

作者|子川
来源|AI先锋官
价格屠夫的称号建议直接焊在腾讯深度思考模型 T1上,太卷了!
昨晚,腾讯混元罕见的开直播发布它们最新的模型——深度思考模型混元T1正式版。
根据官方介绍,混元T1正式版在推理能力、长文本处理、成本效率三大维度实现突破性升级!
“吐字快、能秒回、逻辑强”。
小编实测,最直观体验首先也是,太快了!
与此前已上线腾讯元宝的混元T1-preview相比,综合效果明显提升。
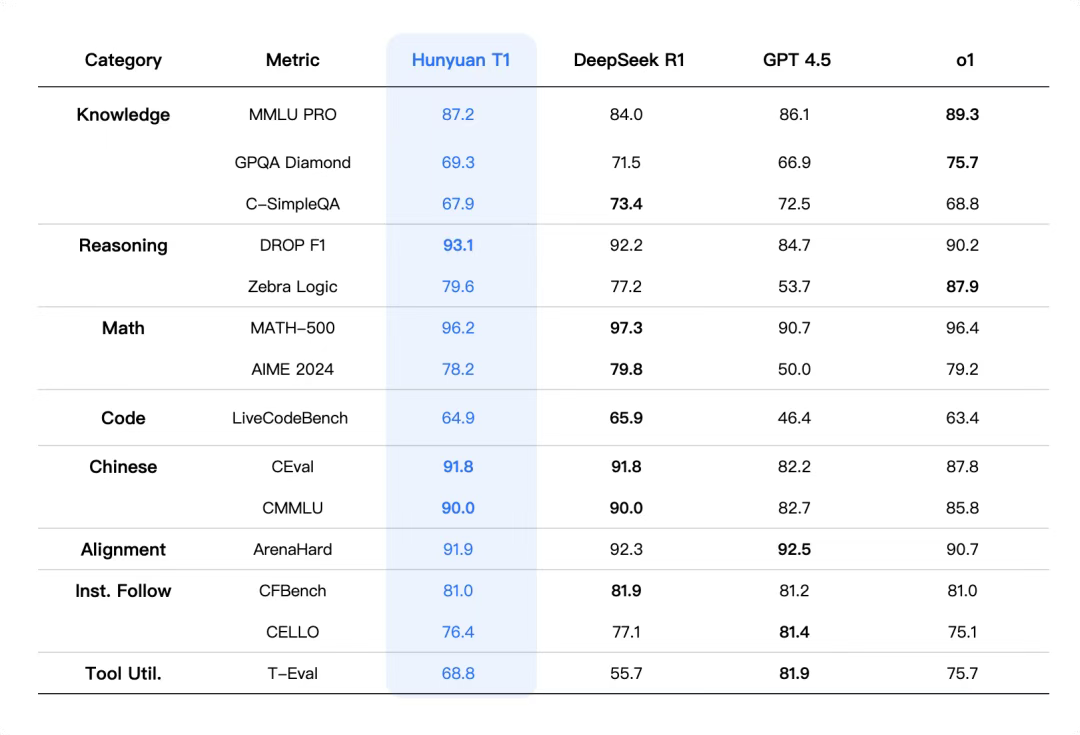
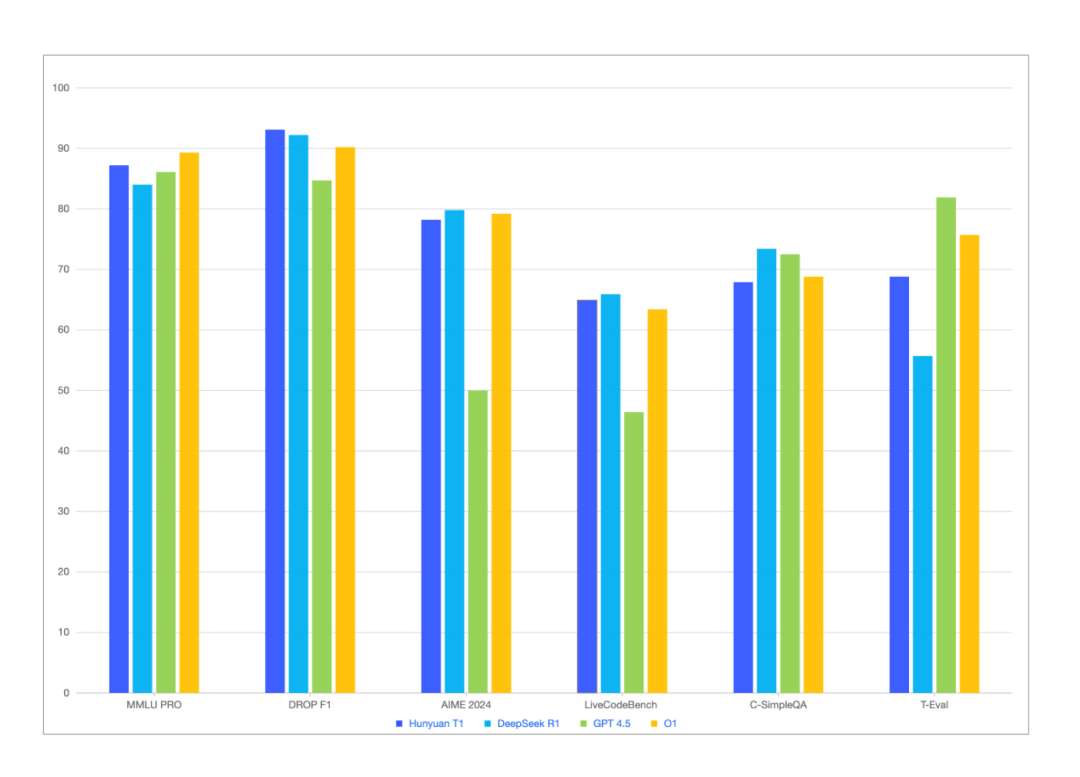
从放出的跑分成绩来看,混元T1正式版在多项评估指标上超越OpenAI o1、GPT-4.5,以及Deepseek R1。
如在大语言模型(LLM)评估增强数据集MMLU-PRO中,混元T1取得87.2分,仅次于得分89.3的OpenAI o1,高于得分86.1的OpenAI GPT 4.5和得分84的DeepSeek R1。
另外T1沿用了混元Turbo S的创新架构,首次在工业界实现混合Mamba架构无损应用于超大型推理模型,这一设计打破传统Transformer的算力桎梏。
最直观的体现就是在价格上——
输入价格为1元/百万tokens,输出价格为4元/百万tokens。
对比同类模型,T1的API定价堪称“价格屠夫”。
号称AI界“拼多多”的DeepSeek R1在标准时段的定价为4元/百万tokens输入,16元/百万tokens输出。
文心大模型X1的定价则是2元/百万tokens输入,8元/百万tokens输出。
换句话说,混元T1的价格仅为DeepSeek R1的1/4,是文心 X1的1/2。


