


极市导读
全面覆盖预训练,SFT,RL的极简自回归视觉生成框架。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 SimpleAR:纯自回归视觉生成:预训练 + SFT + RL
(来自复旦大学,ByteDance Seed)
1.1 SimpleAR 简介
1.2 自回归图像生成
1.3 三阶段训练策略
1.4 SimpleAR 推理
1.5 实验设置
1.6 实验结果
太长不看版
全面覆盖预训练,SFT,RL的极简自回归视觉生成框架。
SimpleAR 是一个全面覆盖预训练,SFT,RL的极简自回归视觉生成框架。
SimpleAR 仔细探索了训练和推理优化,证明了:
-
只需 0.5B 参数,SimpleAR 模型可以生成高保真 1024×1024 分辨率图像,并在一些有挑战性的 T2I benchmark (比如 GenEval,DPG) 取得有竞争力的结果,比如 GenEval 得分 0.59,DPG 得分 79.66 -
有监督微调 (SFT) 和 Group Relative Policy Optimization (GRPO) 训练可以显著提高生成结果的美学质量以及指令对齐的水平。 -
当使用 vLLM 等推理加速技术优化时,SimpleAR 生成 1024×1024 图像的时间可以减少到仅仅约 14s。

1 SimpleAR:纯自回归视觉生成:预训练 + SFT + RL
论文名称:SimpleAR: Pushing the Frontier of Autoregressive Visual Generation through Pretraining, SFT, and RL
论文地址:
http://arxiv.org/pdf/2504.11455
代码链接:
http://github.com/wdrink/SimpleAR
1.1 SimpleAR 简介
自回归 (Autoregressive, AR) 模型将视觉生成视为一个顺序的过程,即:每个像素或 token 都是基于前面的过程生成的。自回归过程很自然地擅长精确以及连贯的预测,使得它对于需要细粒度控制的任务特别有效。此外,AR 视觉生成模型自然地兼容不同模态的数据 (比如语言和音频),这有助于原生多模态理解和生成。
尽管自回归模型有这些优势,但目前自回归视觉模型做生成仍然不如扩散模型。具体来讲有这么几种解释。一个假设是离散视觉 tokenizer 对自回归生成质量带来了限制。另一个假设是视觉序列长度与文本相比更长,远程依赖建模会带来明显更多的挑战。
为了缓解这些问题,一些方法比如 MAR 和 VAR 试图解决视觉自回归的难题。尽管这些方法在一些 benchmark 上取得了有希望的结果,但它们损害了语言模型中 “next-token prediction” 的模式。
SimpleAR 的目标是通过保持自回归框架的简洁性,希望做好自回归视觉生成,同时通过预训练、监督微调 (SFT) 和基于 GRPO 的强化学习 (RL) 仔细优化此范式。
SimpleAR 表明仅仅 0.5B 参数的 vanilla AR 模型即可生成具有高美学的 1024×1024 分辨率的图像,并在现有的 T2I benchamrk 上取得有竞争力的结果,例如 GenEval 分数 0.59。当给更多的算力 (即参数量和 token) 进行缩放时,SimpleAR 始终可以提高生成质量,具体表现在更高的保真度和更连贯的结构。这些结果突出了自回归视觉生成与扩散模型竞争的潜力。
此外,作者还研究了使用 vLLM 和 speculative sampling 的自回归视觉生成模型的推理加速。当与 vLLM 部署时,SimpleAR 可以在大约 14s 的时间内生成 1024×1024 图像,展示了它在实际应用中的潜力。
