


论文:Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
链接:https://arxiv.org/pdf/2503.16419
研究背景与核心问题
LLMs 通过链式推理(Chain-of-Thought, CoT)在数学、编程等复杂任务中表现出色,但生成的冗长推理步骤导致显著的计算开销,即“过思考现象”(Overthinking Phenomenon)。例如,模型在回答简单问题(如“0.9和0.11哪个更大?”)时可能生成数百个冗余推理标记,显著增加推理时间和成本。

核心矛盾:长推理链提升准确性,但牺牲效率;高效推理需在保持性能的同时缩短推理长度。
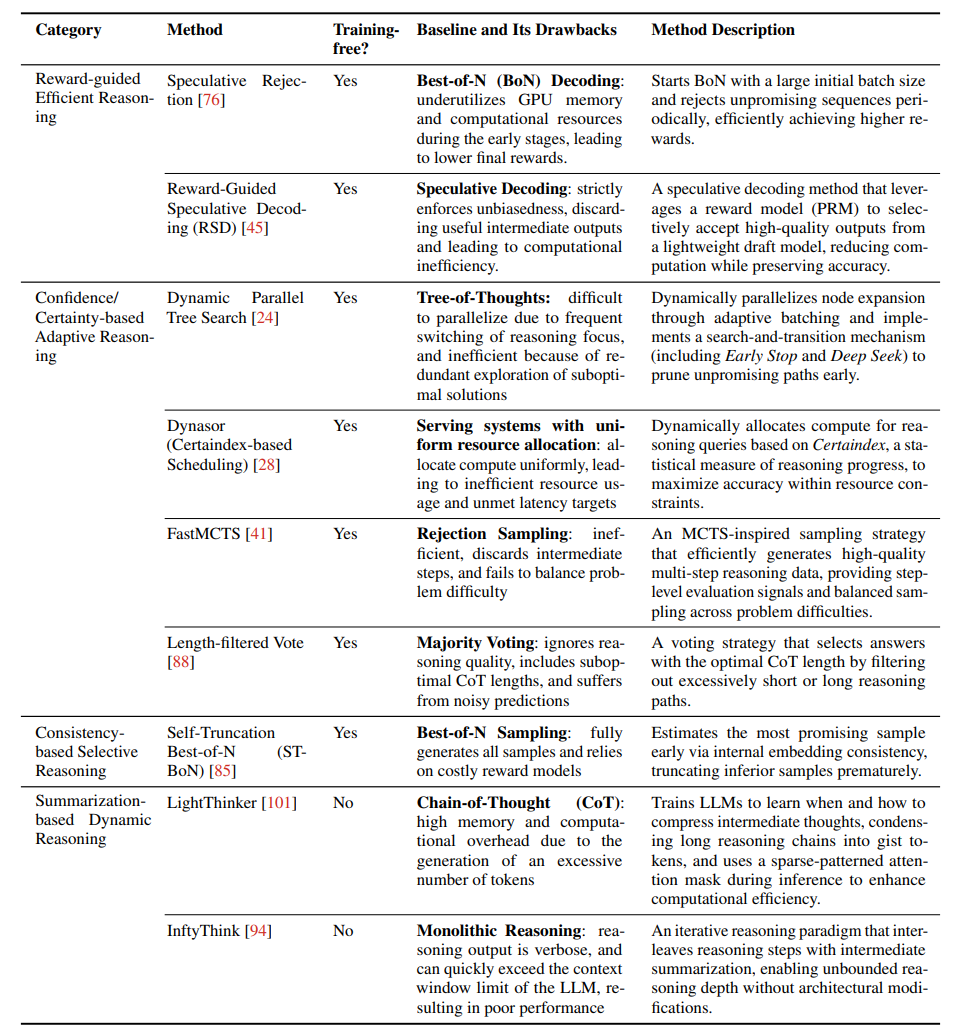
方法论分类与框架
论文提出高效推理的三类方法框架:
