

S-GRPO团队 投稿
量子位 | 公众号 QbitAI
AI回答问题太慢太长且无用,有没有能让大模型提前停止思考的方法?
华为提出了首个在Qwen3上还有效的高效推理方法——S-GRPO,突破了思维链「冗余思考」瓶颈。
通过 “串行分组 + 衰减奖励” 的设计,在保证推理准确性的前提下,让模型学会提前终止思考,推理提速60%,生成更精确有用的答案。
S-GRPO适合作为当前Post Training(训练后优化)范式中的最后一步,在确保模型预先存在的推理能力不受损害的情况下,使能模型在思维链的早期阶段即可生成质量更高的推理路径,并在思考充分后隐式地提前退出。

S-GRPO对单条完整推理路径进行分段截断
OpenAI o1, Deepseek-R1等推理模型依赖Test-Time Scaling law解决复杂的任务。
然而,过长的思维链序列的生成也显著增加了计算负载和推理延迟,这提高了这些模型在实际应用中的部署门槛,且引入了很多冗余的思考。
S-GRPO的全称为序列分组衰减奖励策略优化(Serial-Group Decaying-Reward Policy Optimization),旨在提升大语言模型(LLM)的推理效率和准确性,解决冗余思考问题。
核心理念
传统的推理优化方法,如GRPO(Group Reward Policy Optimization),采用并行生成多条完整推理路径的方式(如下图左侧所示),并通过0/1奖励机制对每条路径的最终答案进行评价。
然而,这种方法未能充分利用推理过程中的中间信息,也未能有效提升推理效率。
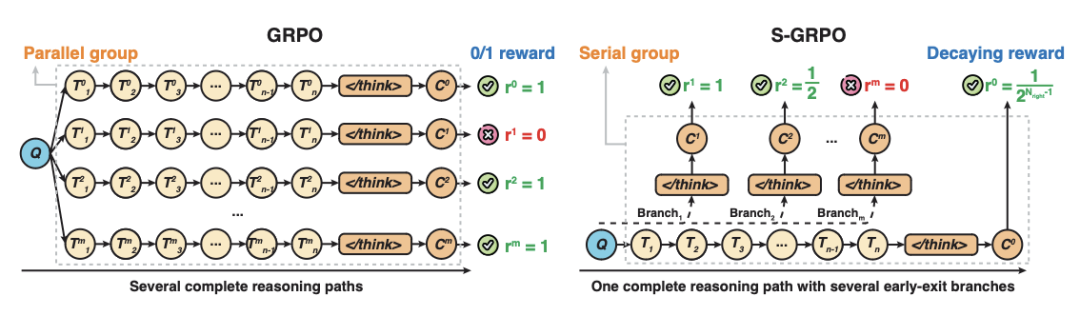
S-GRPO的创新之处在于引入了“早退推理”的概念(如上图右侧所示)。
它通过对单条完整推理路径进行分段截断,生成多个“早退推理”分支(Serial Group),并通过一种指数衰减的奖励机制对这些分支的答案进行评价。