1.2 自回归图像生成
SimpleAR 的目标是通过在优化 training pipeline 和推理效率的同时保持 AR 框架的简洁性,来进行自回归视觉生成。
SimpleAR 由一个预训练的 visual tokenizer 组成,它将 image 离散化为紧凑的视觉 tokens,还有一个 text tokenizer 和 decoder-only transformer,该 transformer 自回归建模文本和图像 token 的联合分布。与需要额外 text encoder 的 Diffusion Model 或之前的 AR 模型比如 LLamaGen 不同,SimpleAR 在统一的 Transformer 架构中集成了文本编码和视觉生成,在效率和多模态一致性方面都取得了显著的优势。
给定一个输入图像 ,首先使用预训练的 tokenizer 将其转化为一系列离散的视觉 token ,其中 表示压缩比。 中的每个 item 都表示 codebook 的 index,将一个 patch 映射到离散表征。然后,这些图像 token 按照光栅扫描排序,扁平化为一维序列
SimpleAR 还有一个 text tokenizer,将文本提示转换为文本 token 。之后,将文本和图像 token 沿序列维度连接起来,并将它们输入到 Transformer Decoder 中,以建模它们的依赖关系。
1.3 三阶段训练策略
为了提高生成质量和训练效率,SimpleAR 采用了三阶段学习范式:
-
对不同视觉数据集进行大规模预训练,以捕获高质量数据上的一般泛化性的模式。 -
监督微调 (SFT) 以增强保真度和指令跟随能力。 -
强化学习 (RL) 进一步细化多模态对齐并减轻 bias。
预训练和 SFT
在预训练和微调 (SFT) 期间,SimpleAR 使用语言建模损失进行训练:
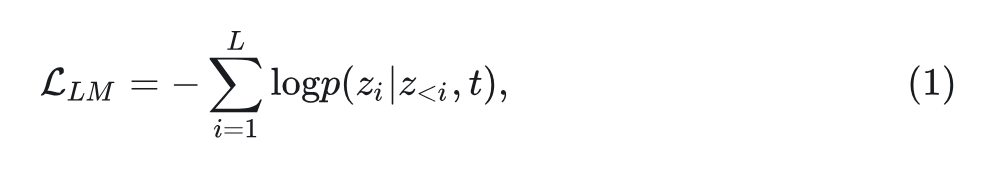
其中, 的预测以文本 token 及其之前的视觉 token 为 condition。
RL 与 GRPO
强化学习作为 LLM 的后训练范式,受到越来越多的关注,以提高推理能力。其也可以应用于 Diffusion Model[1][2],以更好地与人类偏好对齐。这些方法中,组相对策略优化 (Group Relative Policy Optimization, GRPO[3]) 通过提供更好的训练效率和稳定性已成为一种特别有前途的技术。
使用 SFT 后的 checkpoint,GRPO 初始化一个可训练的策略模型 和一个冻结的参考模型。对于给定的text prompt ,它从策略模型 中采样一组输出 ,并最大化以下目标以优化 :
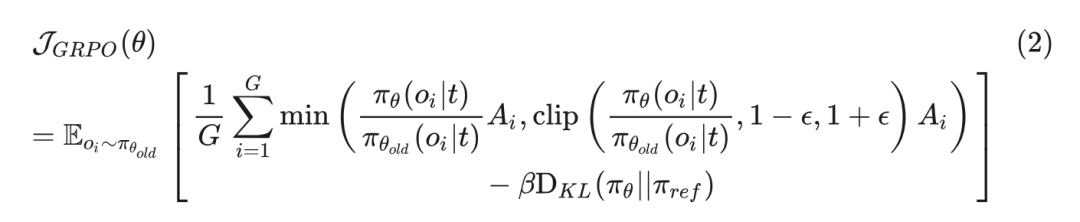
其中, 和 表示 clipping hyper-parameter 和控制 Kullback-Leibler(KL)惩罚的系数, 是在一个组中计算的优势。采用 CLIP 作为 reward,发现它在实验中非常有用。
1.4 SimpleAR 推理
在推理过程中,SimpleAR 通过这个条件概率依次对视觉 token 进行采样: $\hat{z_i}=\operatorname{argmax} p_\theta\left(z_i \mid z_{<i}, t\right)$=”” 。然后将采样的=”” token=”” 输入到=”” visual=”” tokenizer=”” 的解码器以生成图像。除非另有说明,否则贪婪搜索使用=”” top=”” $k=”64000$(codebook” 大小)。simplear=”” 还使用无分类器指导(classfier-free=”” guidance,cfg)来提高生成质量。<=”” p=””>