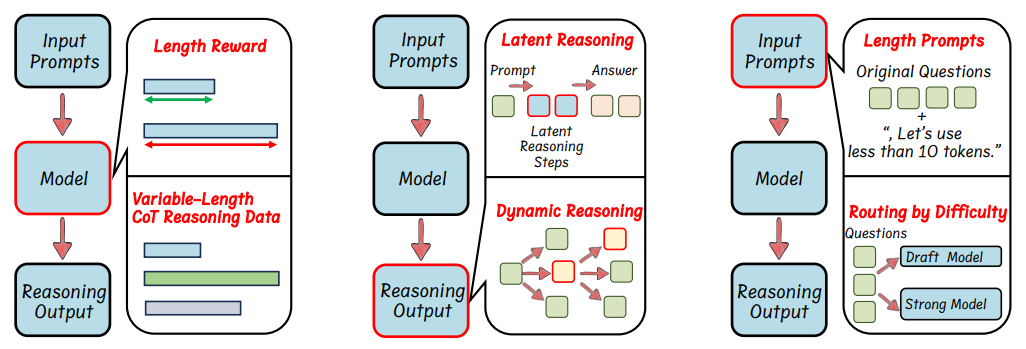
-
模型基础的高效推理:通过优化模型结构或训练策略实现。例如,强化学习(RL)结合长度奖励(如PPO算法),或监督微调(SFT)使用可变长度CoT数据。 
-
基于推理输出的高效推理:在生成过程中动态压缩或跳过冗余步骤。例如,将推理步骤压缩为潜在表示(如Coconut方法),或通过置信度动态终止推理。 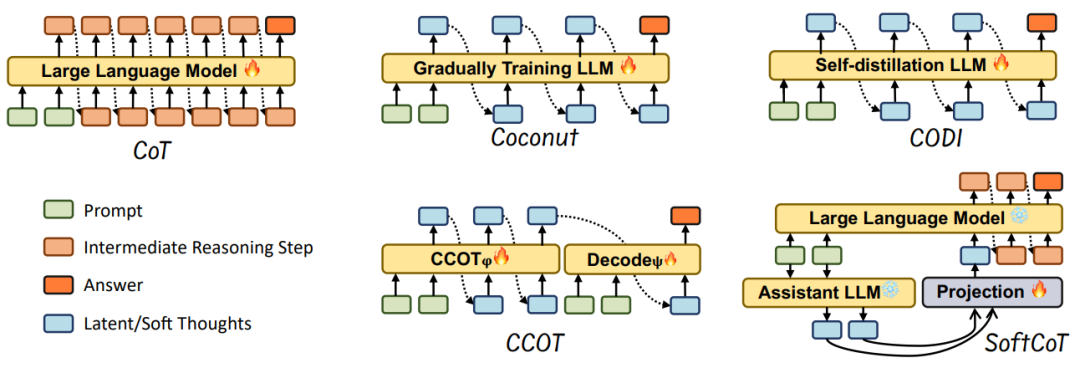
-
基于输入提示的高效推理:通过提示工程约束输出长度(如Token-Budget),或根据问题难度路由到不同模型。 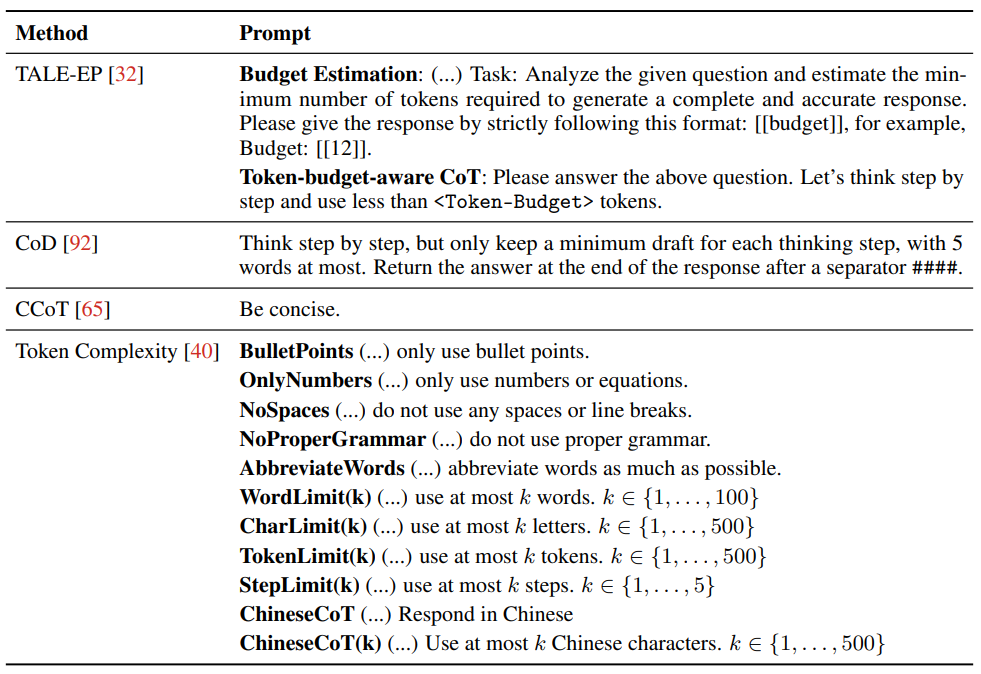
关键技术细节与创新
-