具体来说:
- 早退推理路径(Serial Group)
模型在推理过程中,可以在任意中间步骤停止推理并直接生成答案。这些不同位置的早退路径被用于训练模型,以评估在不同推理深度下的推理质量。 - 衰减奖励策略(Decaying Reward Strategy)
对于每个早退路径,如果答案正确,则根据其推理深度分配奖励,越早退出推理的正确答案,奖励越高(例如,奖励值按照 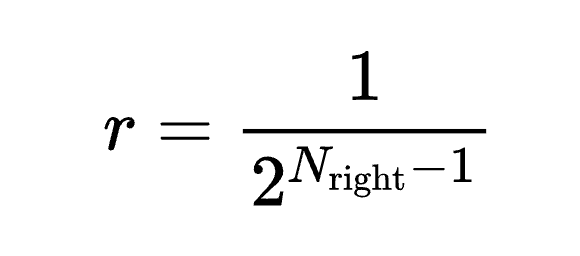 的规则递减);如果答案错误,则奖励为0。这种机制不仅鼓励模型尽早得出正确答案,还确保了推理的准确性。
的规则递减);如果答案错误,则奖励为0。这种机制不仅鼓励模型尽早得出正确答案,还确保了推理的准确性。
方法
S-GRPO的训练框架分为三个主要阶段,如下图所示:
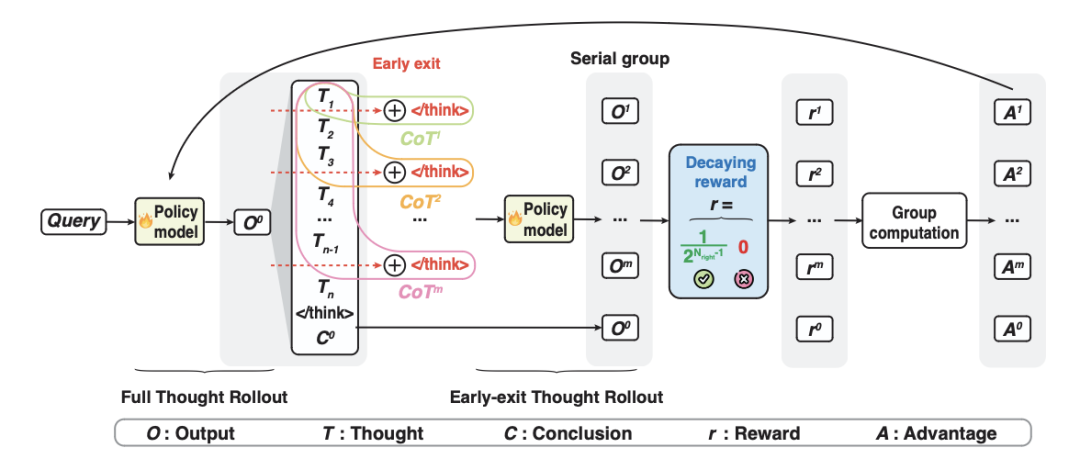
- 完整推理展开(Full Thought Rollout)
模型首先生成一条完整的推理路径(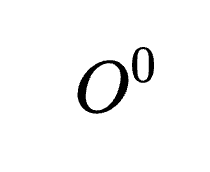 ),即从初始思考步骤(
),即从初始思考步骤(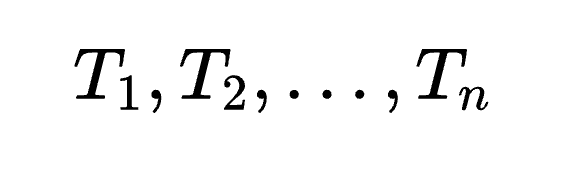 )到最终的推理结束标志(
)到最终的推理结束标志( ) 和答案(
) 和答案(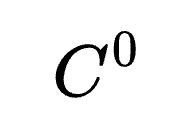 )。这一阶段为后续的早退路径生成提供了基础。
)。这一阶段为后续的早退路径生成提供了基础。
- 早退推理展开(Early-exit Thought Rollout)
在完整推理路径的基础上,模型通过随机截断生成多个早退路径(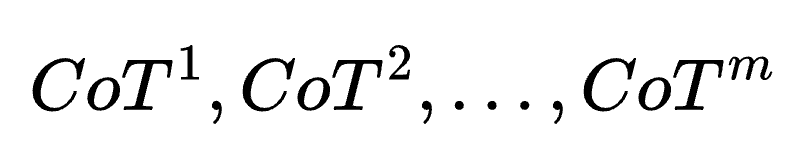 )。
)。