推理加速
由于自回归 (Autoregressive, AR) 模型中的 token 预测必须按顺序执行,因此推理延迟可能是一个重大瓶颈。
好在,LLM 社区已经开发了各种优化用于推理加速,如 KV cache 和 paged attention,为这个问题提供了有前景的解决方案。SimpleAR 探索了这些技术的应用来加速基于 AR 的视觉生成。
KV Cache 从注意力层存储先前计算的 key-value embeddings,并在自回归解码步骤中重用它们以减少冗余计算。它广泛应用于 LLM 推理,可以将复杂度从 降低到 。
vLLM Serving 利用优化的内存管理和高效的注意力机制,例如 paged attention,以实现现代硬件上自回归模型的高吞吐量和低延迟推理。
Speculative Jacobi Decoding 通过从 draft model 中对多个候选 token sequences 进行采样来加速自回归生成,然后使用 target model 来高效地验证它们。作者使用预训练的 AR 模型作为 draft model 和 target model 来进行加速。
1.5 实验设置
Transformer 模型采用与 Qwen 相同的架构,并用 LLM 权重初始化。visual tokenizer 使用 Cosmos-Tokenizer,其 codebook 大小为 64K,下采样比为 16。
训练包括 3 个阶段:1) 512 分辨率预训练。2) 1024 分辨率 SFT。3) 1024 分辨率 RL。在预训练 / SFT 期间,学习率设置为 1e-4 / 2e-5,batch size 为 256。RL 训练采用 trl 框架进行,学习率为 1e-5,batch size 为 28。在每个阶段不使用 warm up 和 learning rate decay。AdamW 优化器用于优化。所有实验均在 32 个 NVIDIA A100 GPU 上进行。
训练数据
预训练数据包括 CC3M、CC12M、OpenImages、SAM1B 和 Megaith-huggingface (总共约 43M)。
SFT 数据使用 JourneyDB、Synthetic dataset-1M 和 10M 内部数据。
对 SFT 采用一种简单的数据过滤策略,删除短边小于 1024 像素的所有图像。使用 Qwen2-VL recaption 所有图像,并在训练期间从长提示和短提示中随机选择。
1.6 实验结果
图 2 展示了 SimpleAR 和现有的最先进的视觉生成模型之间的比较。值得注意的是,在只有 0.5B 参数的情况下,SimpleAR 在 t2i 基准上实现了卓越的性能,即 GenEval 上的 0.59 的分数和 DPG-Bench 上的 79.66 得分,大大优于参数量相当的方法 (参数少于 1B 的方法)。包括基于 Diffusion 的方法 (例如 SDv2.1) 和自回归替代方案(例如 LlamaGen)。值得注意的是,Diffusion Model 还需要辅助 text encoder (例如,具有 3B 参数的 Flan-T5-XL),这也会增加参数,但 SimpleAR 使用 unified transformer 处理两种模态,参数利用更加高效,而且自然地支持条件生成。
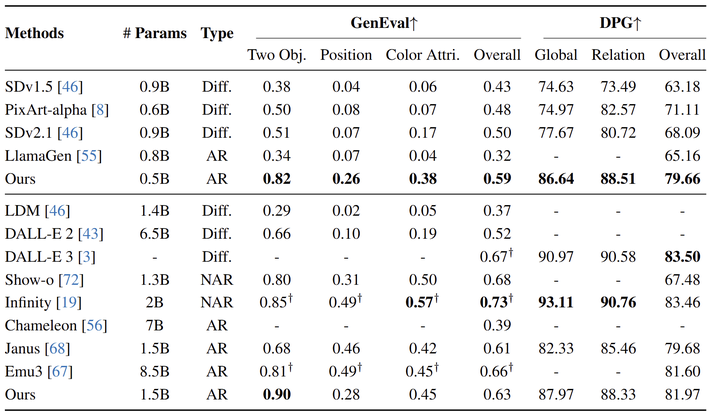
