
多模态模型学会“按需搜索”,少搜30%还更准!字节&NTU新研究优化多模态模型搜索策略
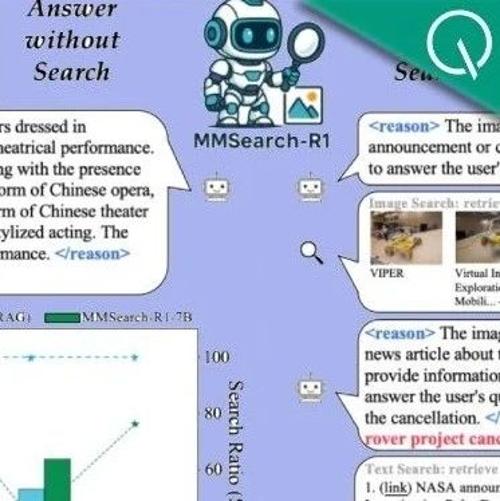
字节及南洋理工大学联合研究,提出一种基于强化学习的多模态模型自主搜索训练方法,在视觉问答任务中显著提升性能,减少约30%的搜索次数。
字节及南洋理工大学联合研究,提出一种基于强化学习的多模态模型自主搜索训练方法,在视觉问答任务中显著提升性能,减少约30%的搜索次数。

Seed1.5-VL 是一个由 ByteDance 开发的多模态语言模型,在处理复杂表格、模糊图片和几何题目等方面表现出色。其架构包含视觉编码器和MoE LLM。预训练数据包括3万亿高质量token,遵循幂律和对数线性关系。Seed1.5-VL 在Hugging Face上可用体验,并通过强化学习后处理提升性能。
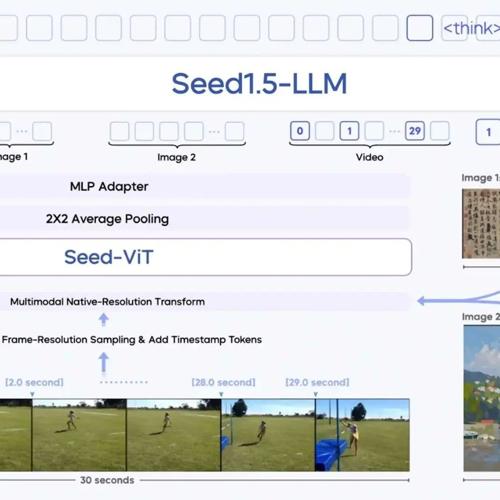
Seed1.5-VL是专为通用多模态理解和推理设计的视觉-语言基础模型,仅用5.32亿视觉编码器和200亿参数的MoE LLM实现顶尖性能,在60个公共基准测试中有38项达到最佳水平。

字节跳动开源的Text-to-Edit项目通过文本输入实现精确控制,采用高帧率采样和慢-快处理技术提升视频理解能力,支持用户定制视频风格。
