

1、杰出论文Safety Alignment Should be Made More Than Just a Few Tokens Deep.Learning Dynamics of LLM Finetuning.AlphaEdit: Null-Space Constrained Model Editing for Language Models.2、荣誉提名论文Data Shapley in One Training Run.SAM 2: Segment Anything in Images and Videos.Faster Cascades via Speculative Decoding.


论文:https://openreview.net/pdf?id=6Mxhg9PtDE
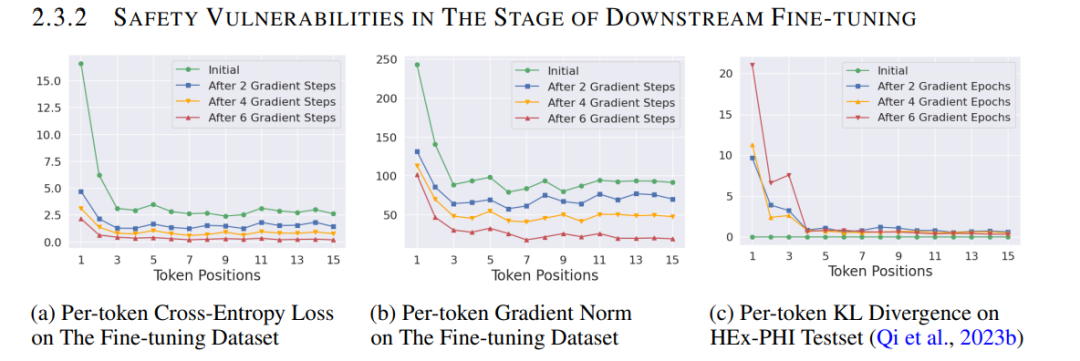
学习动态(Learning dynamics)描述了特定训练样本的学习如何影响模型对其他样本的预测,为我们理解深度学习系统的行为提供了一个强大的工具。通过分析不同潜在回答之间影响积累的逐步分解,研究了大型语言模型在不同类型微调(finetuning)过程中的学习动态。提出的框架允许对流行算法在指令微调(instruction tuning)和偏好微调(preference tuning)方面的训练进行统一解释。