将 SimpleAR 缩放到 1.5B 会进一步改进文生图性能 (GenEval +0.04,DPG-Bench +1.85),展示出类似 LLM 的可预测的缩放行为。尽管 SimpleAR 在 GenEval 上仍然落后于 Infinity,但这一差距可能是由于训练数据量的差异,并且可以通过数据缩放缩小。
RL 消融实验
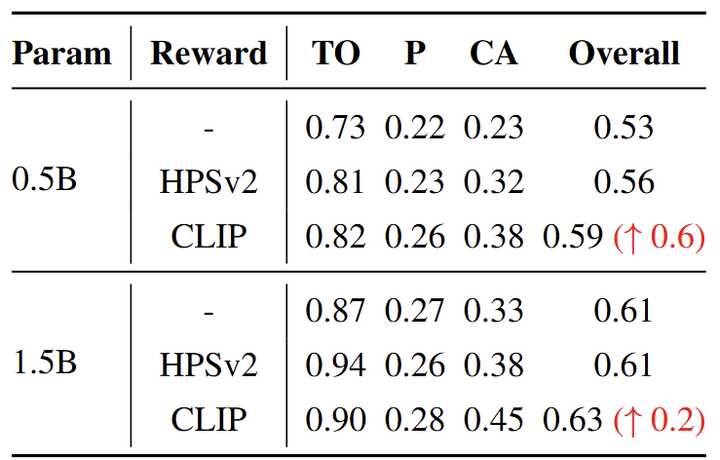
对于基于 GRPO 的强化学习,作者比较了 2 种不同的 reward module:CLIP-ViT-H-14 和 HPSv2。值得注意的是,HPSv2 是 CLIP-ViT-H-14 的微调版本,在专门设计的人类偏好数据集上进行训练。GenEval 性能在图 3 中定量比较,观察到使用两个奖励模块可以提高性能,而且 CLIP 奖励模型实现了更高的性能增益,0.5B 模型的 GenEval 提高了 +0.6。定性结果如图 4 所示,进一步表明 CLIP 可以增强文本渲染能力,并提高对量词和空间描述的感知。

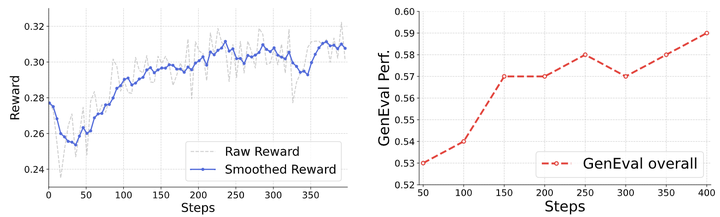
作者绘制了奖励值和 GenEval 性能,如图 5 所示。从左侧可以看出,奖励值在训练期间表现出逐渐增加。有趣的是,GenEval 性能与奖励进展呈正相关,这表明一个简单的奖励函数,即 CLIP-ViT-H-14,可以有效地提供与所需任务性能很好地对齐的一致反馈。
推理速度
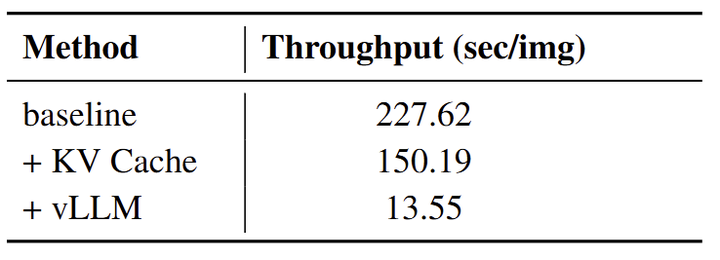
自回归模型的顺序预测性质可能会导致高推理延迟,使得实时应用程序中部署中很有挑战性。然而,LLM 优化技术的最新进展,如 KV cache, paged attention, 和 speculative decoding,为加速 AR 视觉生成模型推理提供了机会。作者实验应用这些方法来加速 SimpleAR 的推理。吞吐量是在 Nvidia A100 节点上计算的,启用 CFG。
图 6 表明,使用 KV cache 可以有效地节省 34% 的推理时间,而使用 vLLM 服务会导致更多的显着推理加速,将生成 1024×1024 图像的时间减少到 13.55s。
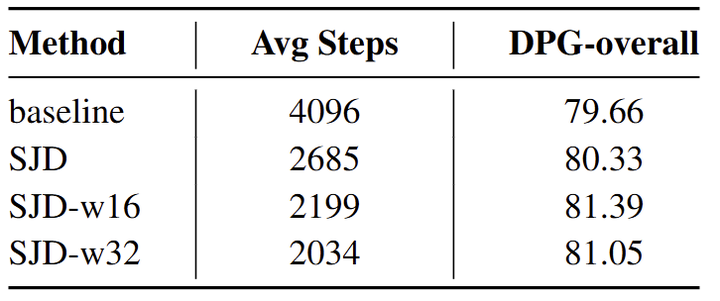
作者还尝试了 speculative jacobi decoding (SJD),它在推理时推测并行解码多个 token 以减少自回归生成步骤。结果如图 7 所示,可以看到 SJD 可以在步骤减少约 2×,在 DPG 上的性能略好。作者还比较了 sliding-window 设计。尽管 SJD 实际上并没有降低自回归模型的测试延迟 (无法使用 KV cache,每次需要转发整个序列),但它仍然为优化 AR 推理过程提供了许多可能性。
作者在图 8 和图 9 中可视化了 SimpleAR 的图像生成结果。可以观察到,SimpleAR 不仅可以生成高保真、美观的图像,还可以表现出强大的指令跟随能力。


图 10 还显示了几个失败案例。有限的数据规模和参数大小约束 SimpleAR 生成复杂的姿势、对象和文本的能力。此外,SimpleAR 可以合成不符合物理定律的内容。

参考
-
Aligning Text-to-Image Models using Human Feedback -
Diffusion Model Alignment Using Direct Preference Optimization -
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models

(文:极市干货)