RL与长度奖励设计:在强化学习中引入长度惩罚项,例如O1-Pruner通过“长度协调奖励”缩短推理步骤,同时保证准确性。 
-
可变长度CoT数据构建:通过后处理压缩(如GPT-4精简步骤)或推理中动态生成(如Token-Budget的二元搜索)。 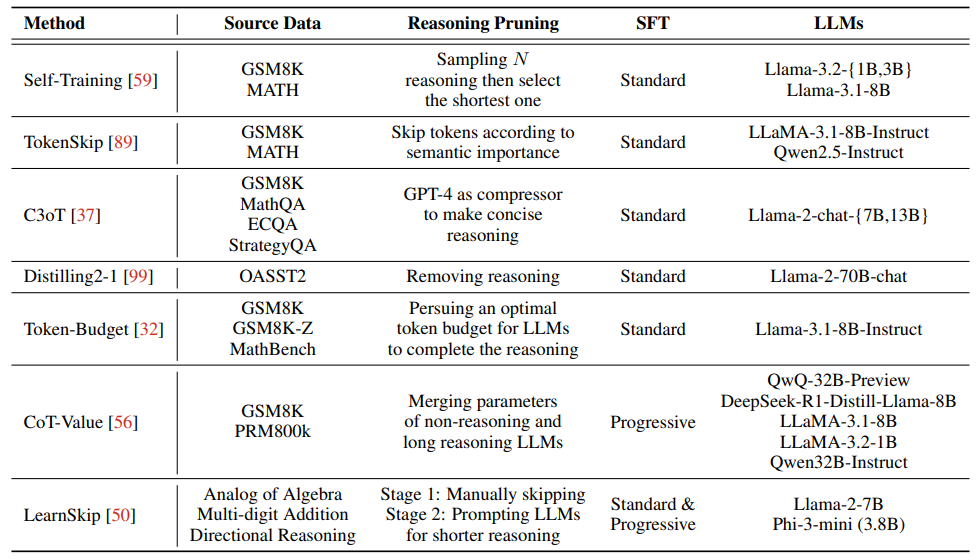
-
潜在表示压缩:Coconut将推理步骤编码为连续隐藏状态,减少显式文本生成,提升效率。 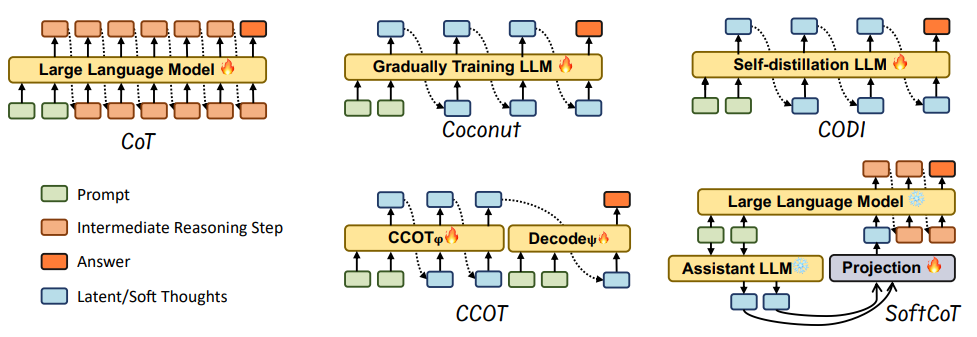
-
动态推理范式:如Speculative Rejection通过奖励模型提前终止低质量推理路径,或ST-BoN利用嵌入一致性选择最优路径。 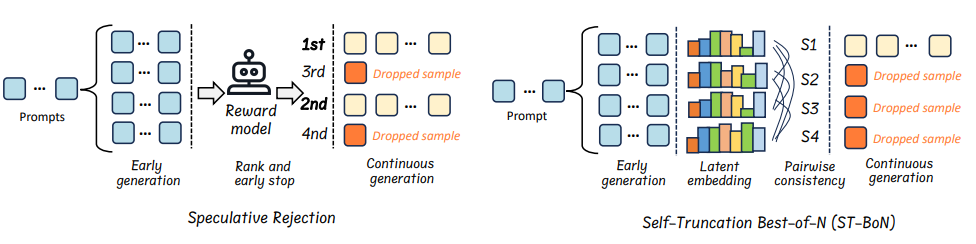
-
