

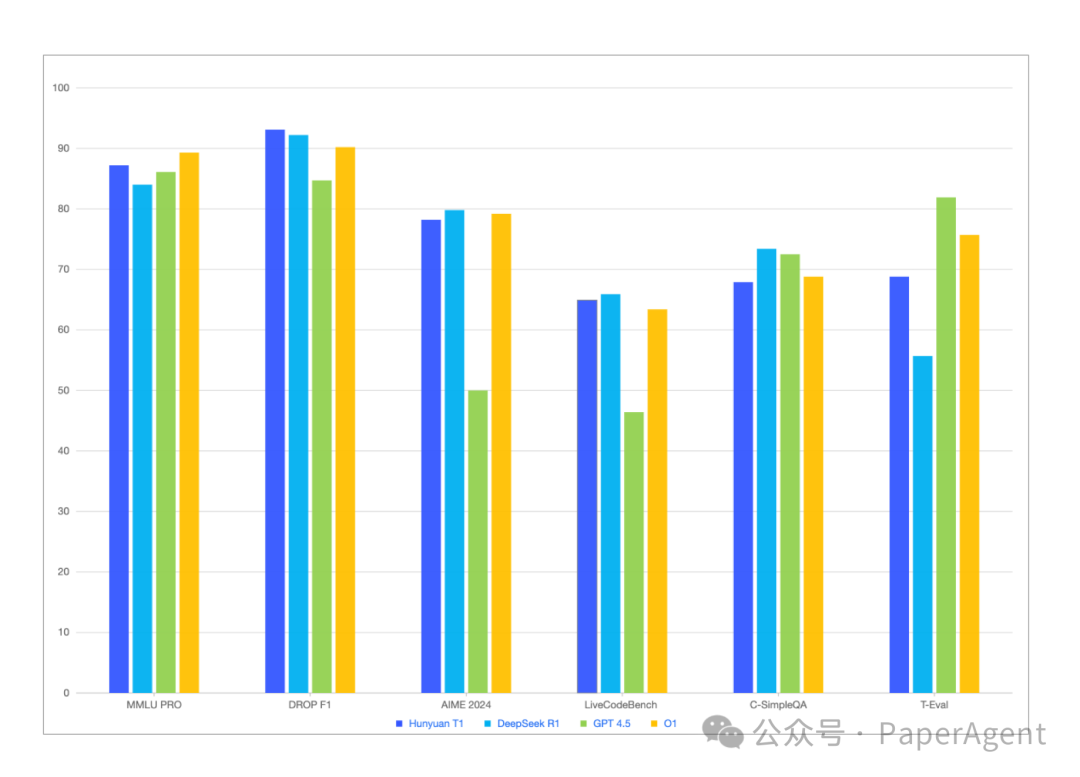
今天,腾讯发布深度思考模型混元-T1正式版,强化学习驱动,业内首个超大规模混合Mamba推理模型,在各类公开benchmark上基本持平或略超DeepSeek-R1外,在内部人工体验集评估上也能对标,比如agent能力方面略有胜。

腾讯混元T1的训练技术主要体现在以下几个方面:
1. 基于超大规模Hybrid-Transformer-Mamba MoE大模型TurboS基座
-
长文捕捉能力:TurboS架构能够有效解决长文推理中上下文丢失和长距离信息依赖问题,提升长文推理能力。
-
优化长序列处理:Mamba架构专门优化了长序列处理能力,通过高效计算方式,在保证长文本信息捕捉能力的同时,显著降低计算资源消耗,解码速度提升2倍。
2. 强化学习训练
-
算力投入:在模型后训练阶段,96.7%的算力投入到强化学习训练,重点提升纯推理能力及对齐人类偏好。
-
数据集构建:收集了涵盖数学、逻辑推理、科学、代码等领域的世界理科难题数据集,并结合ground-truth的真实反馈,确保模型在多种推理任务中表现出色。
-
训练方案:采用课程学习方式,逐步提升数据难度并阶梯式扩展模型上下文长度,使模型在提升推理能力的同时学会高效利用token进行推理。
-
训练策略:参考经典强化学习的数据回放和阶段性策略重置策略,显著提升模型训练的长期稳定性(50%以上)。
3. 对齐人类偏好
-
奖励系统:采用self-rewarding(基于T1-preview早期版本对模型输出进行综合评价、打分)+ reward mode的统一奖励系统反馈方案,指导模型自我提升。
-
效果提升:模型在答复中展现出更丰富的内容细节和更高效的信息传递。
https://llm.hunyuan.tencent.com/#/blog/hy-t1
(文:PaperAgent)