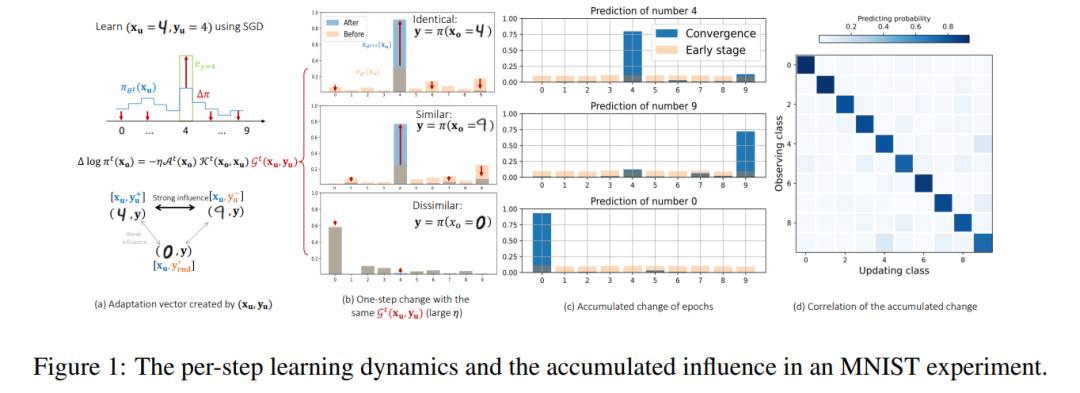
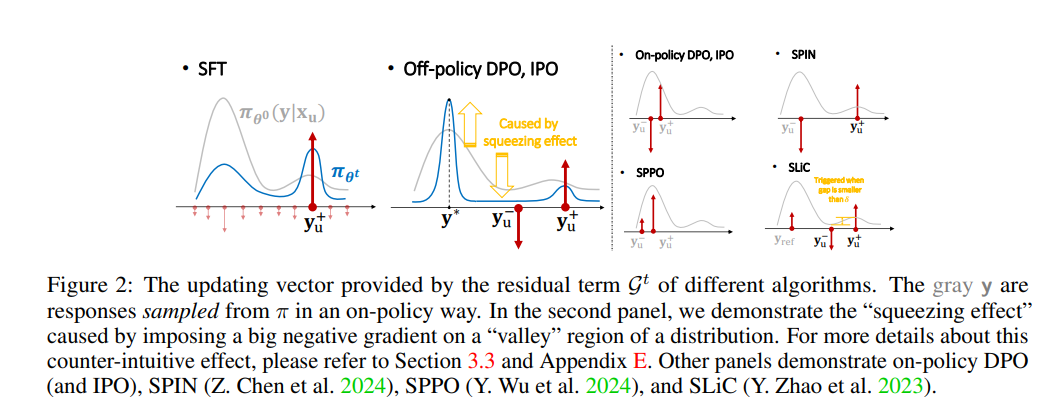
特别是,提出了一个假设性的解释,说明为什么特定类型的幻觉(hallucination)在微调后会增强。例如,模型可能会使用回答问题B的短语或事实来回答问题A,或者在生成回答时反复重复类似的简单短语。还扩展了提出的框架,强调了一个独特的“挤压效应”(squeezing effect),以解释在离线直接偏好优化(off-policy direct preference optimization,DPO)中观察到的一个现象,即运行DPO时间过长甚至会使期望的输出变得不太可能。这一框架还揭示了在线DPO和其他变体的益处来源。
这种分析不仅为理解大型语言模型的微调提供了新的视角,还启发了一种简单而有效的方法来提高对齐性能(alignment performance)。
code:https://github.com/Joshua-Ren/Learning_dynamics_LLM论文:https://openreview.net/pdf?id=tPNHOoZFl9


大型语言模型(LLMs)常常表现出幻觉现象,生成错误或过时的知识。因此,模型编辑方法应运而生,以实现针对性的知识更新。为了实现这一目标,一种流行的范式是“定位-编辑”方法,该方法首先定位有影响力的参数,然后通过引入扰动来编辑这些参数。尽管这种方法有效,但当前研究表明,这种扰动不可避免地会破坏LLMs中原本保留的知识,尤其是在顺序编辑场景中。