提示工程:通过明确指令(如“最多5个词”)或自适应路由(如Claude 3.7的混合模式)控制推理长度。 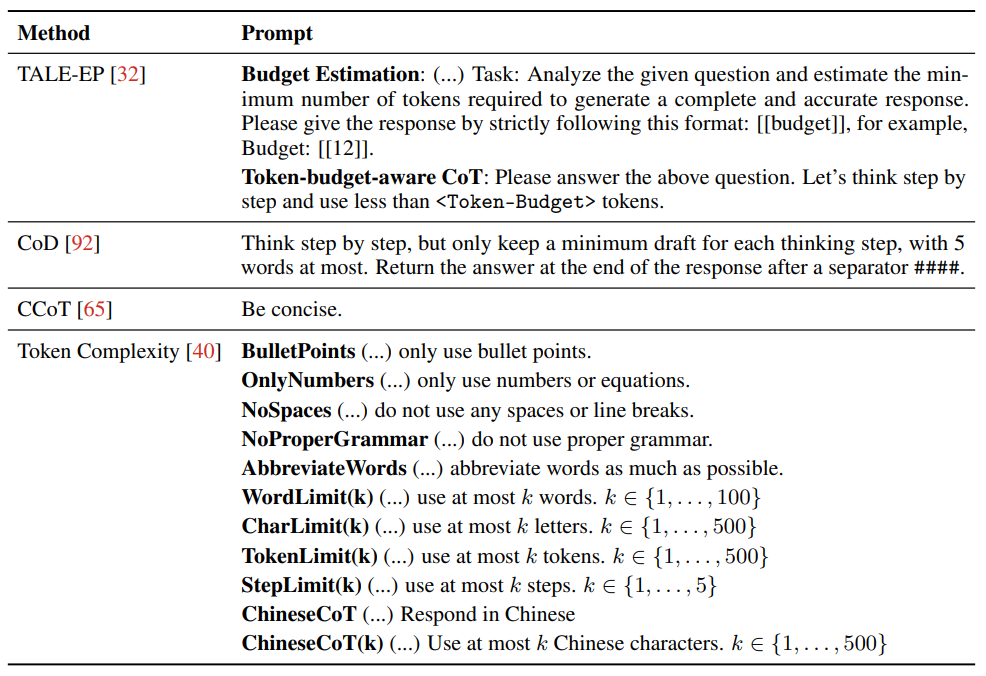
应用场景与挑战
-
自动驾驶:高效推理模型可实时处理多模态传感器数据,提升决策速度与安全性。 -
医疗诊断:快速分析患者数据,生成简洁的医学解释,降低误诊风险。 -
安全与效率的权衡:研究发现,过度压缩推理步骤可能削弱模型的自检能力,导致安全隐患<Section 8.2>。
总结与未来展望
论文系统梳理了高效推理的研究进展,提出模型优化、动态压缩、提示工程三大方向,并强调小模型推理能力提升的重要性(如蒸馏与量化)。未来需进一步探索:
-
无损压缩技术:如何在极端缩短推理时保持准确性。 -
跨任务泛化:现有方法在特定任务(如数学)有效,但通用性不足。 -
人机协同设计:结合人类反馈优化推理路径的可解释性。
(文:机器学习算法与自然语言处理)