每条早退路径在截断点插入提示语“Time is limited, stop thinking and start answering. \n</think>\n\n”,明确指示模型停止推理并生成答案(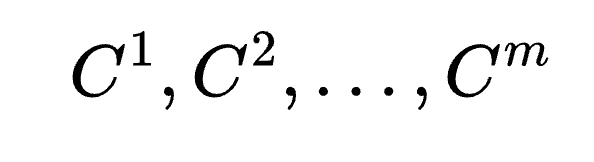 )。
)。
这些早退路径形成了一个“序列分组”(Serial Group),用于训练模型在不同推理深度下的表现。
- 奖励计算与参数更新(Reward Computation and Parameter Update)
对于每条早退路径,模型根据衰减奖励策略计算奖励值(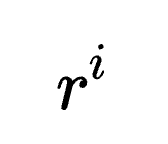 ),并进一步计算优势值(
),并进一步计算优势值(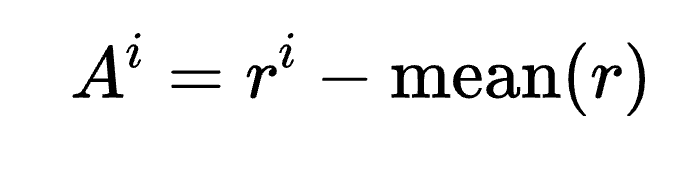 )。
)。
这些优势值用于优化模型参数,最终使模型学会在合适的时机停止推理并生成高质量答案。
下图直观地展现了S-GRPO在训练过程中如何采样在不同位置提前退出的completions以及赋予奖励。
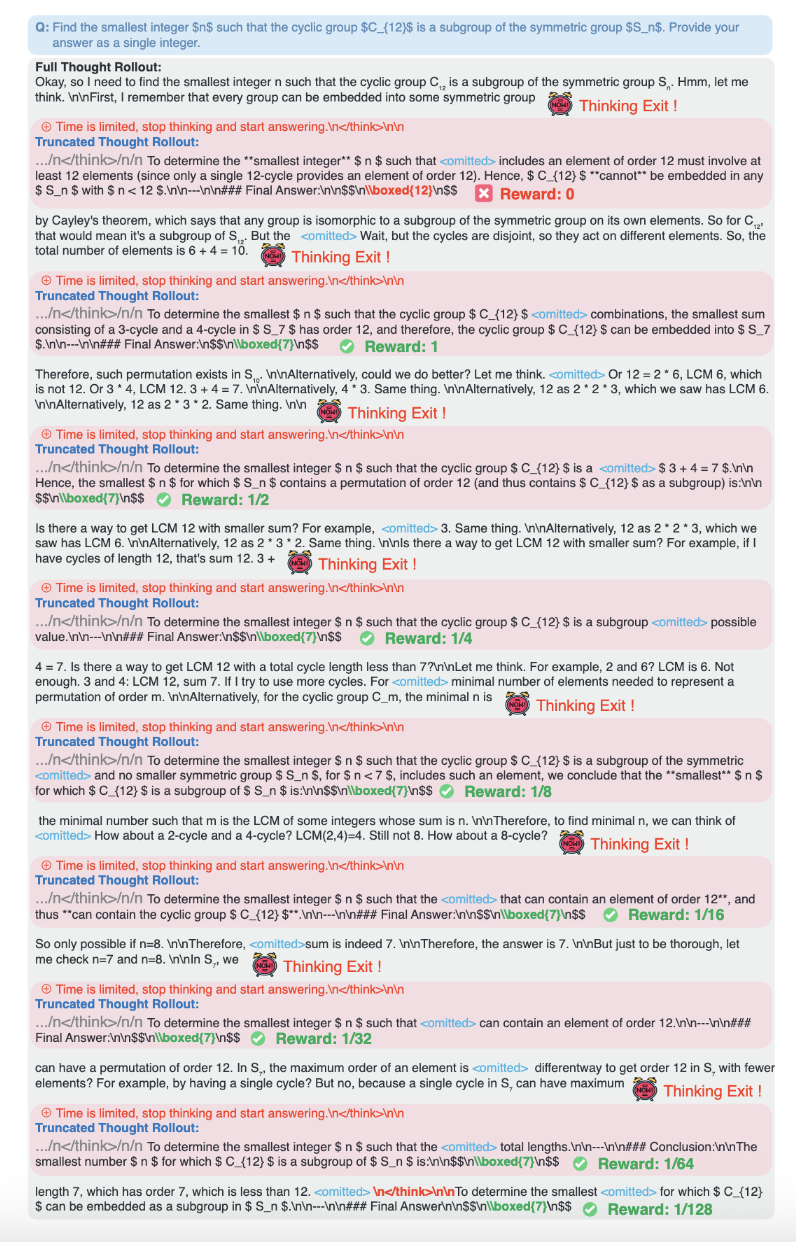
对于第一个退出的位置,模型给出的中间答案错误,则将奖励置为0。
对于后续给出正确答案的提前退出,则基于退出位置赋予衰减的正向奖励值,越早退出收益越高,从而鼓励模型探索简洁且正确的思考。
实验结果
为了验证S-GRPO的表现,作者在5个挑战性的推理benchmark上进行了测评,其中包含4个数学推理任务(GSM8K、MATH-500、AMC 2023、AIME 2024)、1个科学推理任务(GPQA Diamond)。
评估指标选用准确率和生成token数量两维度评测。实验选用了R1-Distill-Qwen系列模型(7B,14B)和Qwen3系列模型(8B, 14B)。
