
数据不够致Scaling Law撞墙?CMU和DeepMind新方法可让VLM自己生成记忆

CMU 和 Google DeepMind 的研究提出了一种名为 ICAL 的方法,通过使用低质量数据和反馈来生成有效的提示词,改善 VLM 和 LLM 从经验中提取见解的能力,从而解决高质量数据不足的问题。
CMU 和 Google DeepMind 的研究提出了一种名为 ICAL 的方法,通过使用低质量数据和反馈来生成有效的提示词,改善 VLM 和 LLM 从经验中提取见解的能力,从而解决高质量数据不足的问题。

本文介绍了上海科技大学 YesAI Lab 在 NeurIPS 2024 发表的工作《Federated Learning from Vision-Language Foundation Models: Theoretical Analysis and Method》。研究针对视觉-语言模型在联邦学习中的提示词微调提出理论分析框架,引入特征动力学理论并设计了PromptFolio机制,在平衡全局与个性化提示词的同时提升性能。

OpenAI 联合创始人 Ilya Sutskever 在 NeurIPS 2024 上演讲,认为数据资源接近极限且预训练模型即将终结,未来 AI 将更依赖于自主智能体和合成数据,并可能达到超级智能状态。

Ilya在NeurIPS 2024上宣布预训练时代即将终结,指出数据资源有限且枯竭,未来发展方向在于智能体、合成数据和推理能力。超级智能成为可能发展方向之一。
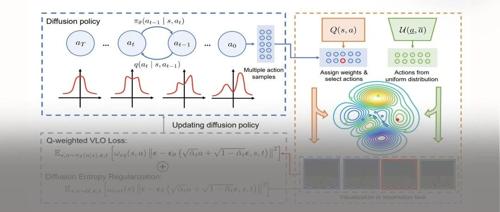
该工作提出了一种基于Q变分损失的扩散策略优化方法(QVPO),解决了扩散模型与在线强化学习结合的问题,提高了样本效率和最终表现。

研究团队提出自驱动 Logits 进化解码(SLED)方法,提升大语言模型事实准确性,无需外部知识库和额外微调。