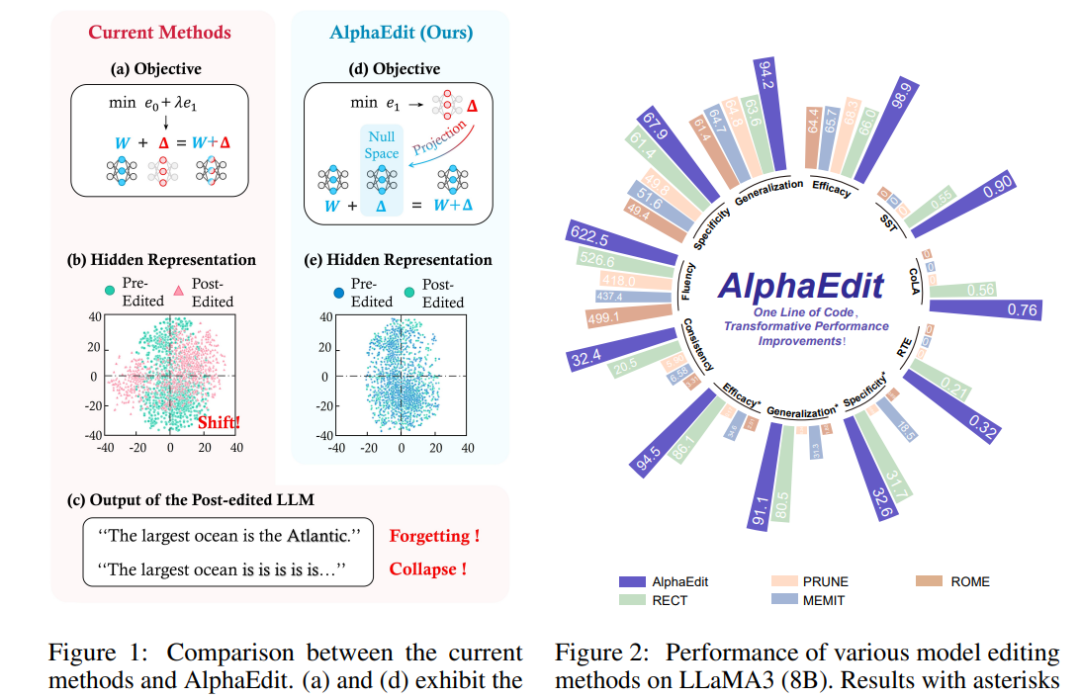
为了解决这一问题,引入了一种名为AlphaEdit的创新性解决方案。该方案在将扰动应用于参数之前,先将其投影到保留知识的零空间中。从理论上证明,这种投影可以确保在查询保留知识时,经过编辑后的LLMs的输出保持不变,从而缓解了知识破坏的问题。
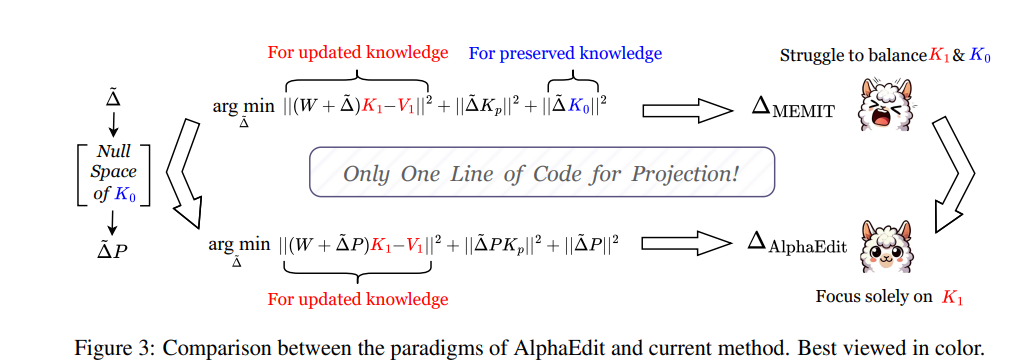
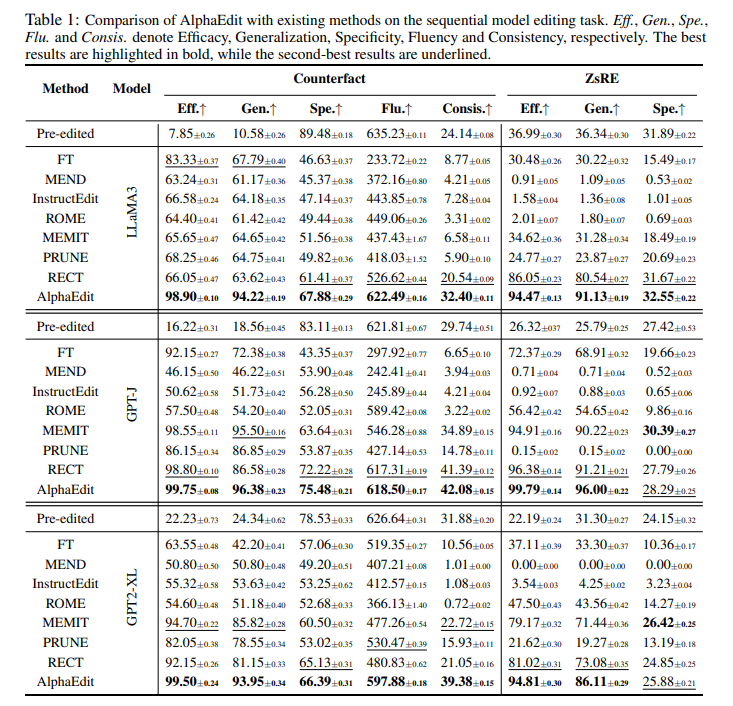
在包括LLaMA3、GPT2-XL和GPT-J在内的各种LLMs上进行的大量实验表明,AlphaEdit通过仅添加一行用于投影的额外代码,平均提升了大多数“定位-编辑”方法的性能达36.7%。
code: https://github.com/jianghoucheng/AlphaEdithttps://openreview.net/pdf?id=HvSytvg3Jhhttps://blog.iclr.cc/2025/04/22/announcing-the-outstanding-paper-awards-at-iclr-2025/
(文:PaperAgent)