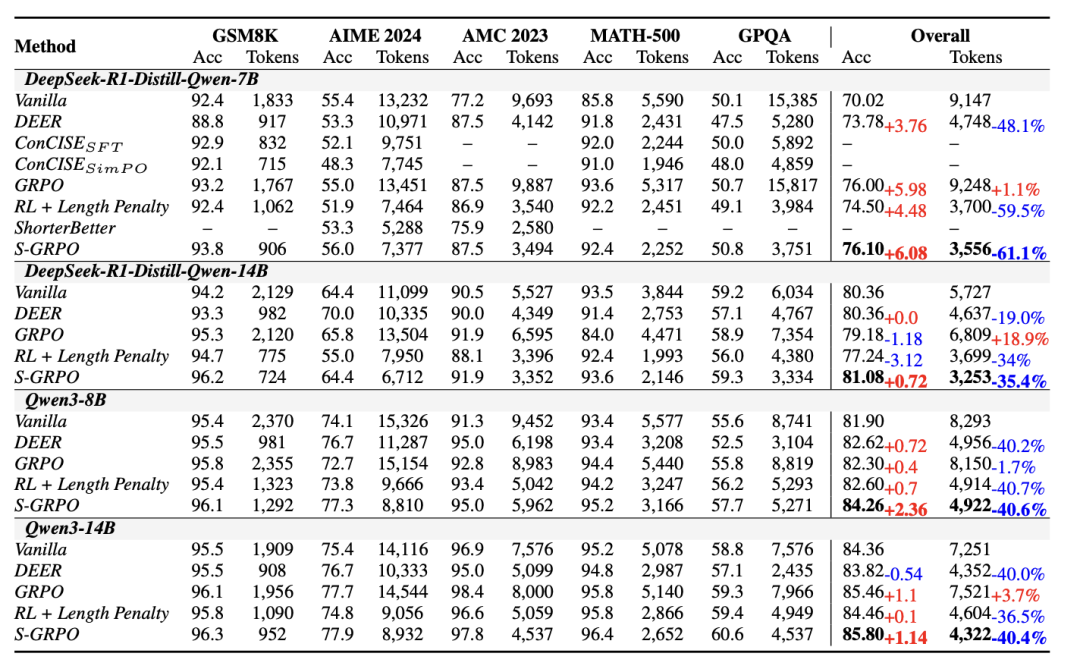
实验结果表明S-GRPO显著地超过了现有的baseline。
相较于vanilla的推理模型,S-GRPO平均提高了0.72到6.08个点准确率的同时降低了35.4%到61.1%的生成长度。
S-GRPO在训练集域内(In Domain)的数学推理benchmark上(GSM8K、MATH-500、AMC 2023、AIME 2024)和训练集域外(Out of Domain)的科学推理题目上(GPQA Diamond)都获得了显著的提升,充分证明了该方法的有效性和鲁棒性。
相比于当前其它SOTA高效推理方法,S-GRPO最好的兼顾了正确性和效率。
相比于DEER,S-GRPO在困难问题与简单问题上都能有效降低思考长度并维持精确度。
相比于原始GRPO,S-GRPO显著降低了推理长度的同时有着相近的准确率。
而与其它的高效推理训练方法相比,S-GRPO保持住了准确率,而它们均对回答的准确率性能有损害。
实验还探究了S-GRPO在不同生成长度预算下的性能。
通过控制推理时的生成长度预算由短到长,比较S-GRPO与vaniila CoT在GSM8K和AIME 2024上准确率与实际生成长度的变化。
下图中的实验结果展现出在不同的预算下,S-GRPO都比vaniila CoT的准确率高且生成长度更短。
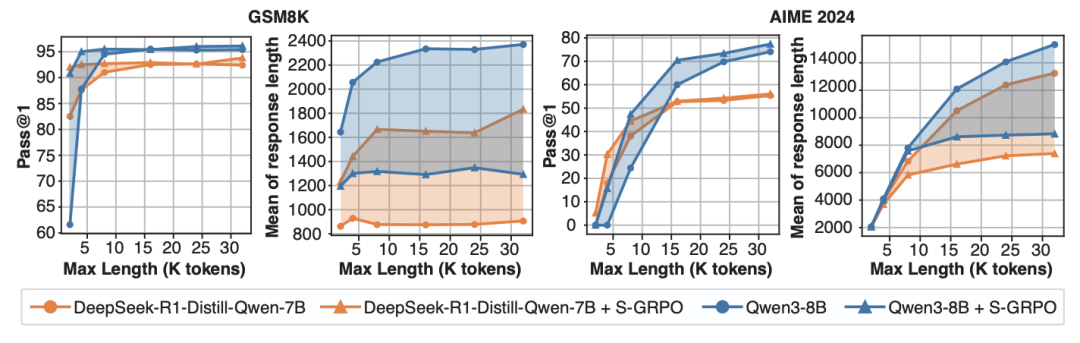
此外,实验还表明,在长度预算少的情况下,S-GRPO相比vaniila CoT的准确率增益更显著,实际生成长度相近;在长度预算高的情况下,S-GRPO相比vaniila CoT的实际生成长度更短,准确率略高。
S-GRPO相比vaniila CoT的两个变化趋势都更平缓。这表明S-GRPO只需要较低的长度预算就可以达到较高的准确率,反映出S-GRPO可以生成简洁且正确的思考路径。