混元T1正式版



测试题二:金币游戏
你和朋友轮流从一堆金币中取1、3或6枚。获胜者是最后取走金币的人。对于N<1000,第一位玩家有多少种赢得游戏的策略?
混元T1正式版

DeepSeek R1

Qwen2.5-Max

看DeepSeek思考了262秒就知道这道题已经足够难了,然后它们三居然又全部回答正确了。
看来只能拿出杀手锏了,之前Deepseek R1都回答错误的一道题。



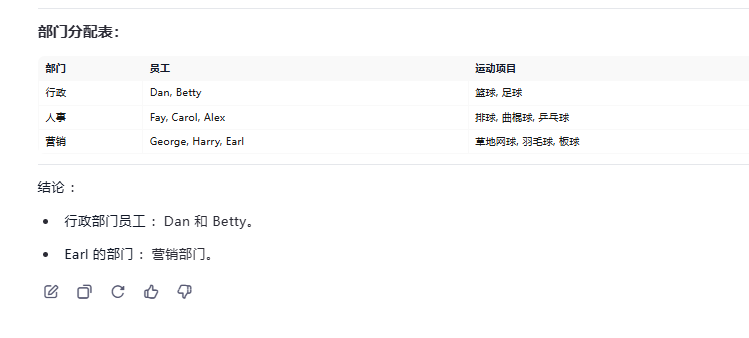
Alex、Betty、Carol、Dan、Earl、Fay、George 和 Harry 是一家公司的八名员工
他们在三个部门工作:人事、行政和营销,任何部门不超过三个。
他们每个人都有不同的运动选择,包括足球、板球、排球、羽毛球、草地网球、篮球、曲棍球和乒乓球,不一定顺序相同。
Dan 在行政部门工作,不喜欢足球或板球。
Fay 在人事部门工作,只有 Alex 喜欢乒乓球。
Earl 和 Harry 与 Dan 不在同一个部门工作。
Carol 喜欢曲棍球,不从事市场营销工作。
George 不在行政部门工作,不喜欢板球或羽毛球。
在行政部门工作的人之一喜欢足球。
喜欢排球的人在人事部门工作。
在行政部门工作的人都不喜欢羽毛球或草地网球。
哈利不喜欢板球。
在行政部门工作的员工是谁?
Earl 在哪个部门工作?
混元T1正式版

DeepSeek R1

Qwen2.5-Max
先来看一下正确答案:









不过放出了体验地址:
(文:AI先锋官)