
处理音频数据时,我们是不是经常要切换各种工具?
转写用 ASR(语音识别),转音频又得找稳定的 TTS 模型(工具)……
几个小时前,月之暗面 Moonshot AI 正式开源了 Kimi-Audio,可以帮助我们解决处理音频时来回切换不同工具的痛点。

Kimi-Audio 由月之暗面(Moonshot AI)开发,是一款开源音频基础模型,基于 Qwen 2.5-7B 构建,可以统一处理音频理解、生成和对话任务。
依托 1300 万小时音频数据预训练,通过混合输入(离散语义标记 + 连续声学特征)与创新架构,统一多种任务。
Kimi-Audio 支持语音识别(ASR)、音频问答(AQA)、音频字幕(AAC)、情感识别(SER)、声音分类(SEC/ASC)、文本到语音(TTS)、语音转换(VC)和端到端语音对话。
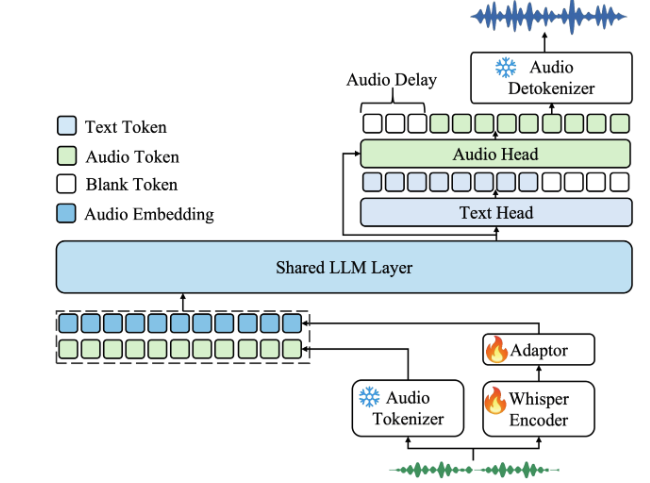
主要功能
-
• 语音识别 (ASR):在AISHELL-1上字错误率(WER)仅 0.60%,优于 Whisper 和 Paraformer -
• 多任务音频理解:声音分类、情感识别、音频问答任务,表现出色 -
• 端到端语音对话:支持情绪、口音、语速等个性化控制 -
• 高效流式生成:使用 BigVGAN 声码器和分块流机制(look-ahead),延迟低至毫秒级 -
• 开源评估工具包:Kimi-Audio-Evalkit 提供标准化评估,覆盖 ASR、AQA、SER 等任务
快速部署
Kimi-Audio 提供 Docker 和本地部署两种方式。
本地部署
1、克隆项目
git clone https://github.com/MoonshotAI/Kimi-Audio
cd Kimi-Audio2、安装依赖
pip install -r requirements.txtDocker 部署
1、构建镜像
docker build -t kimi-audio:v0.1 .或使用预构建镜像
docker pull moonshotai/kimi-audio:v0.12、运行容器
docker run -it --gpus all kimi-audio:v0.1使用方法
1、加载模型
import soundfile as sf
from kimia_infer.api.kimia import KimiAudio
# --- 1. 加载模型 ---
model_path = "moonshotai/Kimi-Audio-7B-Instruct"
model = KimiAudio(model_path=model_path, load_detokenizer=True)
# --- 2. 设置采样参数 ---
sampling_params = {
"audio_temperature": 0.8,
"audio_top_k": 10,
"text_temperature": 0.0,
"text_top_k": 5,
"audio_repetition_penalty": 1.0,
"audio_repetition_window_size": 64,
"text_repetition_penalty": 1.0,
"text_repetition_window_size": 16,
}2、语音识别(ASR)- 示例
# --- 3. Example 1: Audio-to-Text (ASR) ---
messages_asr = [
# You can provide context or instructions as text
{"role": "user", "message_type": "text", "content": "Please transcribe the following audio:"},
# Provide the audio file path
{"role": "user", "message_type": "audio", "content": "test_audios/asr_example.wav"}
]
# Generate only text output
_, text_output = model.generate(messages_asr, **sampling_params, output_type="text")
print(">>> ASR Output Text: ", text_output) # Expected output: "这并不是告别,这是一个篇章的结束,也是新篇章的开始。"3、语音对话 – 示例
# --- 4. Example 2: Audio-to-Audio/Text Conversation ---
messages_conversation = [
# Start conversation with an audio query
{"role": "user", "message_type": "audio", "content": "test_audios/qa_example.wav"}
]
# Generate both audio and text output
wav_output, text_output = model.generate(messages_conversation, **sampling_params, output_type="both")
# Save the generated audio
output_audio_path = "output_audio.wav"
sf.write(output_audio_path, wav_output.detach().cpu().view(-1).numpy(), 24000) # Assuming 24kHz output
print(f">>> Conversational Output Audio saved to: {output_audio_path}")
print(">>> Conversational Output Text: ", text_output) # Expected output: "A."
print("Kimi-Audio inference examples complete.")运行评估工具包
1、克隆 Evalkit
git clone https://github.com/MoonshotAI/Kimi-Audio-Evalkit
cd Kimi-Audio-Evalkit
pip install -r requirements.txt2、运行 ASR 评估
python almeval/datasets/ds_asr.py --model kimi-audio更多使用细则可参考项目文档或HF模型说明。
写在最后
Kimi Audio 是基于 Qwen 2.5-7B 构建的音频-文本多模态基础模型,它既能听懂,又能说话,而且理解深、表达自然、响应快。
具备语音识别(ASR)、音频理解(分类/情绪识别/问答)、端到端语音生成(TTS对话)等核心功能,真正把过去需要多个不同模型的能力,统一到一套模型架构之中!
是一款同时能听懂、听会、还能回答、还能说的超级音频模型,一步到位搞定音频所有需求。
比如用它做智能听写系统、语音版Chatbot、音频情绪检测之类的都是可以满足的。
GitHub 项目地址:https://github.com/MoonshotAI/Kimi-Audio
模型 HuggingFace:https://huggingface.co/moonshotai/Kimi-Audio-7B-Instruct

● 一款改变你视频下载体验的神器:MediaGo
● 新一代开源语音库CoQui TTS冲到了GitHub 20.5k Star
● 最新最全 VSCODE 插件推荐(2023版)
● Star 50.3k!超棒的国产远程桌面开源应用火了!
● 超牛的AI物理引擎项目,刚开源不到一天,就飙升到超9K Star!突破物理仿真极限!

(文:开源星探)