为了验证S-GRPO中每个设计的有效性,实验设置了三个不同的消融实验。
下表的实验结果表明仅保留two-time rollouts中采样的最短且正确的completion的设置虽然进一步缩短了推理长度,但是会损害模型的推理正确性。

消去对短输出提供高回报的设计,即所有对正确的采样结果都给予高回报,会导致模型推理依旧冗长,这是由于更长的推理更容易取得正确的结果,模型会收敛到探索长序列推理的方向。
移除掉Serial-Group Generation的设计后,S-GRPO退化成GRPO,模型在准确率和推理长度上取得了与w/o. Decaying(All 1)相近的表现,这说明作为S-GRPO中不可或缺的一环,Serial-Group Generation的设计本身不会损害模型在RL中的探索能力。

上图中对比了S-GRPO与vanilla推理过程以及相同thinking budget下硬截断迫使模型给出结论的输出内容对比。
尽管同样给出了正确的答案,S-GRPO仅使用了一半不到的思考budget,证明了S-GRPO有效解决了overthinking问题。
假如直接对原始推理内容在相同thinking budget处截断,模型无法基于已有的思考内容得到正确的结论,这说明S-GRPO更精确地定位到了准确的解题思路。
这样就有效地帮助模型向简洁且正确的思考路径收敛,避免了对于每个解题路径浅尝辄止的underthinking问题。
感兴趣的朋友可到原文查看更多细节。
论文标题:S-GRPO: Early Exit via Reinforcement Learning in Reasoning Models
论文链接:https://arxiv.org/abs/2505.07686
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)