练数据规模,即便如此,其性能表现依旧令人瞩目。实验数据清晰表明,整体参数不超过 4B 的 TinyLLaVA-Video-R1,在包含 MLVU、Video-MME 等在内的多个权威视频理解基准测试集中,成绩超越了同等训练数据量级下的 7B + 模型,有力地验证了该框架的科学性与有效性。
六、快速使用
(一)模型体验
官方公开了一个基于可追踪训练模型 TinyLLaVA-Video 的小型视频推理模型 TinyLLaVA-Video-R1,我们可以直接下载体验。
模型地址:https://huggingface.co/Zhang199/TinyLLaVA-Video-R1
(二)模型训练
官方除了在huggingface上开源了训练后的模型权重文件,还在github上公开了视频推理模型的训练过程,我可以基于此进行复现或者训练自己的频推理模型
1. 克隆仓库:
git clone https://github.com/ZhangXJ199/TinyLLaVA-Video-R1.gitcd TinyLLaVA-Video-R1
2. 创建并激活Conda 环境
conda create -n tinyllava_video python=3.10 -yconda activate tinyllava_videopip install --upgrade pippip install -e .
3. 安装额外依赖:
pip install flash-attn==2.7.3 --no-build-isolation4.基础模型准备
选项1:可以直接下载 TinyLLaVA-Video-ColdStart(https://huggingface.co/Zhang199/TinyLLaVA-Video-Coldstart_NextQA_16)
选项2:可以自行训练模型:
在scripts/train/train_qwen2_coldstart.sh 中将数据路径和模型路径替换为您的路径
bash scripts/train/train_qwen2_coldstart.sh5. GRPO 训练
bash scripts/train/train_qwen2_reason_nextqa.sh七、结语
TinyLLaVA-Video-R1 作为一款开源的小尺寸视频推理模型,通过强化学习显著提升了推理能力,同时保持了高效的计算性能。其全面开源的特性为资源有限的研究者提供了一个理想的实验平台。无论是在视频问答系统中的应用,还是在多模态模型研究中的探索,TinyLLaVA-Video-R1 都展现了巨大的潜力。
八、项目地址
GitHub 地址:https://github.com/ZhangXJ199/TinyLLaVA-Video-R1
论文地址:https://arxiv.org/abs/2504.09641
(文:小兵的AI视界)